The Definitive 2026 Guide to Optimizing Brand Visibility in AI Search
Generative Engine Optimization (GEO) is the process of improving how generative AI systems mention, evaluate, compare, cite, and recommend a brand inside AI-generated answers.
Traditional SEO focuses on helping web pages rank in search engine results pages. GEO focuses on helping brands appear inside answers generated by AI systems such as ChatGPT, Gemini, Claude, Perplexity, Copilot, and other AI search experiences.
This shift matters because users are no longer only clicking through lists of blue links. They are asking AI systems for direct recommendations, comparisons, summaries, and buying guidance. In many cases, the AI answer becomes the decision layer.
If your brand ranks on Google but is not mentioned in AI-generated answers, your visibility problem may no longer appear in traditional analytics. You may still receive impressions and rankings, but lose influence when AI systems summarize the market.
That is why GEO is becoming a critical discipline for SaaS companies, B2B brands, agencies, publishers, and any business that depends on digital discovery.
I. What Is Generative Engine Optimization?
Generative Engine Optimization is the strategic practice of improving a brand’s visibility, credibility, and positioning inside AI-generated responses.
In simple terms, GEO answers questions like:
- Does ChatGPT mention your brand?
- Does Gemini cite your website?
- Does Claude describe your company accurately?
- Does Perplexity include your content as a source?
- Do AI systems recommend your competitors instead of you?
- Is your brand framed as a leader, a niche option, or not mentioned at all?
GEO is not only about being discovered. It is about being represented correctly.
A brand can rank well on Google and still be invisible in AI search. This happens because AI systems do not behave exactly like traditional search engines. They synthesize information, compress sources, interpret entity relationships, and produce direct answers.
In the SEO era, visibility was often measured by position. In the AI era, visibility is increasingly measured by inclusion.
The main question changes from:
“Where do we rank?”
to:
“Are we included in the answer?”
II. Why GEO Matters in 2026
AI search is changing how people discover information, compare solutions, and evaluate brands.
When users search on Google, they usually see multiple pages, titles, snippets, and links. When users ask an AI assistant, they often receive one synthesized response. That response may include only a few recommended brands, tools, or sources.
This creates a new visibility bottleneck.
For example, a user may ask:
- “What are the best AI SEO tools?”
- “Which tools help monitor brand mentions in ChatGPT?”
- “What are the best platforms for AI search visibility?”
- “How can I track whether AI mentions my competitors?”
- “What is the difference between GEO and SEO?”
If your brand is not included in those answers, you are absent from a high-intent discovery moment.
This matters especially for B2B and SaaS categories, where buyers use AI tools to summarize markets before visiting websites. AI-generated answers can shape perception before a prospect ever reaches your homepage.
GEO helps brands understand and improve:
- AI answer inclusion
- Brand mention frequency
- AI citation visibility
- Competitive share of voice
- Sentiment and positioning
- Category association
- Entity clarity
- Prompt coverage
In short, GEO helps brands compete inside AI-generated decision journeys.
III. GEO vs SEO
SEO and GEO are connected, but they are not the same.
SEO improves how web pages perform in search engines. GEO improves how brands and content are represented in AI-generated answers.
| Dimension | SEO | GEO |
|---|---|---|
| Main output | Ranked web pages | Synthesized AI answers |
| Main goal | Rank higher in search results | Be included, cited, and recommended |
| Visibility model | Position-based | Mention-based |
| Core metric | Keyword ranking | Mention frequency and prompt coverage |
| Optimization target | Pages and queries | Entities, prompts, sources, and answer patterns |
| Competitive unit | Websites | Brands inside AI answer sets |
| Key signals | Content, backlinks, technical SEO, UX | Entity clarity, authority footprint, source consistency, topical relevance |
| User behavior | Clicks through results | Reads summarized answers |
SEO is still important. Strong SEO can support GEO because AI systems often rely on web content, structured information, reputable sources, and clear entity signals.
However, ranking on Google does not guarantee inclusion in AI answers.
A page can rank well and still be ignored by an AI system if the brand lacks entity clarity, category consistency, authoritative mentions, or source-level trust.
The better way to think about it is this:
SEO helps you compete for clicks.
GEO helps you compete for presence inside answers.
Both are now part of modern search visibility.
IV. How Generative AI Systems Produce Answers
Generative AI systems produce answers by interpreting prompts and generating responses based on patterns learned from large datasets. Some systems also use retrieval-augmented generation, which allows them to retrieve information from external sources before generating a response.
A simplified process looks like this:
- The user enters a prompt.
- The AI system interprets the intent.
- The model identifies relevant concepts, entities, and relationships.
- If retrieval is enabled, the system may pull information from external sources.
- The AI generates a synthesized response.
- The response may mention, compare, recommend, or cite brands.
This is very different from a traditional search engine results page.
There is no stable list of 10 blue links. There is no visible ranking table. There is no single fixed position that a brand can track across all users and prompts.
AI visibility is probabilistic. It can change depending on:
- The wording of the prompt
- The model being used
- The retrieval sources available
- The location and language of the user
- The freshness of indexed information
- The strength of competing entities
- The clarity of your brand positioning
That is why GEO requires prompt-level testing instead of keyword tracking alone.
If SEO asks, “What keyword do we rank for?”
GEO asks, “Which prompts include us, exclude us, cite us, or recommend someone else?”
V. The Core Pillars of GEO
A strong GEO strategy is built on five core pillars.
1. Entity Strength
Generative AI systems need to understand what your brand is, what category it belongs to, and why it matters.
Entity strength depends on how consistently your brand is described across the web.
A strong entity has:
- A clear brand name
- A consistent category description
- A well-defined problem space
- A recognizable product or service function
- Structured data
- Consistent profiles across trusted platforms
- Clear associations with relevant topics
For example, if a company describes itself as an “AI visibility platform” on its website, a “brand monitoring tool” on directories, and a “SEO analytics product” on social media, AI systems may struggle to classify it precisely.
Ambiguity reduces inclusion probability.
Clear category language increases the chance that AI systems understand when your brand is relevant.
2. Authority Footprint
AI systems tend to reflect signals from the broader digital ecosystem.
A brand with a stronger authority footprint is more likely to be recognized, compared, cited, and recommended.
Authority footprint may include:
- High-quality website content
- Industry articles
- SaaS directory listings
- Third-party reviews
- Research reports
- Expert mentions
- Digital PR
- Backlinks from reputable sources
- Consistent brand references across trusted domains
Authority does not come from one page alone. It comes from repeated, reliable, and contextually relevant signals across the web.
For GEO, your brand should not only publish content. It should become part of the category conversation.
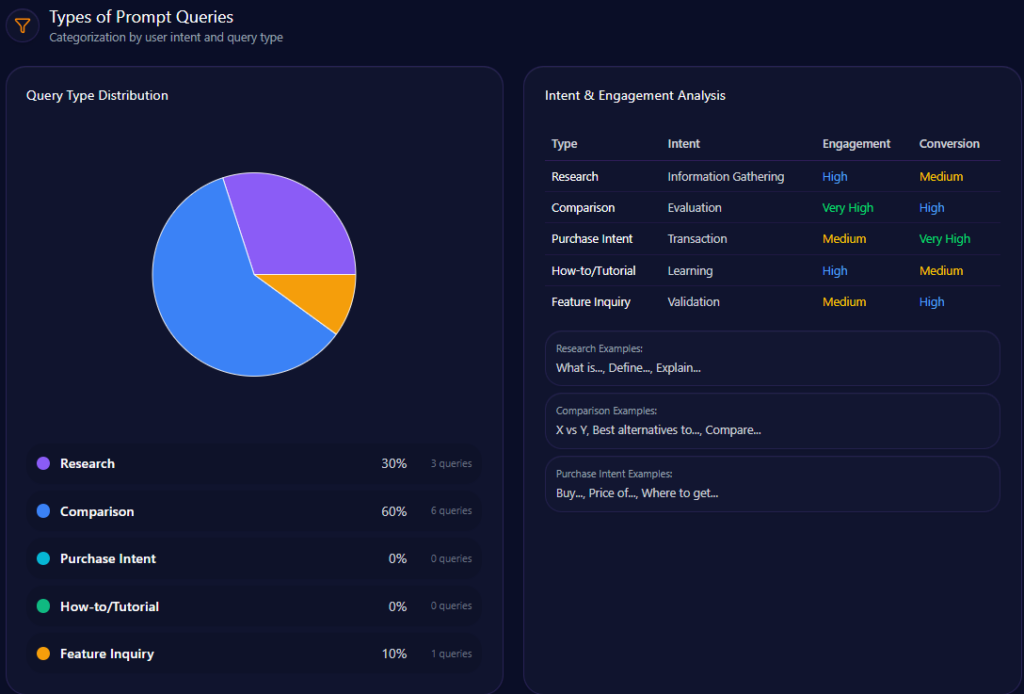
3. Prompt Coverage
Traditional SEO tracks keywords.
GEO tracks prompts.
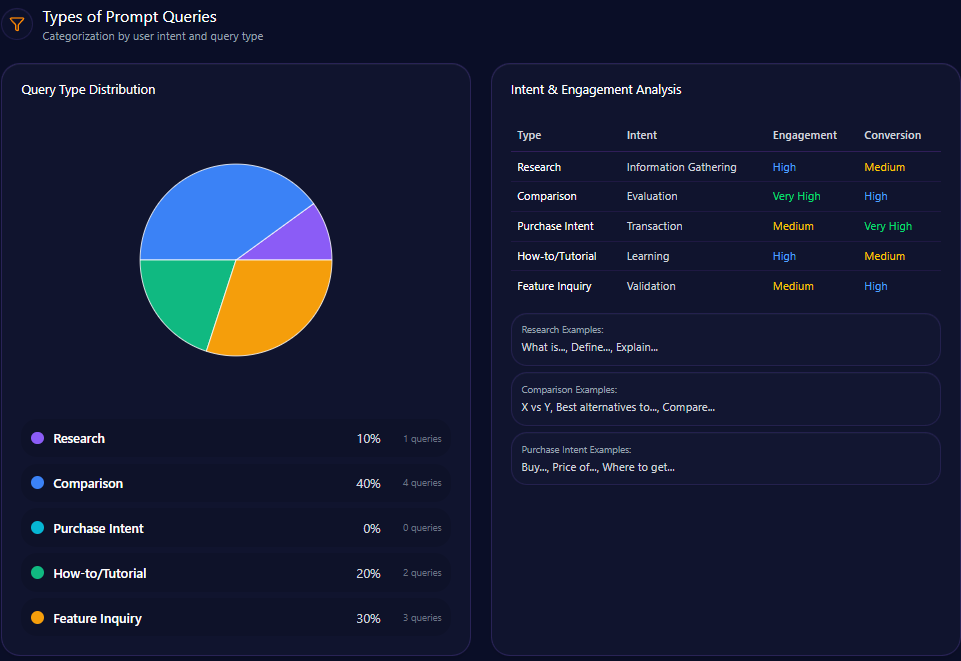
A prompt is not always the same as a keyword. A prompt may contain a full problem, scenario, comparison, or decision request.
Examples include:
- “What are the best tools for tracking ChatGPT brand mentions?”
- “How do I know if AI search is recommending my competitors?”
- “Which platforms help monitor AI visibility?”
- “How can a SaaS company optimize for generative engines?”
- “What is the difference between GEO and traditional SEO?”
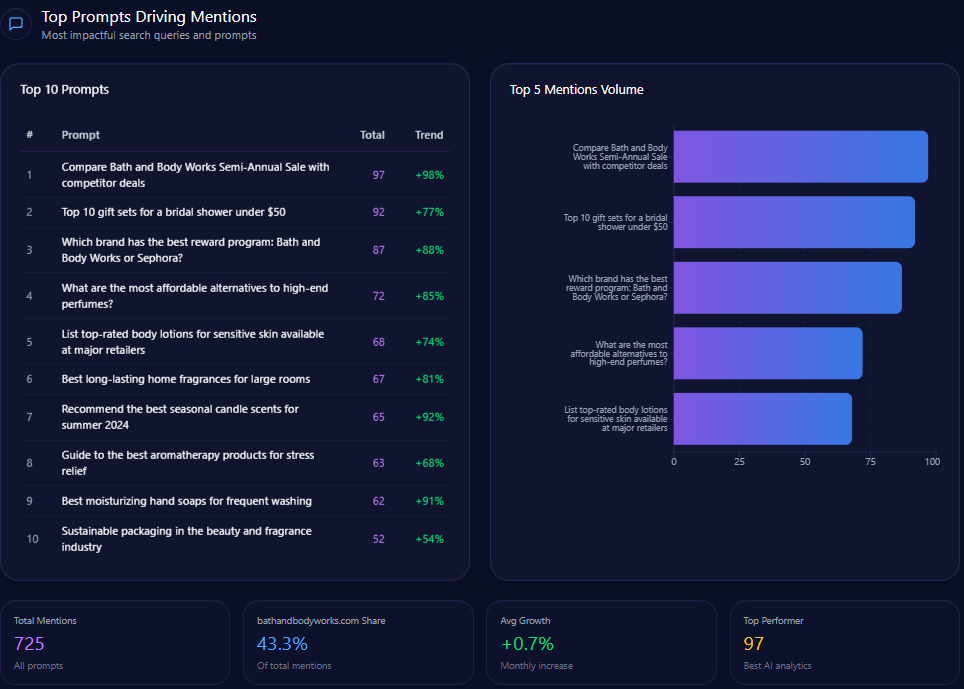
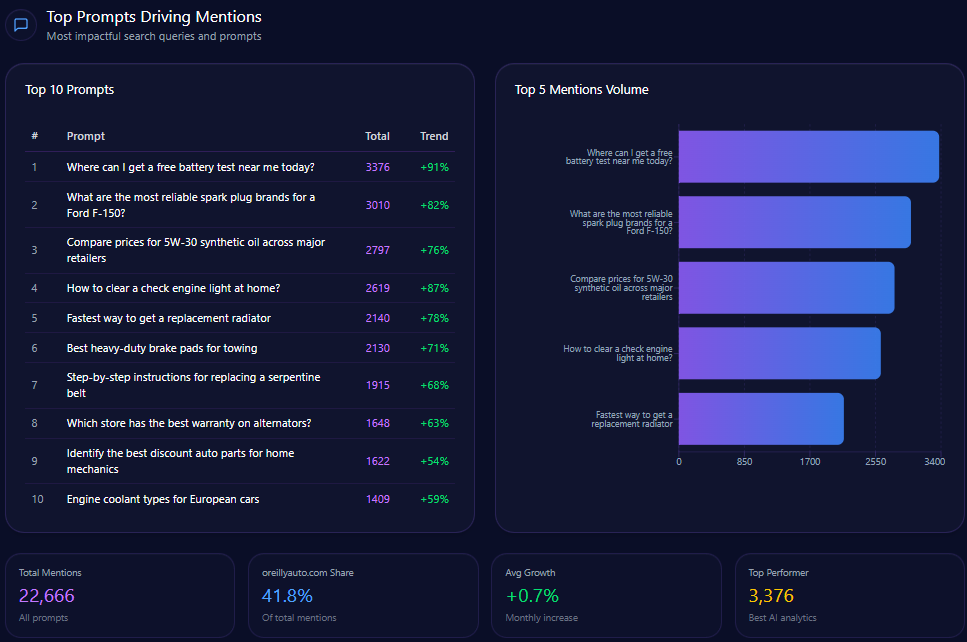
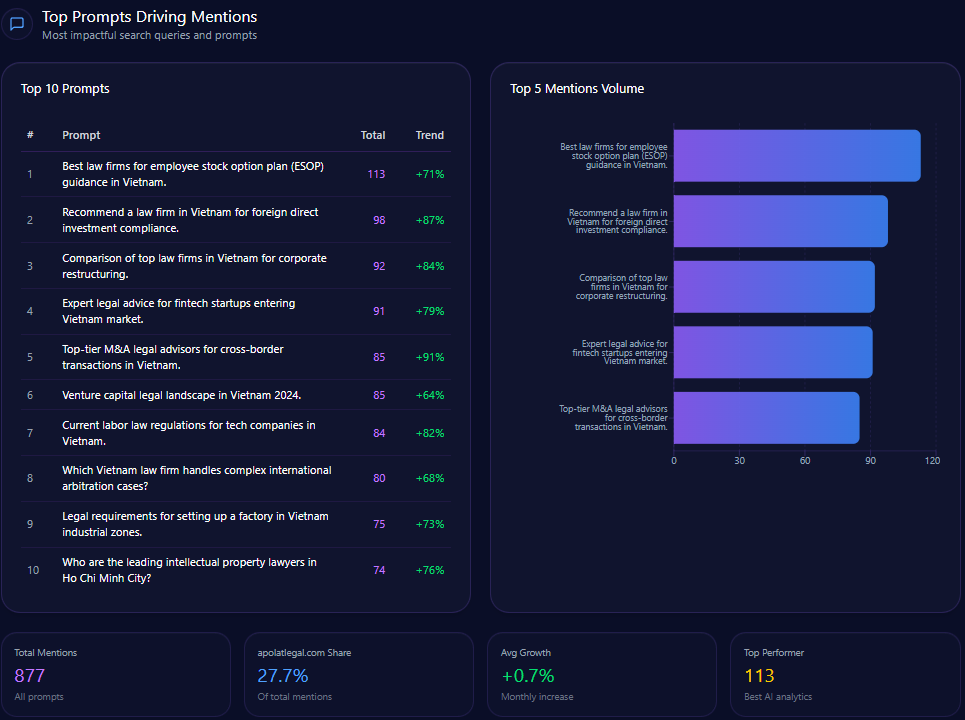
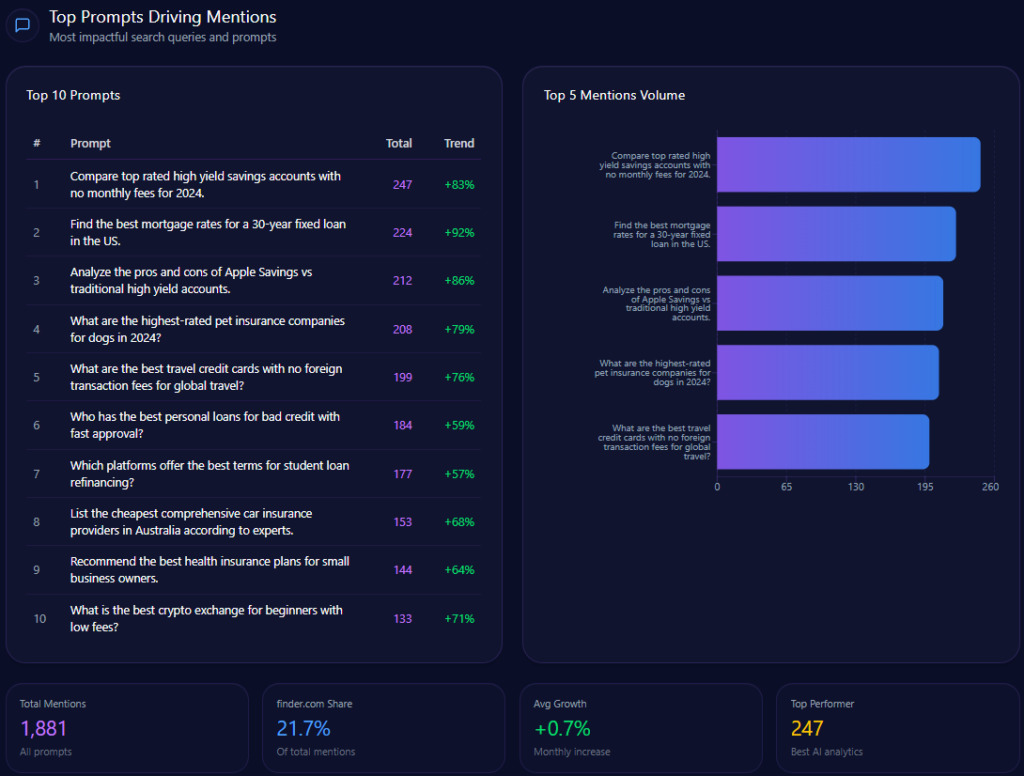
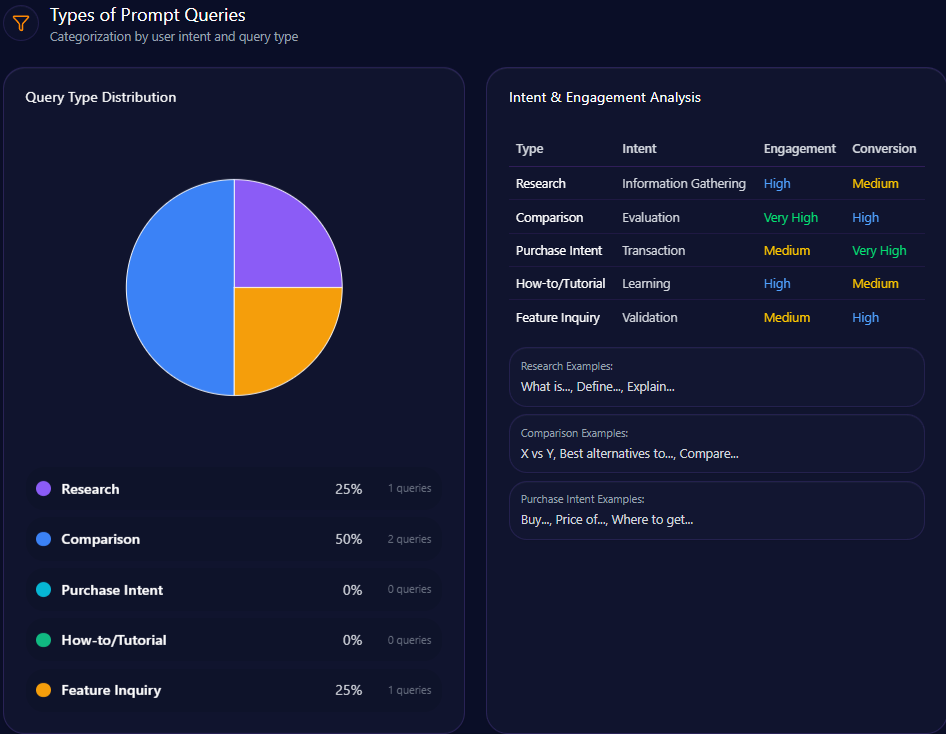
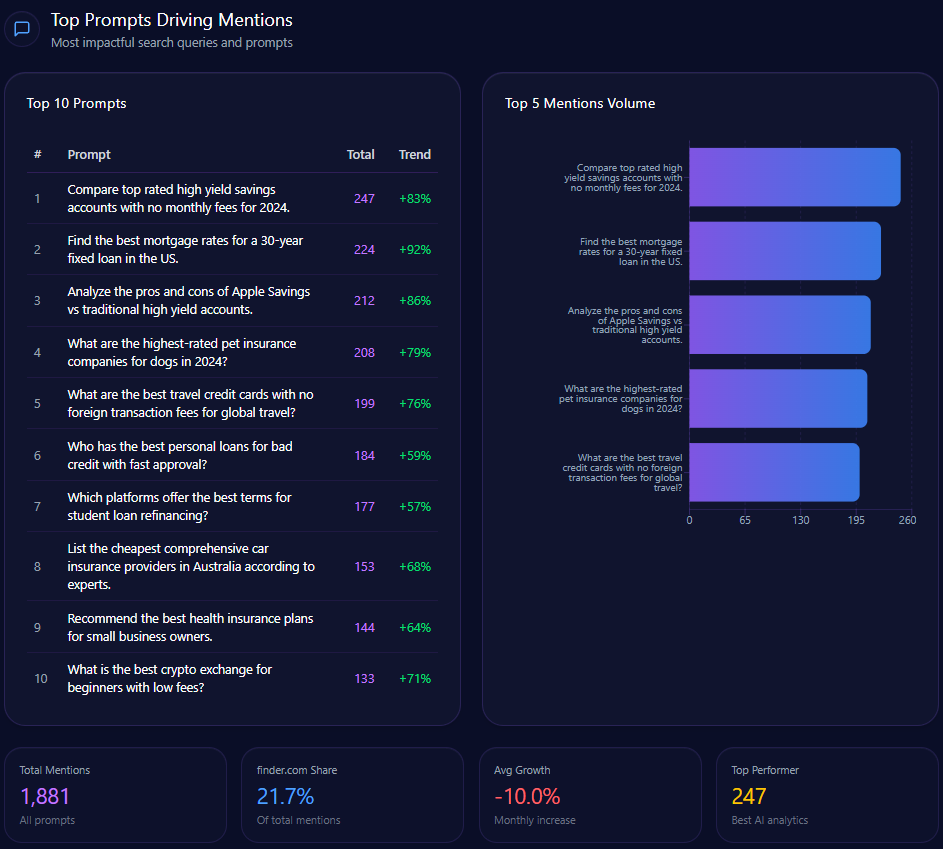
Prompt coverage measures how often your brand appears across a defined set of prompts.
If your brand appears in 12 out of 100 important prompts, your prompt coverage rate is 12%.
This makes GEO measurable.
Instead of guessing whether AI systems understand your brand, you can test prompts, collect outputs, and track visibility over time.
4. Citation and Source Inclusion
Some AI systems provide citations, references, or source links.
When this happens, GEO becomes directly connected to source visibility.
The key questions are:
- Is your website cited?
- Are your competitors cited instead?
- Which pages are used as sources?
- Are third-party pages describing your brand accurately?
- Are AI systems citing outdated information?
- Are AI answers using your content without sending traffic?
Citation inclusion is important because citations can influence trust. When a user sees your brand or website referenced in an AI answer, it strengthens perceived authority.
5. Sentiment and Positioning
Being mentioned is not enough.
The way your brand is described matters.
AI systems can frame your brand as:
- Innovative
- Enterprise-ready
- Beginner-friendly
- Expensive
- Limited
- Niche
- Outdated
- Less established than competitors
This framing can influence user perception before they ever visit your website.
For example, if an AI answer says your competitor is “best for enterprise teams” while your brand is “a newer option,” that creates a positioning gap.
GEO must track not only whether your brand appears, but how it appears.
VI. How LLMs Decide Which Brands to Mention
No public source provides a complete ranking formula for how every AI system selects brand mentions. However, observable patterns suggest that several factors influence inclusion.
These include:
- Brand frequency across relevant sources
- Consistency of category association
- Strength of topical authority
- Presence in reputable publications
- Clarity of product positioning
- Content structure and answerability
- Third-party validation
- Freshness of available information
- Relevance to the user prompt
- Competitive prominence
For example, when a user asks for “best AI brand monitoring tools,” the AI system needs to determine which brands are strongly associated with AI brand monitoring.
If your website does not clearly explain that category, or if third-party sources do not connect your brand with that use case, your inclusion probability may be lower.
This is why GEO is not only a content problem. It is also an entity, authority, and distribution problem.
To improve AI visibility, brands need consistent signals across:
- Website pages
- Blog articles
- Product pages
- Comparison pages
- Help documentation
- Schema markup
- Social profiles
- Review platforms
- SaaS directories
- External publications
The goal is to make your brand easy for AI systems to understand, classify, and trust.
VII. GEO Metrics and Measurement Framework
GEO becomes useful when it is measured.
A strong GEO measurement framework should track the following metrics.
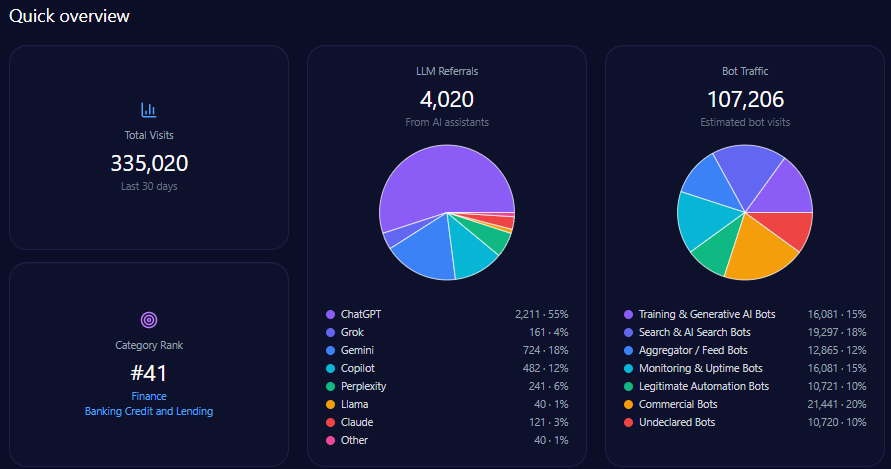
1. Mention Frequency
Mention frequency measures how often your brand appears across a selected prompt set.
For example, if you test 100 prompts and your brand appears in 18 answers, your mention frequency is 18%.
2. Prompt Coverage Rate
Prompt coverage measures the percentage of relevant prompts where your brand appears.
This is useful because different prompts reveal different visibility gaps.
A brand may appear for category-level prompts but disappear for competitor comparison prompts.
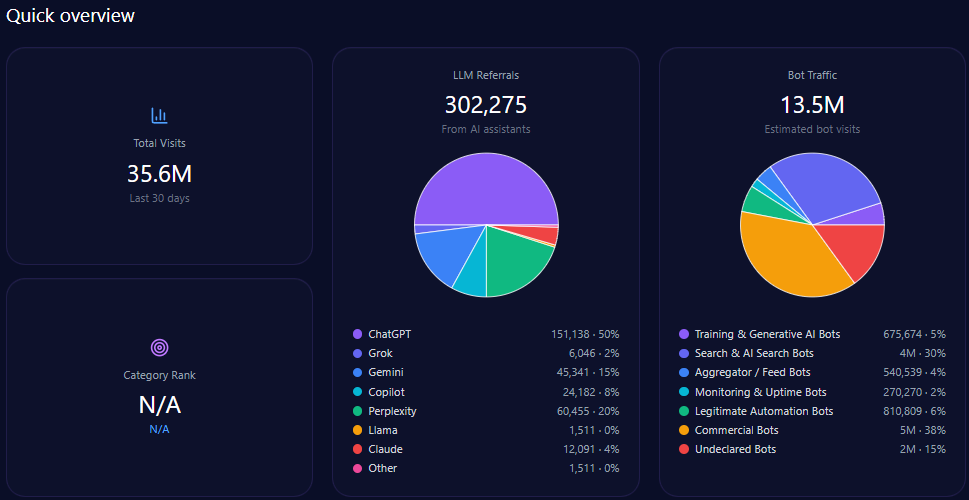
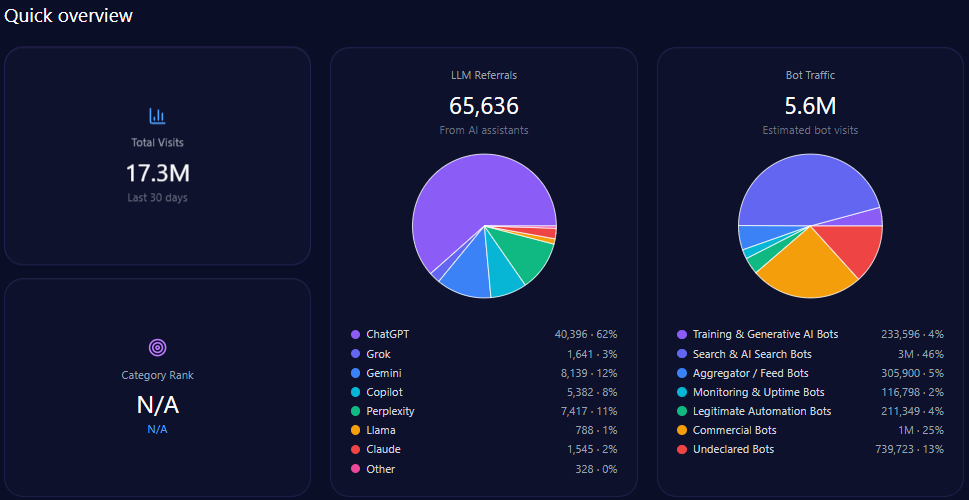
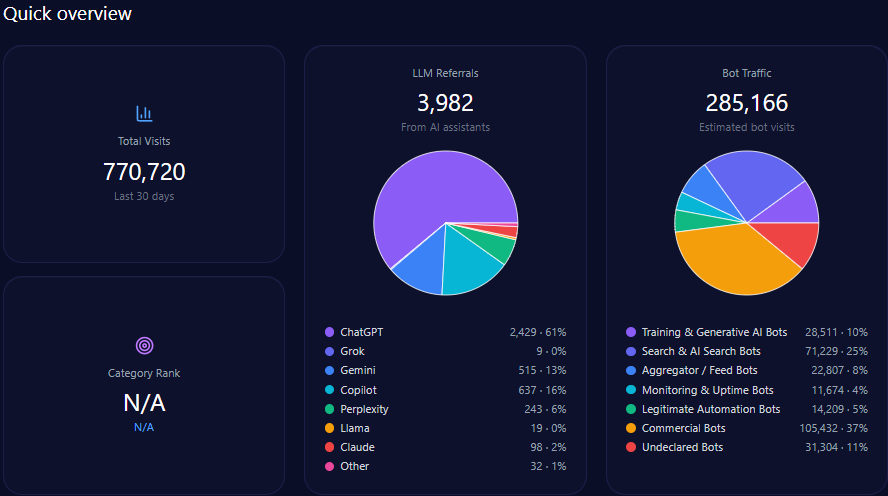
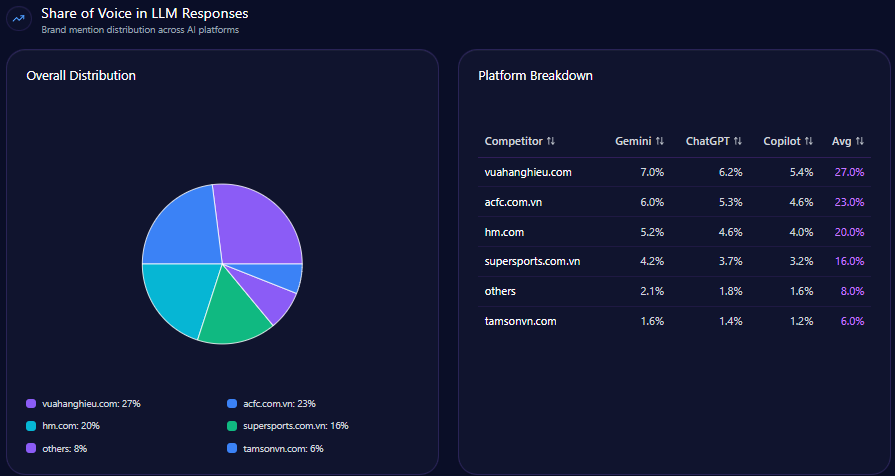
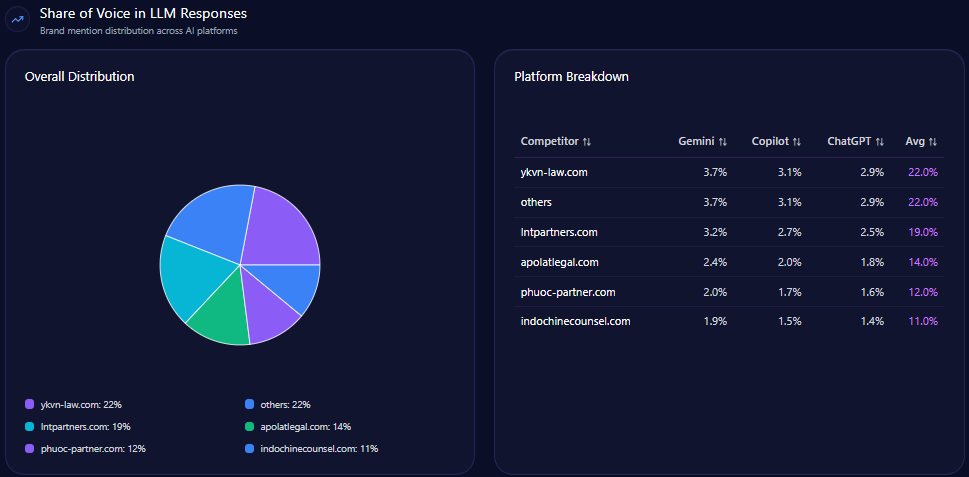
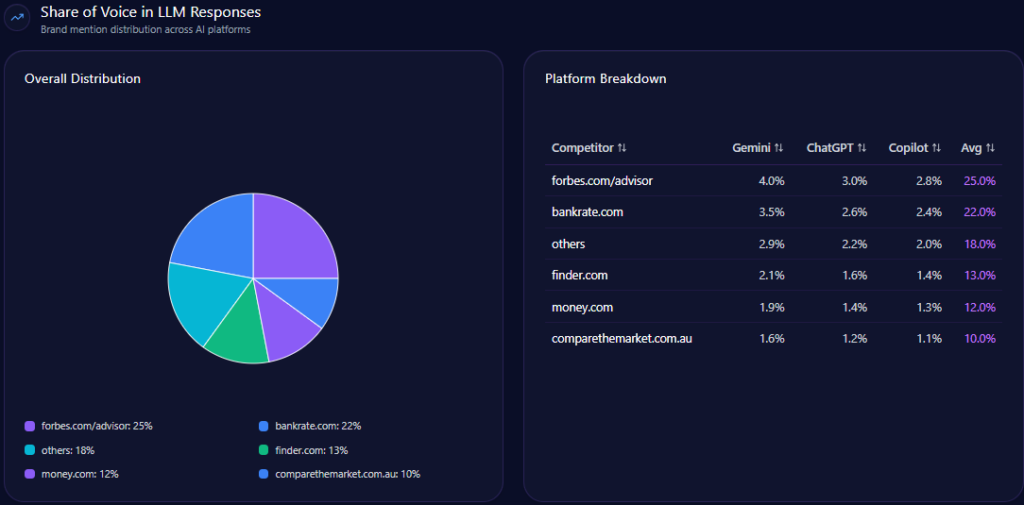
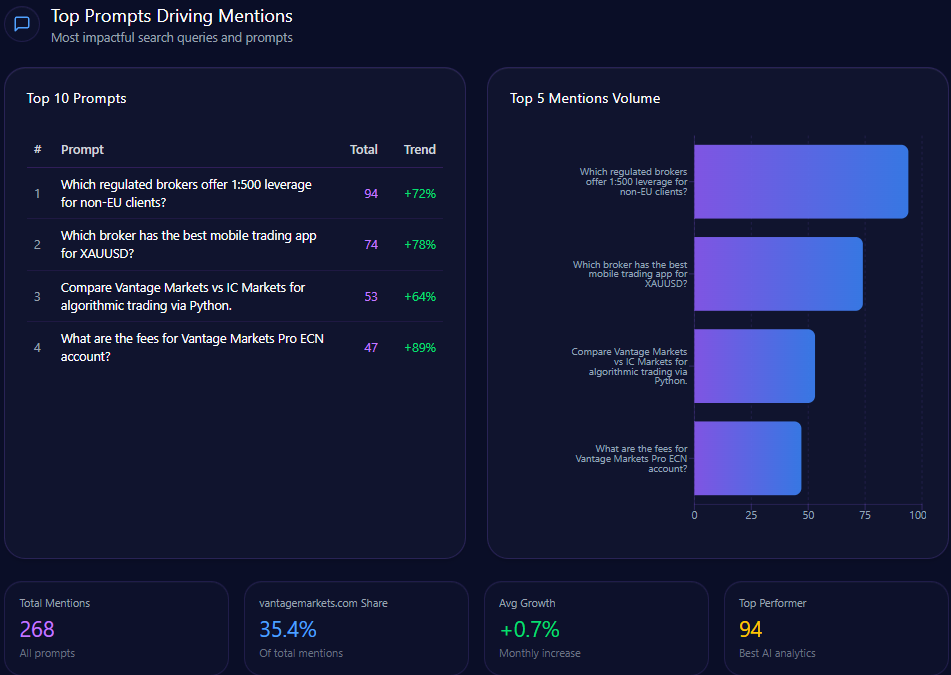
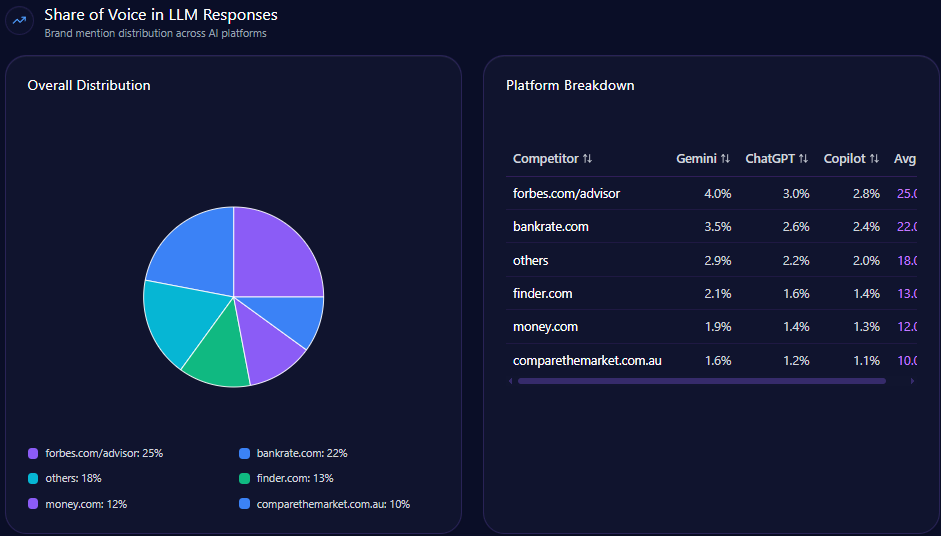
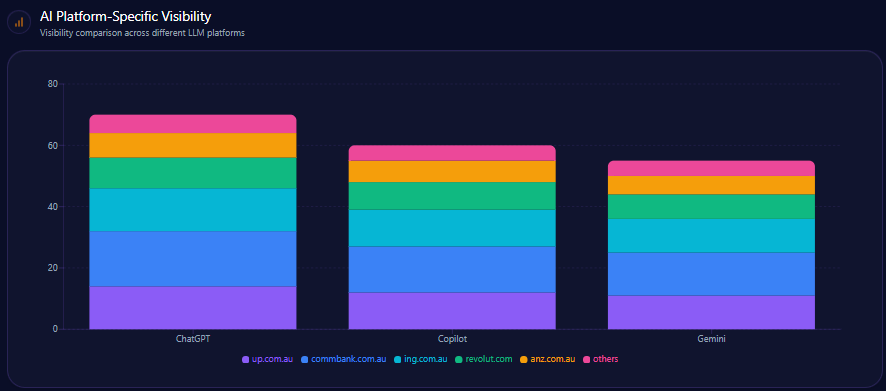
3. Share of Voice
Share of voice compares your brand’s mentions against competitors.
For example:
- Brand A: 35 mentions
- Brand B: 25 mentions
- Brand C: 18 mentions
- Your brand: 12 mentions
This shows whether your brand is leading, following, or absent in AI-generated recommendation sets.
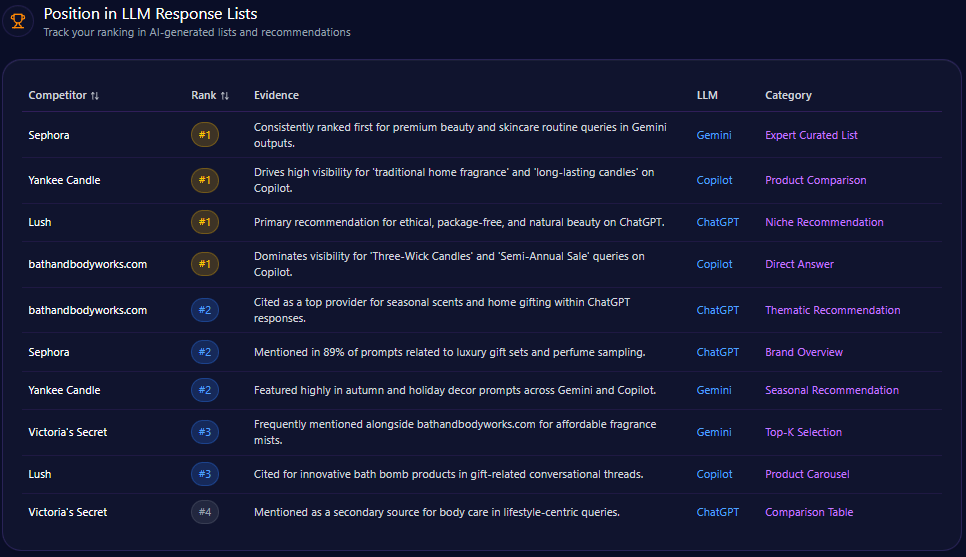
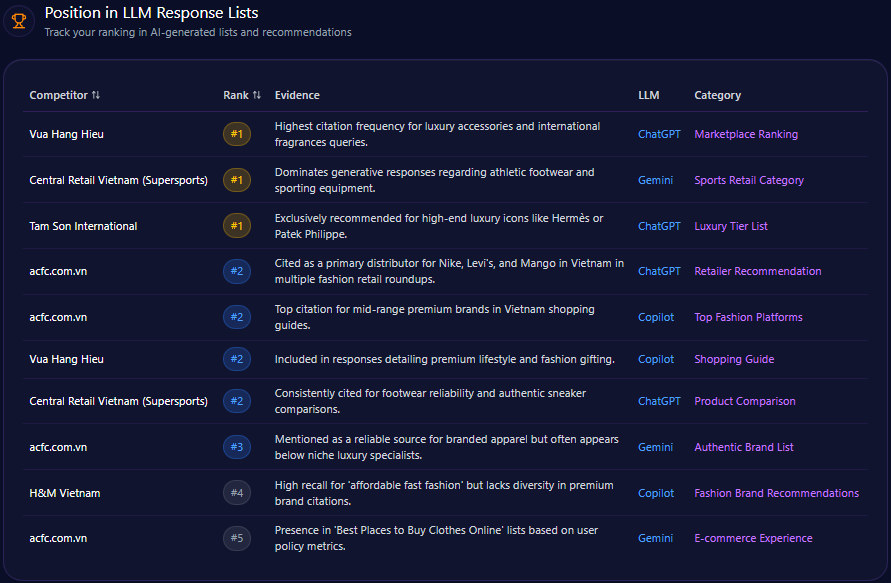
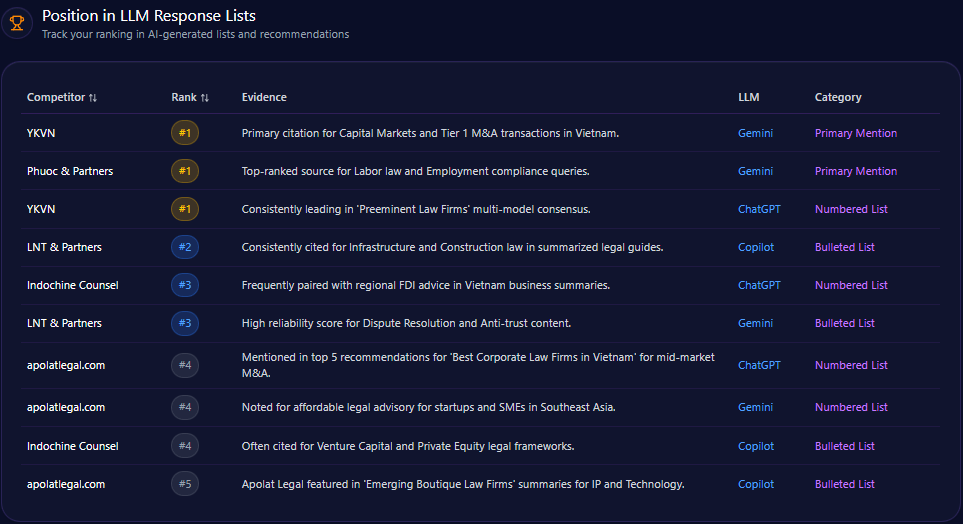
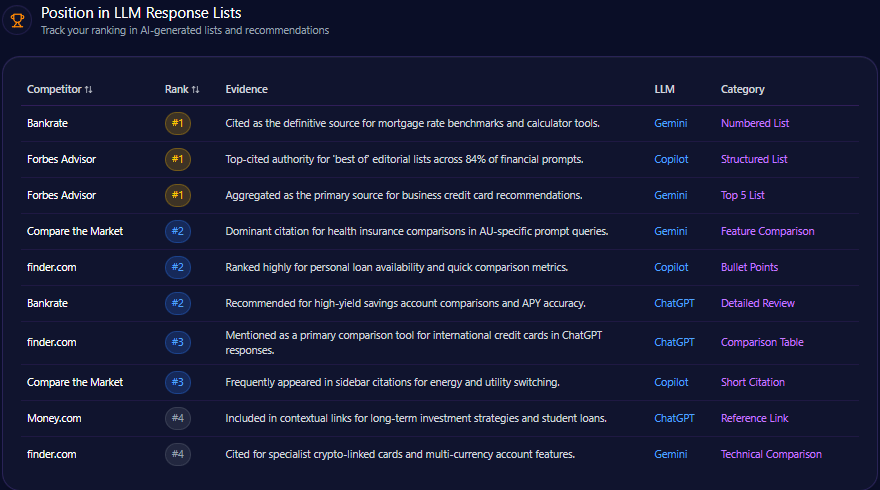
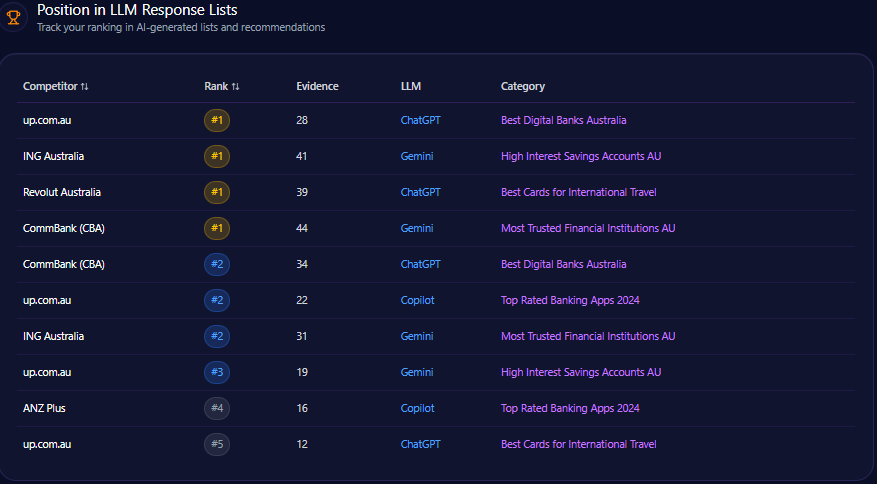
4. Recommendation Position
AI answers often list brands in order.
Recommendation position tracks where your brand appears when AI systems provide ranked or semi-ranked recommendations.
Being mentioned first is not the same as being mentioned last.
5. Citation Frequency
Citation frequency measures how often your website or content is cited as a source.
This is especially important for AI search platforms that display references.
6. Sentiment Score
Sentiment score evaluates whether your brand is described positively, neutrally, or negatively.
It also tracks positioning language, such as:
- Best for startups
- Best for enterprise teams
- Strong for technical users
- Good for beginners
- Less mature than competitors
7. Competitive Inclusion Gap
This metric identifies prompts where competitors appear but your brand does not.
These gaps are high-priority opportunities because they show where AI systems already understand the category but are excluding your brand.
Together, these metrics can form an AI Visibility Index.
An AI Visibility Index gives teams a structured way to monitor their presence across AI-generated answers.
VIII. Optimization Tactics for AI Visibility
GEO is not about trying to manipulate AI systems. It is about making your brand, content, and digital footprint easier to understand, verify, and recommend.
Here are practical tactics that can improve AI visibility.
1. Build a Clear Category Narrative
Your website should clearly answer:
- What category are you in?
- What problem do you solve?
- Who is the product for?
- What makes your approach different?
- Which alternatives are you compared against?
For SpyderBot, the category narrative should consistently connect to terms such as:
- GEO analytics
- AI search visibility
- LLM brand monitoring
- AI brand mention tracking
- Generative engine optimization tools
- AI competitor visibility tracking
The clearer the category narrative, the easier it is for AI systems to associate your brand with relevant prompts.
2. Publish Authoritative Definition Pages
Definition pages help both search engines and AI systems understand emerging categories.
A strong definition page should include:
- A concise definition
- A detailed explanation
- A comparison table
- Practical examples
- Metrics
- Implementation steps
- FAQ section
- Internal links to related pages
- External references to credible sources
This article is an example of a definition page built for the topic “Generative Engine Optimization.”
3. Strengthen Entity Consistency
Your brand description should be consistent across the web.
Check your:
- Homepage
- About page
- Product pages
- LinkedIn page
- X profile
- SaaS directories
- Review platforms
- Guest posts
- Press mentions
- Author bios
If each platform describes the brand differently, AI systems may receive conflicting signals.
A simple entity statement can help.
Example:
“SpyderBot is a GEO analytics platform that helps brands monitor how AI systems mention, compare, cite, and recommend them across generative search experiences.”
This type of statement should appear consistently across key brand assets.
4. Create Comparison and Alternative Pages
AI systems often answer comparison prompts.
Examples:
- “SpyderBot vs traditional SEO tools”
- “Best tools for AI search monitoring”
- “Alternatives to SEMrush for AI visibility”
- “AI brand monitoring tools for SaaS companies”
- “GEO analytics tools for tracking LLM mentions”
Comparison pages help AI systems understand your position in the market.
They also help users evaluate your product against alternatives.
The goal is not to attack competitors. The goal is to clarify category fit, use cases, strengths, and limitations.
5. Publish Data-Driven Research
Original data is powerful for GEO.
AI systems and human readers both value unique insights.
Examples of data-driven assets include:
- AI visibility benchmark reports
- Prompt coverage studies
- Industry share of voice reports
- ChatGPT brand mention studies
- Gemini citation analysis
- AI search competitor comparison reports
- LLM sentiment analysis by category
Original research can increase citations, backlinks, and authority signals.
It can also give AI systems more concrete information to reference.
6. Add Structured Data
Structured data helps search engines understand page type, organization details, breadcrumbs, FAQs, and article information.
For this article, useful schema types may include:
- Article
- Organization
- BreadcrumbList
- FAQPage, only if the FAQ content is visible on the page
Structured data does not guarantee indexing, but it improves machine readability.
7. Improve Internal Linking
Internal links help search engines understand topical relationships.
This article should link to related SpyderBot pages such as:
- ChatGPT brand monitoring tools
- AI brand mention tracking
- AI search analytics
- GEO analytics platform
- LLM brand monitoring software
- How to get mentioned in ChatGPT
- Why ChatGPT recommends competitors
Internal links should use descriptive anchor text.
Avoid generic anchors like “click here.”
Better anchors include:
- “AI brand mention tracking”
- “ChatGPT brand monitoring”
- “LLM visibility tracking”
- “AI search competitor monitoring”
8. Monitor and Update AI Visibility
GEO is not a one-time project.
AI systems change. Competitors publish new content. Search results shift. New citations appear. Old information becomes outdated.
A strong GEO process should include:
- Weekly prompt testing
- Monthly competitor tracking
- Quarterly content updates
- Regular entity consistency checks
- Ongoing citation monitoring
- Sentiment analysis
- Internal linking improvements
The brands that win in AI search will be the brands that monitor and adapt continuously.
IX. Competitive GEO Strategy
GEO is competitive by nature.
When an AI answer recommends five brands, every excluded brand loses visibility. When a competitor is cited and you are not, that competitor gains authority in the user’s decision process.
A competitive GEO strategy should include five steps.
1. Define High-Intent Prompt Clusters
Start by identifying prompts that matter to your business.
For example:
- “Best GEO tools”
- “Best AI search visibility platforms”
- “How to track ChatGPT brand mentions”
- “AI SEO tools for SaaS companies”
- “How to monitor AI recommendations”
- “Best tools for LLM brand analytics”
These prompts should reflect real buyer intent.
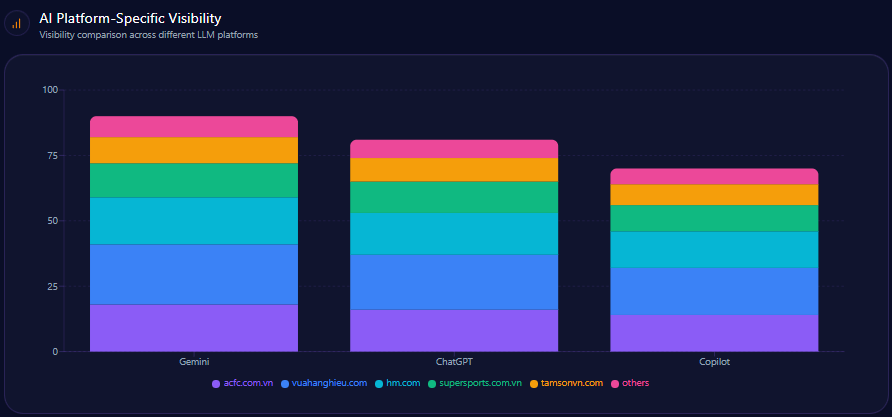
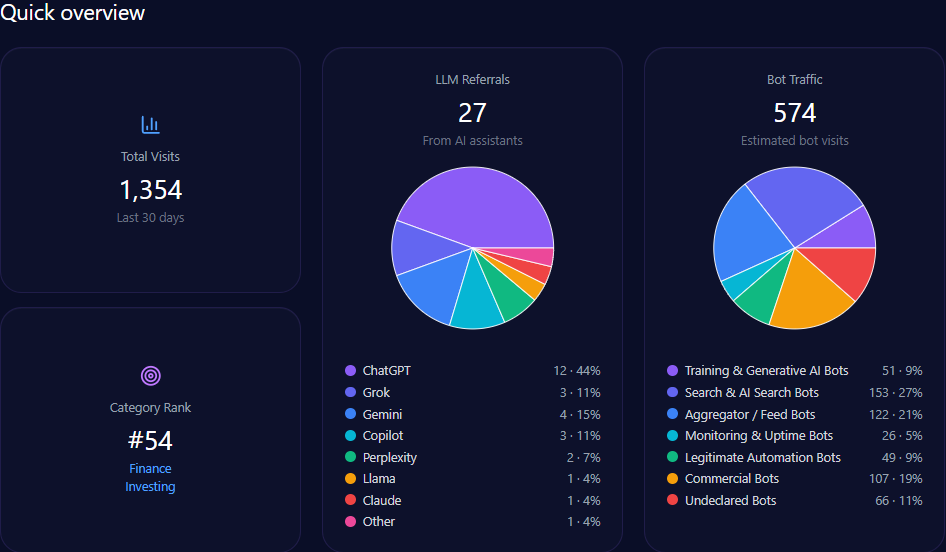
2. Test Across Multiple AI Systems
Do not test only one model.
Different AI systems may produce different answers.
Test across:
- ChatGPT
- Gemini
- Claude
- Perplexity
- Copilot
- Grok
- Other AI search tools relevant to your market
This helps you understand where your brand is strong and where it is invisible.
3. Measure Competitor Mentions
Track which competitors appear most often.
Measure:
- Mention frequency
- Recommendation order
- Citation sources
- Sentiment
- Use case framing
- Repeated phrases
- Missing competitors
- Emerging brands
This creates a clear map of your AI search landscape.
4. Identify Visibility Gaps
Look for prompts where competitors appear but your brand does not.
These are your highest-priority GEO gaps.
For each gap, ask:
- Do we have a page targeting this topic?
- Is our category positioning clear?
- Are competitors mentioned more often by third-party sources?
- Are we missing directory listings or reviews?
- Do AI systems misunderstand what we do?
- Do we need comparison content?
- Do we need stronger internal links?
5. Publish, Distribute, and Re-Test
After identifying gaps, create content and authority signals to address them.
Then re-test the same prompt set over time.
GEO works best as a feedback loop:
- Measure
- Optimize
- Publish
- Distribute
- Re-test
- Repeat
X. Common GEO Misconceptions
1. GEO Replaces SEO
False.
GEO does not replace SEO. It expands the definition of search visibility.
SEO still matters because search engines remain important discovery channels. Also, many AI systems rely on web content and search indexes when generating answers.
The future is not SEO or GEO.
The future is SEO plus GEO.
2. Ranking on Google Guarantees AI Inclusion
False.
A page can rank well on Google and still be excluded from AI-generated answers.
AI systems may synthesize from multiple sources, prioritize different entities, or select brands based on broader authority signals.
Ranking helps, but it is not the same as being recommended.
3. GEO Is Only for Large Brands
False.
Large brands often have stronger authority footprints, but smaller brands can still improve AI visibility through clarity, consistency, useful content, and focused topical authority.
A niche SaaS company can win prompts where its positioning is specific and well-supported.
4. AI Mentions Cannot Be Measured
False.
AI visibility can be measured through structured prompt testing.
You can track:
- Whether your brand appears
- How often it appears
- Which competitors appear
- Whether your website is cited
- How your brand is described
- Which prompts produce visibility gaps
The key is to move from random testing to a repeatable measurement framework.
5. GEO Is Just Adding Keywords for AI
False.
Keyword stuffing does not solve GEO.
Generative AI systems need clear entities, trustworthy sources, consistent descriptions, strong topical relationships, and useful content.
GEO is less about repeating keywords and more about building a brand footprint that AI systems can understand.
XI. GEO Implementation Roadmap
A practical GEO roadmap can be divided into four phases.
1. Baseline Measurement
Start by measuring your current AI visibility.
Actions:
- Build a list of 100 to 300 relevant prompts
- Group prompts by intent
- Test across multiple AI systems
- Record brand mentions
- Record competitor mentions
- Record citations
- Record sentiment
- Identify missing prompts
The goal is to understand your current baseline before making changes.
2. Entity and Content Optimization
Next, improve your owned assets.
Actions:
- Clarify homepage positioning
- Create or update definition pages
- Add comparison pages
- Improve product pages
- Add structured data
- Strengthen internal links
- Standardize brand descriptions
- Improve author and organization signals
The goal is to make your brand easier to understand and classify.
3. Authority Expansion
After your owned content is clear, expand your external authority footprint.
Actions:
- Publish original research
- Build directory listings
- Collect authentic reviews
- Earn mentions from relevant publications
- Create shareable frameworks
- Build backlinks from industry-relevant sources
- Participate in category conversations
The goal is to make your brand visible beyond your own website.
4. Continuous Monitoring
Finally, monitor AI visibility over time.
Actions:
- Re-test prompts weekly or monthly
- Track competitor changes
- Monitor new citations
- Review sentiment drift
- Update old content
- Add new pages for emerging prompt gaps
- Report AI visibility trends to marketing and leadership teams
The goal is to turn GEO into an ongoing operating system, not a one-time campaign.
XII. The Future of AI Search
AI assistants are becoming research tools, comparison engines, recommendation systems, and decision-support interfaces.
This changes how brands are discovered.
In traditional search, users could scan multiple results and decide which links to open. In AI search, the assistant often compresses the market into a short answer.
That compression creates winners and losers.
Brands that are included gain awareness.
Brands that are cited gain credibility.
Brands that are recommended gain consideration.
Brands that are excluded may become invisible, even if they still have traditional search rankings.
This is why GEO matters.
The next phase of digital visibility will not only be about ranking pages. It will be about becoming a trusted entity inside AI-generated answers.
XIII. Frequently Asked Questions
1. What is Generative Engine Optimization?
Generative Engine Optimization is the process of improving how AI systems mention, cite, compare, and recommend a brand inside generated answers.
2. How is GEO different from SEO?
SEO focuses on ranking web pages in traditional search results. GEO focuses on brand inclusion, citations, sentiment, and positioning inside AI-generated responses.
3. Is GEO measurable?
Yes. GEO can be measured through prompt testing, mention frequency, share of voice, citation frequency, recommendation position, sentiment analysis, and prompt coverage rate.
4. Does GEO require technical SEO?
Yes, technical SEO can support GEO. Structured data, crawlable pages, fast loading, clean site architecture, and internal links help machines understand your content.
5. Can a small brand improve AI visibility?
Yes. Smaller brands can improve visibility by creating clear category content, strengthening entity consistency, publishing useful resources, earning third-party mentions, and monitoring prompt-level performance.
6. How long does GEO take to work?
GEO is cumulative. Some improvements may appear after content is crawled or cited, while broader authority signals may take months to develop.
7. Which companies should prioritize GEO?
GEO is especially important for SaaS companies, B2B technology brands, agencies, ecommerce brands, cybersecurity companies, fintech companies, and any business where users rely on AI tools for research and comparison.
8. Does ranking on Google guarantee that AI systems will mention my brand?
No. Google rankings can help, but they do not guarantee AI inclusion. AI systems may use different sources, summaries, and entity signals when generating answers.
9. What is prompt coverage in GEO?
Prompt coverage is the percentage of relevant prompts where your brand appears in AI-generated answers. It helps measure how visible your brand is across real user questions.
10. Why does AI recommend my competitors instead of my brand?
AI may recommend competitors because they have stronger authority signals, clearer category positioning, more third-party mentions, better content structure, or stronger association with the user’s prompt.
XIV. Conclusion
Generative Engine Optimization is becoming a necessary part of modern search strategy.
As users move from search results to AI-generated answers, brands must compete for inclusion, citations, and accurate representation inside those answers.
SEO is still important, but it is no longer the full picture.
The new visibility question is not only:
“Do we rank?”
It is also:
“Do AI systems mention us, cite us, compare us correctly, and recommend us when users ask high-intent questions?”
Brands that answer this question early will have an advantage.
They will understand how AI systems perceive their market, where competitors are gaining visibility, and which prompts influence buyer decisions.
GEO gives teams a framework for measuring and improving that visibility.
In the AI search era, the brands that win will not only be the brands with rankings. They will be the brands that are clearly understood, consistently represented, and confidently included inside AI-generated answers.