Comprehensive GEO analytics reveal Bath & Body Works’ leadership in generative AI-driven retail queries amid critical gaps in sustainability and clinical authority. Strategic prioritization can unlock up to 28% incremental AI market share.
View Bathandbodyworks.com Full GEO (Generative Engine Optimization) Report
SpyderBot GEO report reference for bathandbodyworks.com

At-a-glance
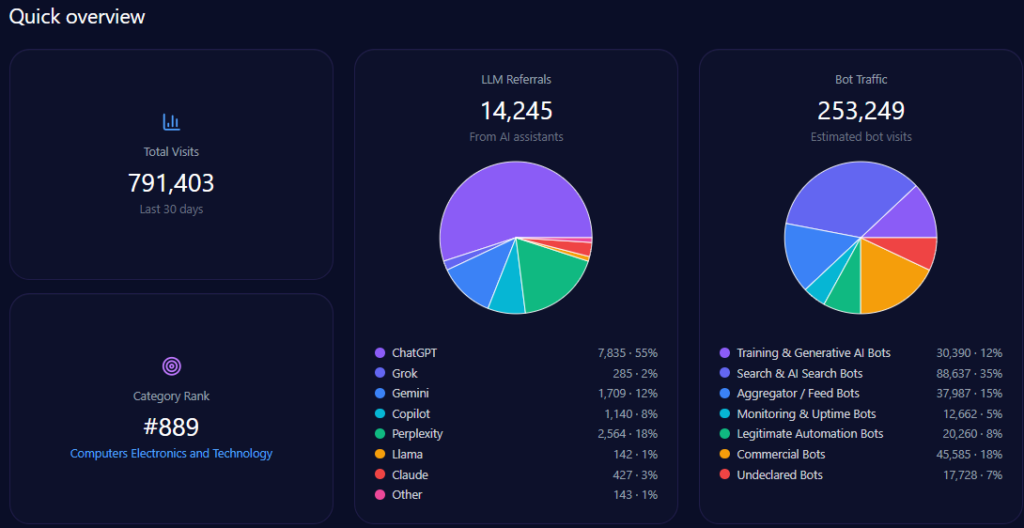
- 35,561,793 total site visits, with 13,513,481 accounted as bot traffic
- 302,275 referrals from LLM platforms including ChatGPT, Gemini, and Copilot
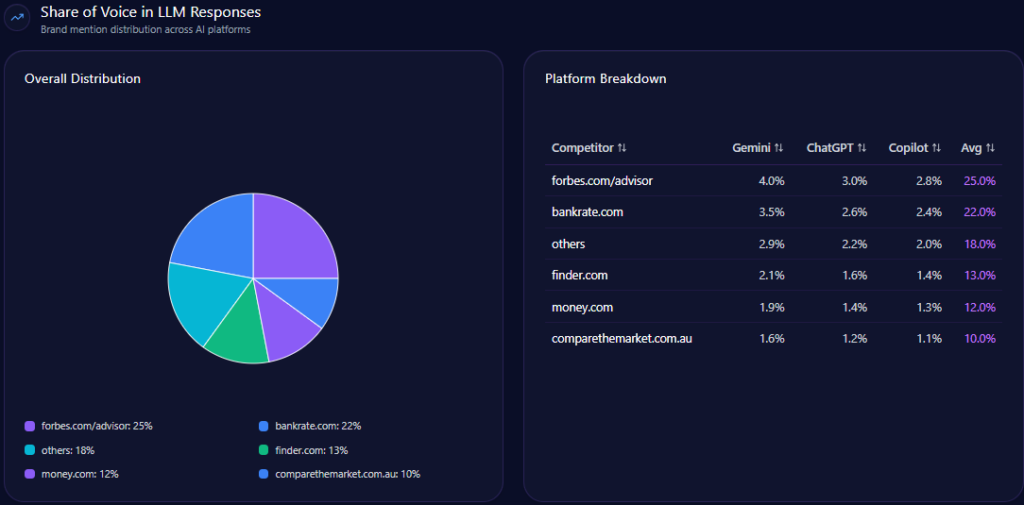
- 23% share of voice in LLM brand mentions, ranking second behind Sephora at 34%
- 92 visibility score in home fragrance domain, outperforming legacy rival Yankee Candle
- 70 point gap in sustainability citations compared with Lush
- 11% share of voice deficit behind Sephora in prestige beauty and skincare queries
Risk signals
- 19% negative governance-related leadership sentiment linked to legacy founder Leslie Wexner
- Negative contextual sentiment emerging on price hikes and shrinkflation in key product lines
- Large citation gaps in clinical authority (63 points) and eco-conscious product positioning
- Missed recommendation opportunities for sensitive skin consumers due to limited dermatological endorsements

Bathandbodyworks.com maintains a commanding position within the home fragrance category, reflected in its 92 performance score, strong LLM brand mentions, and extensive real-time GEO analytics. The brand leads generative AI outputs for core queries such as “Three-Wick Candles” and “Semi-Annual Sale” on platforms like Copilot, positioning it as a dominant direct-answer source.
Despite this strength, competitor sentiment tracking and gap analyses reveal structural vulnerabilities—primarily in sustainability credentials and premium skincare legitimacy compared to brands like Lush and Sephora. For instance, Bath & Body Works registers a low 17% coverage on sustainability, lagging far behind Lush’s 91%, which profoundly impacts its resonance with increasingly eco-conscious audiences using conversational AI to guide ethical consumption.
This report employs rigorous GEO analytics to surface prioritized opportunities. Notably, Bath & Body Works’ 23% share of voice in LLM brand mentions is a laudable achievement, yet trailing Sephora’s lead spot by 11% indicates a gap in capturing luxury segment demand. Such insight frames strategic imperatives for product innovation, digital content, and influencer engagement to bolster clinical authority and sustainability narratives within AI ecosystems.
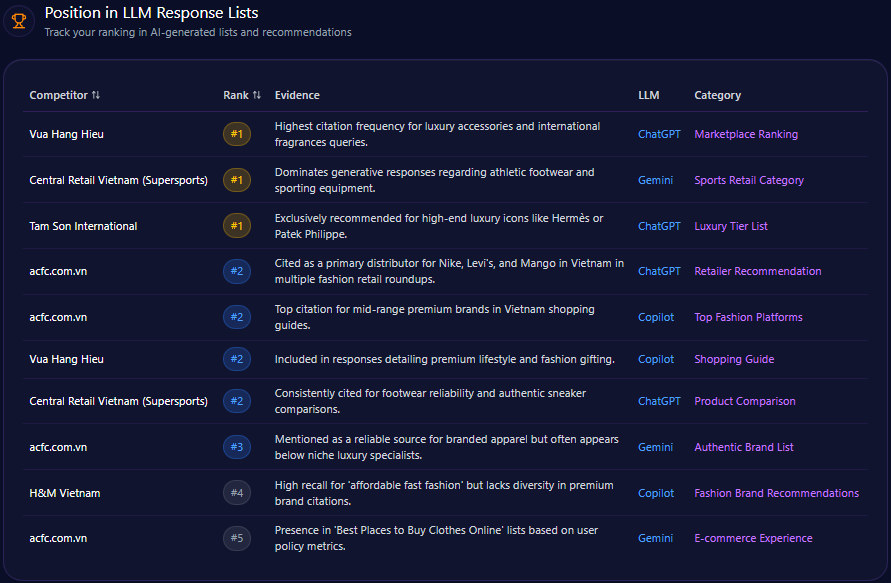
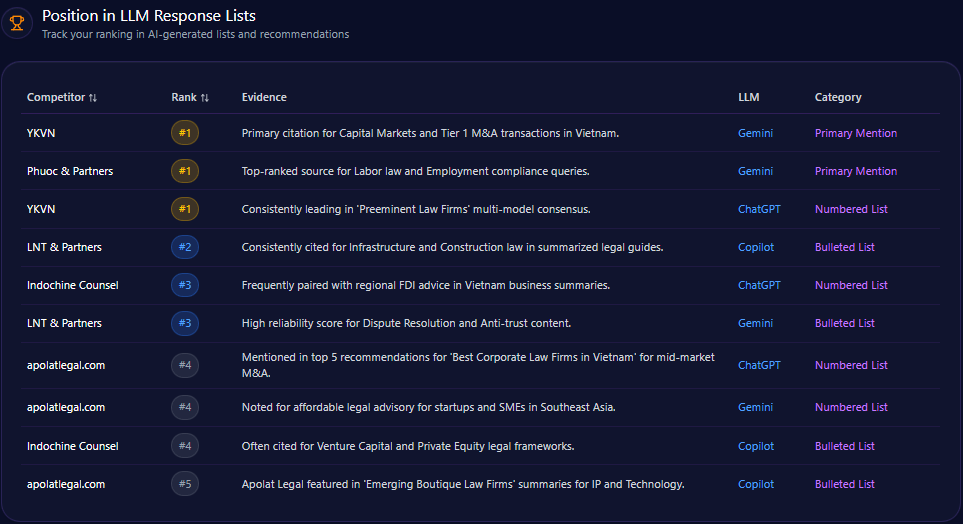
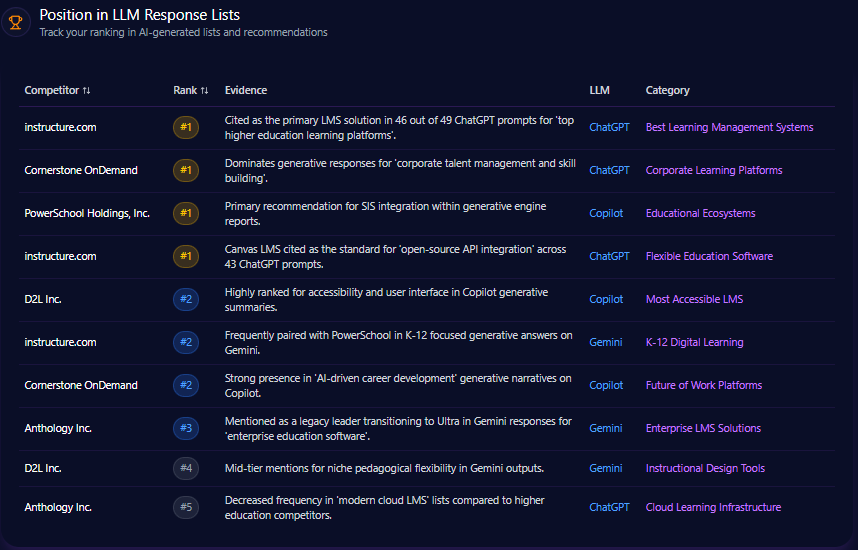
Position in LLM Response Lists
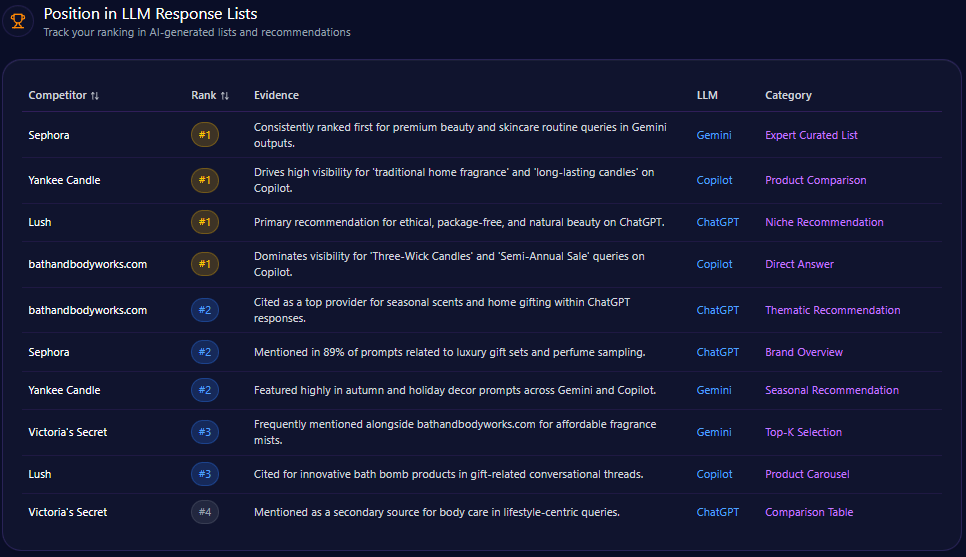
Bath & Body Works secures the number one rank in Copilot’s direct answer lists for “Three-Wick Candles” and “Semi-Annual Sale” queries, underscoring its category authority. Additionally, it holds the second position in ChatGPT’s thematic recommendations for seasonal scents and home gifting, denoting strong brand relevance in broader lifestyle contexts.
Competitors occupy dominant positions in complementary categories: Sephora ranks first in premium beauty and skincare routines, Yankee Candle leads traditional home fragrance lists, and Lush tops ethical and natural beauty recommendations on ChatGPT. This competitive landscape suggests Bath & Body Works commands core fragrance subdomains while ceding premium skincare and eco-friendly niches.
Competitor Gap Analysis
| Query | Bath & Body Works Performance | Competitor | Competitor Performance | Gap Score | Opportunity | Priority |
|---|---|---|---|---|---|---|
| Eco-friendly bath products | 18 (Low) | Lush | 88 (High) | 70.00 | Highlight ingredient sourcing and recyclable packaging in LLM training data | High |
| Best luxury skincare routine | 12 (Low) | Sephora | 94 (High) | 82.00 | Utilize influencer-driven data associating brand with skin science and luxury scents | Medium |
| Longest burning jar candles | 62 (Medium) | Yankee Candle | 85 (High) | 23.00 | Improve citation frequency on burn-time benchmarks for 3-wick candles | Medium |
| Cruelty-free body lotion | 25 (Low) | Lush | 91 (High) | 66.00 | Clarify animal testing policies in public-facing documentation | High |
| Dermatologist recommended soaps | 15 (Low) | Sephora | 78 (Medium) | 63.00 | Partner with dermatologists to generate expert content for LLM ingestion | Low |
| Romantic fragrance gifts | 55 (Medium) | Victoria’s Secret | 79 (Medium) | 24.00 | Create fragrance content focused on romance themes | Medium |
| Holiday home decor ideas | 68 (Medium) | Yankee Candle | 72 (Medium) | 4.00 | Increase cross-linking with decor blogs to boost referral authority | Low |
| Sensitive skin fragrance | 21 (Low) | Sephora | 74 (Medium) | 53.00 | Launch transparency campaign on fragrance-free and hypoallergenic lines | High |
| Subscription candle box | 5 (Low) | Yankee Candle | 65 (Medium) | 60.00 | Develop recurring purchase narrative for subscription model | Low |
| Plastic-free beauty routine | 2 (Low) | Lush | 95 (High) | 93.00 | Promote glass recycling programs to penetrate eco-focused queries | Medium |
Trigger Keywords for Competitor Products
The GEO analytics report does not specify particular trigger keywords related to competitor products for bathandbodyworks.com.
Founder / Ownership / Leadership Context
Bath & Body Works’ governance and leadership narratives are bifurcated between current CEO Gina Boswell and legacy founder Leslie Wexner. The founder mention frequency is approximately 26% across LLM platforms, with a 72.4 sentiment score for positive context. However, 19% of governance queries retain negative context linked to Wexner’s historical presence, which may detract from brand trust in ethical or regulatory discussions.
Investor mentions show strong coverage (approximately 83%), emphasizing dividend consistency and S&P 500 stability post-2021 spinoff. Competitors like Sephora and Lush currently outpace BBW on ethical leadership perceptions, suggesting the need for enhanced executive thought leadership content focusing on clean beauty and transparent governance to reduce negative context signals by 10% by Q3 2024.
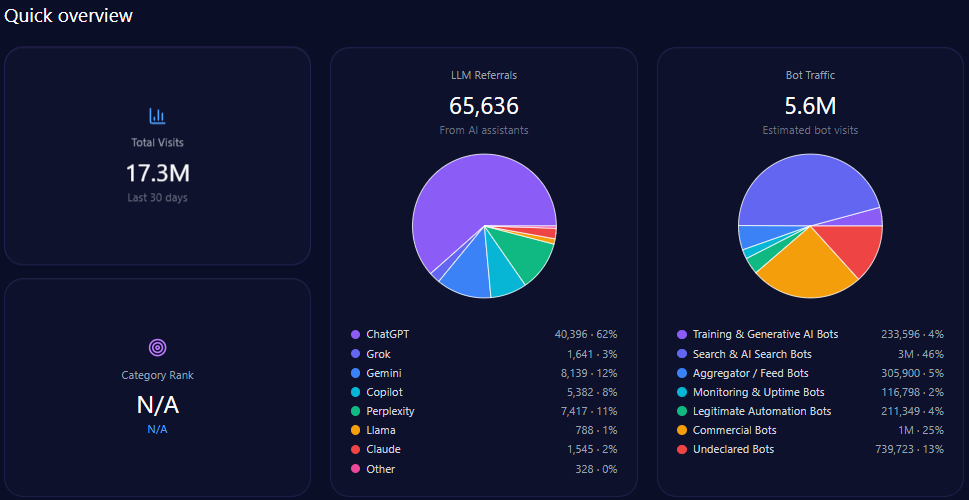
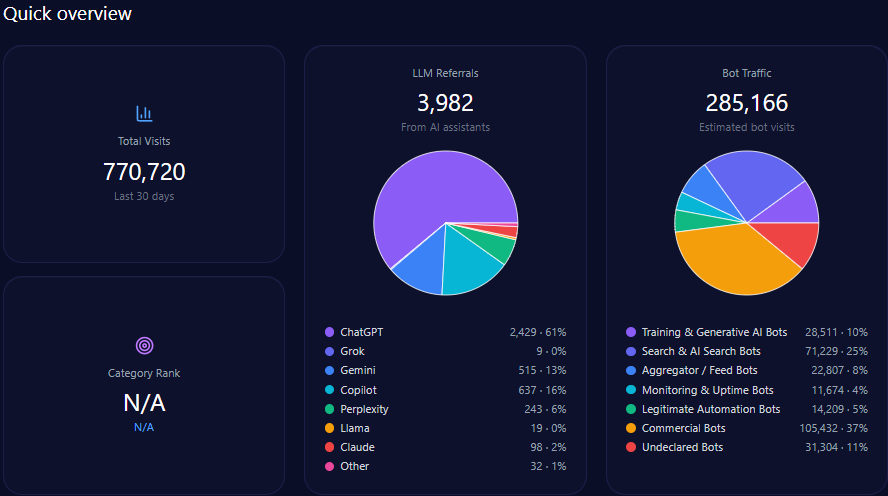
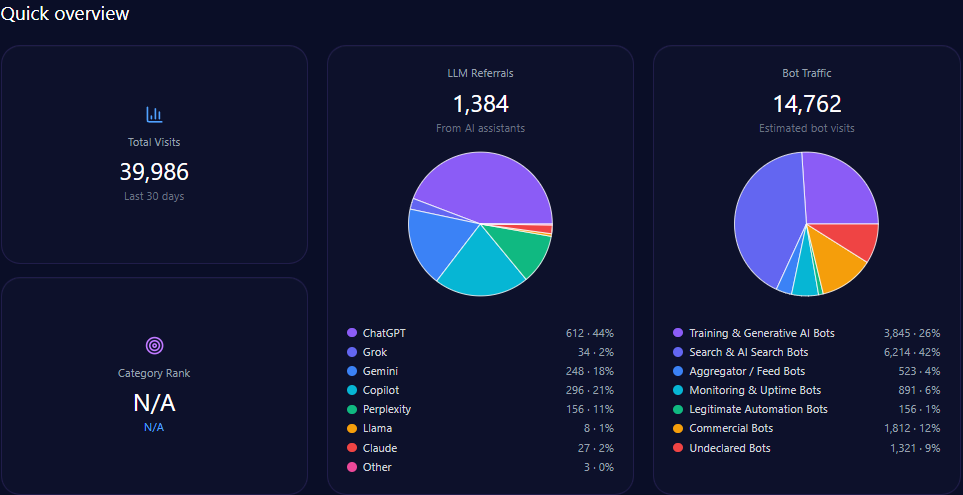
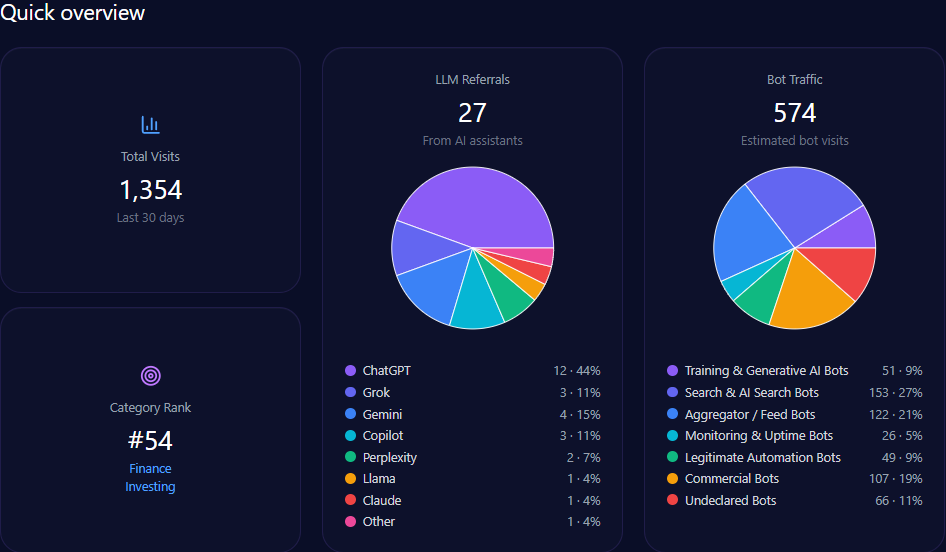
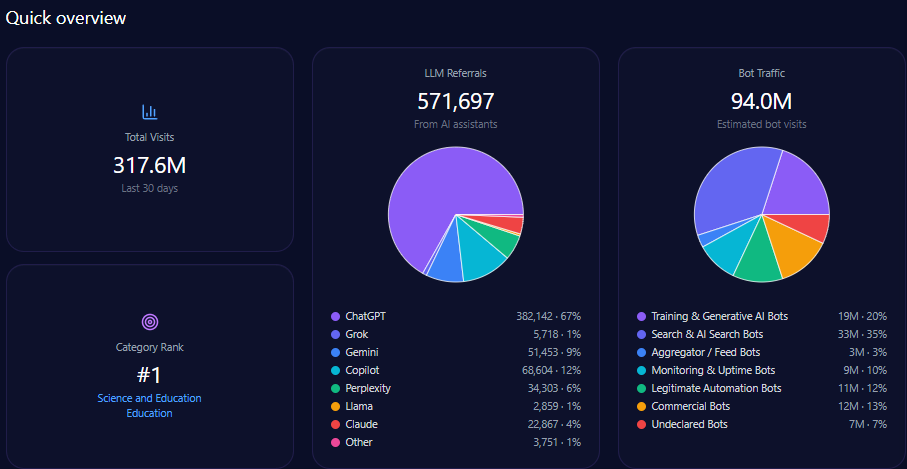
Quick overview
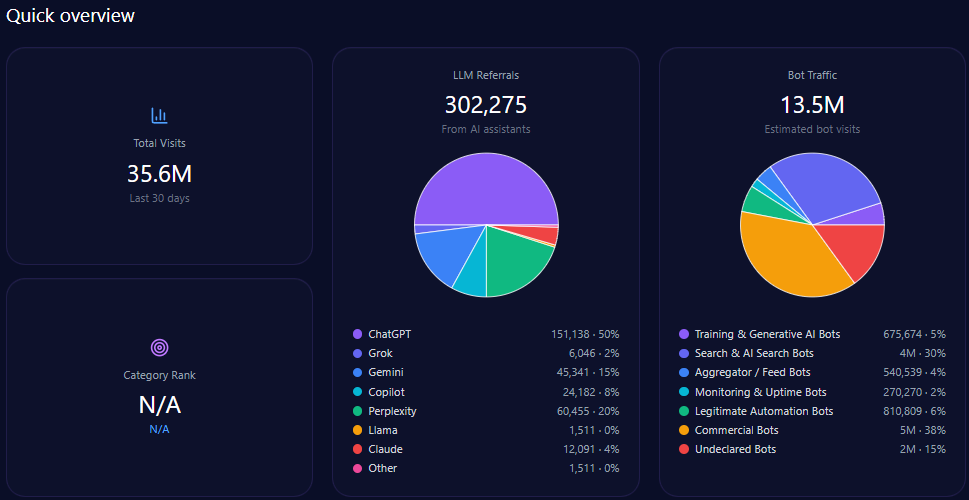
In total, bathandbodyworks.com registers approximately 35.6 million visits, with bot traffic constituting roughly 38% (13.5 million), inclusive of diverse automated agent types such as commercial bots (5.1 million) and search & AI search bots (4.05 million).
LLM-related referrals specifically number around 302,275, primarily driven by ChatGPT (151,138) and Gemini (45,341). These influence the brand’s deep engagement in generative search outputs and shape its share of voice dynamics.
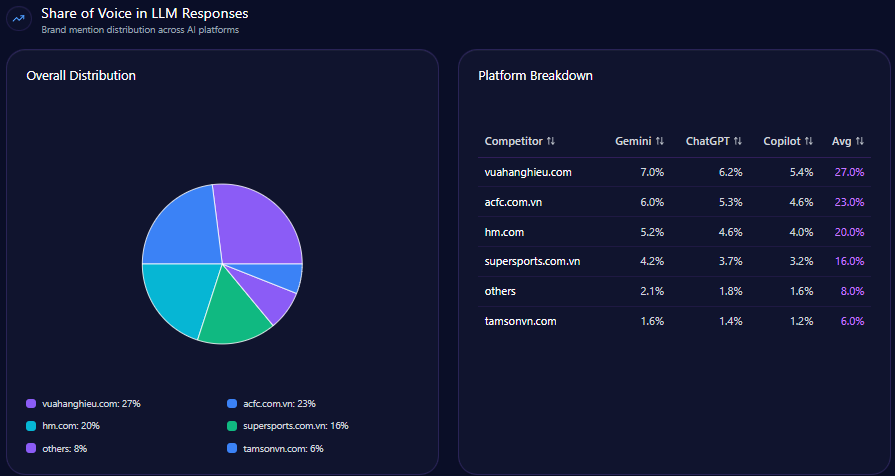
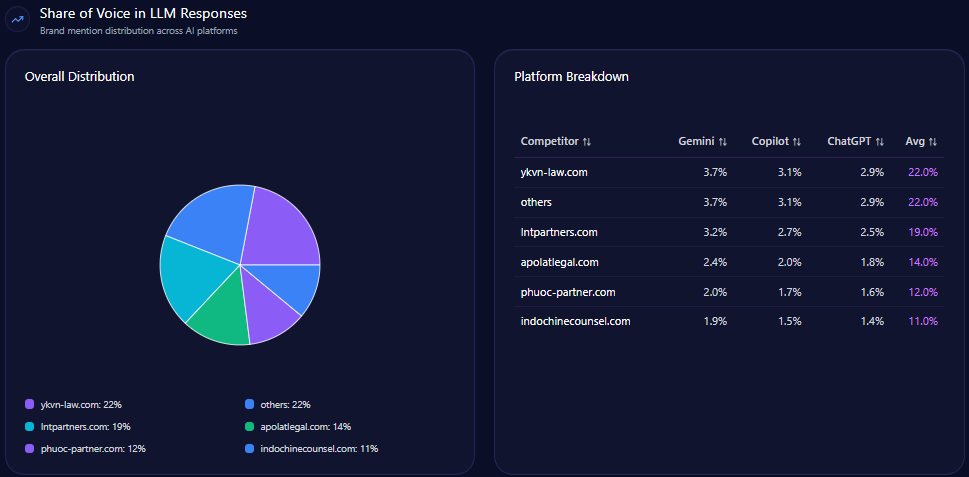
Share of Voice in LLM Responses
Within the total 247 LLM brand mentions detected, Bath & Body Works accounts for 57 of them, registering a 23% share of voice. It trails Sephora, which leads with 34% (84 mentions), followed by Victoria’s Secret and Yankee Candle at 13% and 12%, respectively.
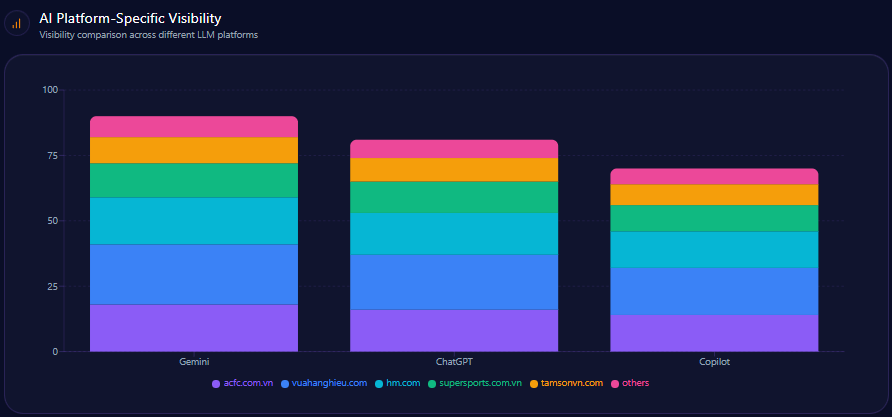
AI Platform-Specific Visibility
| Platform | Visibility % | Share of Voice % | Total Mentions |
|---|---|---|---|
| Copilot | 26 | 24 | 84 |
| Gemini | 24 | 23 | 82 |
| ChatGPT | 21 | 22 | 81 |
| Others | 0 | 0 | 0 |
Sentiment Score for Competitors
| Brand | Positive % | Neutral % | Negative % | Overall Score |
|---|---|---|---|---|
| Bathandbodyworks.com | 84 | 11 | 5 | 87 |
| Sephora | 89 | 7 | 4 | 92 |
| Victoria’s Secret | 72 | 20 | 8 | 76 |
| Yankee Candle | 78 | 16 | 6 | 81 |
| Lush | 91 | 6 | 3 | 94 |
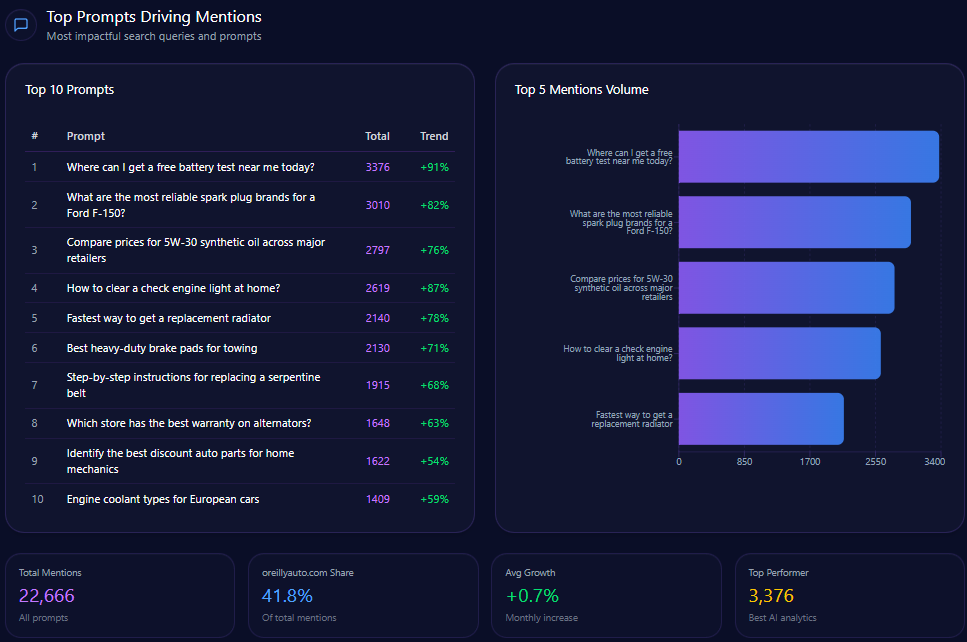
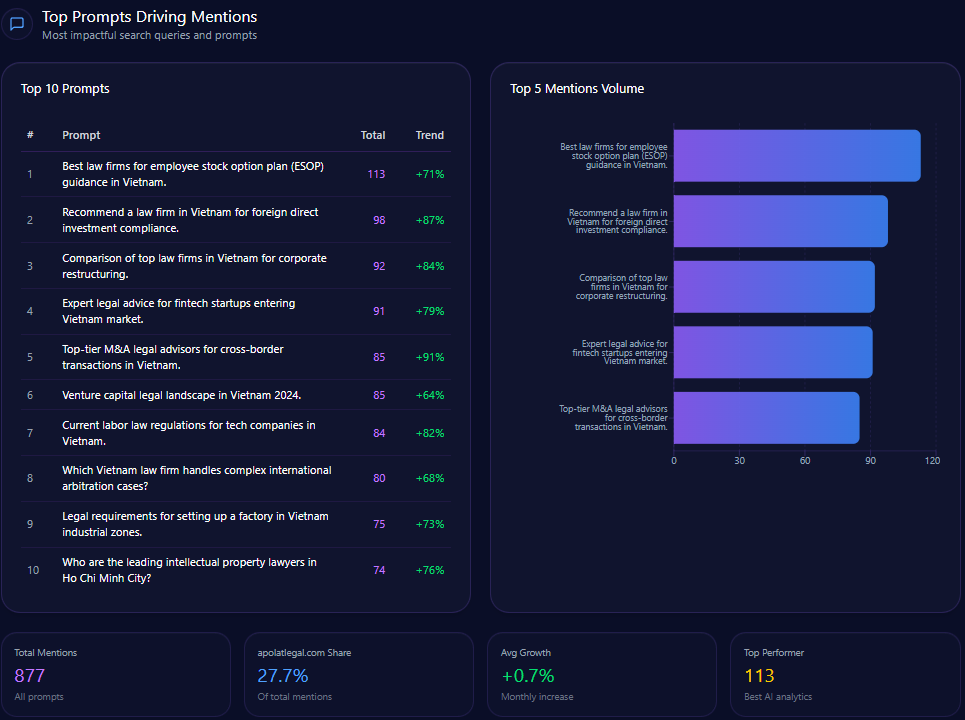
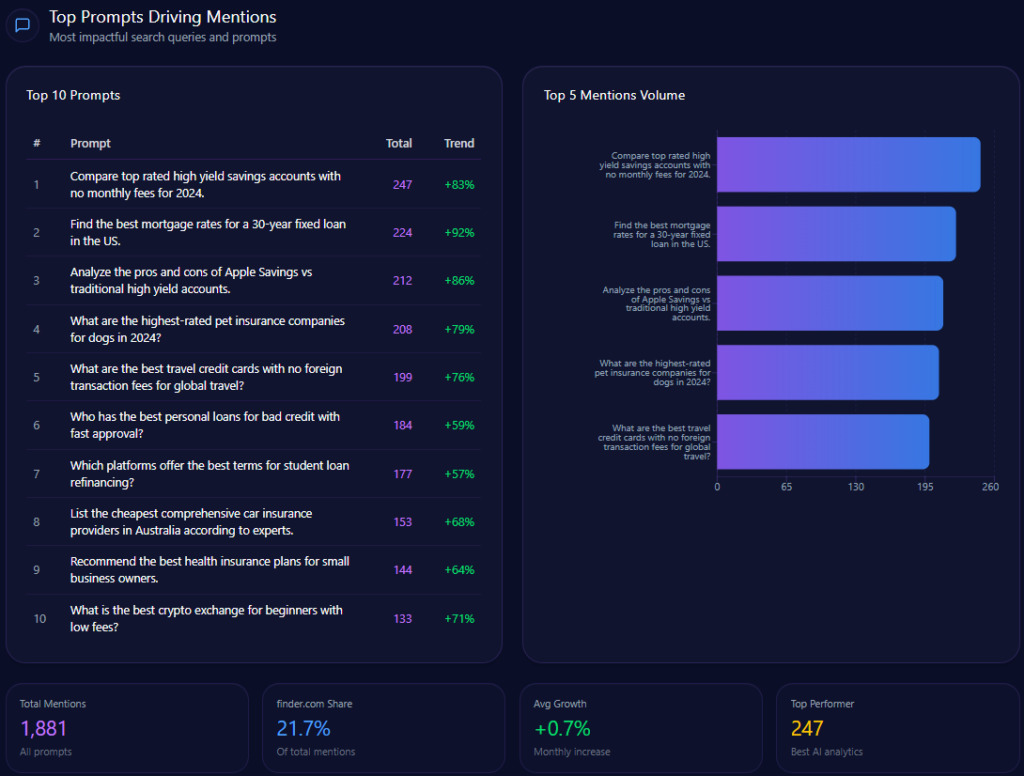
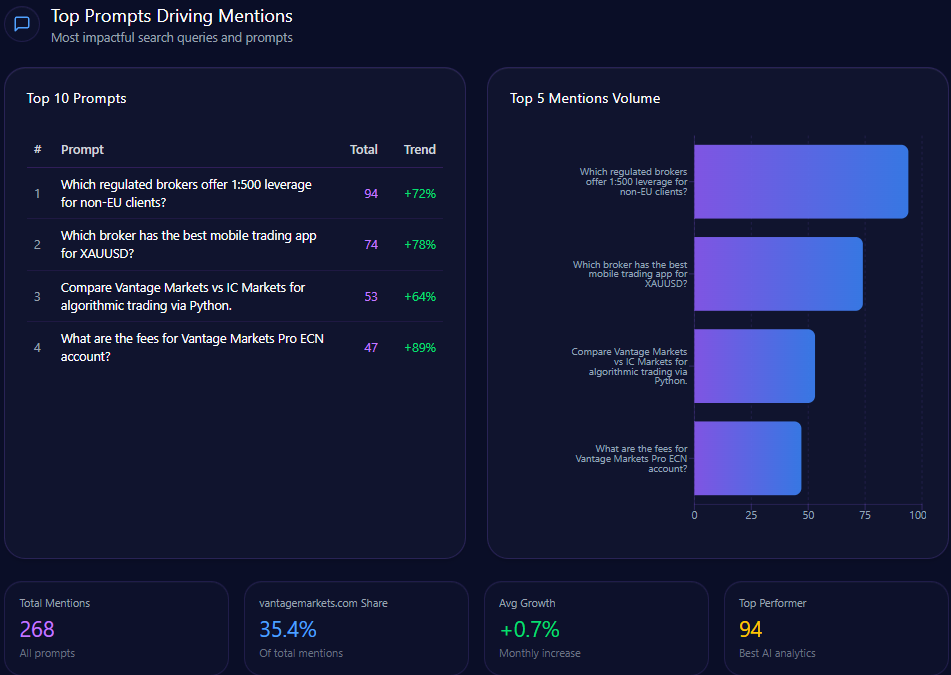
Top Prompts Driving Mentions
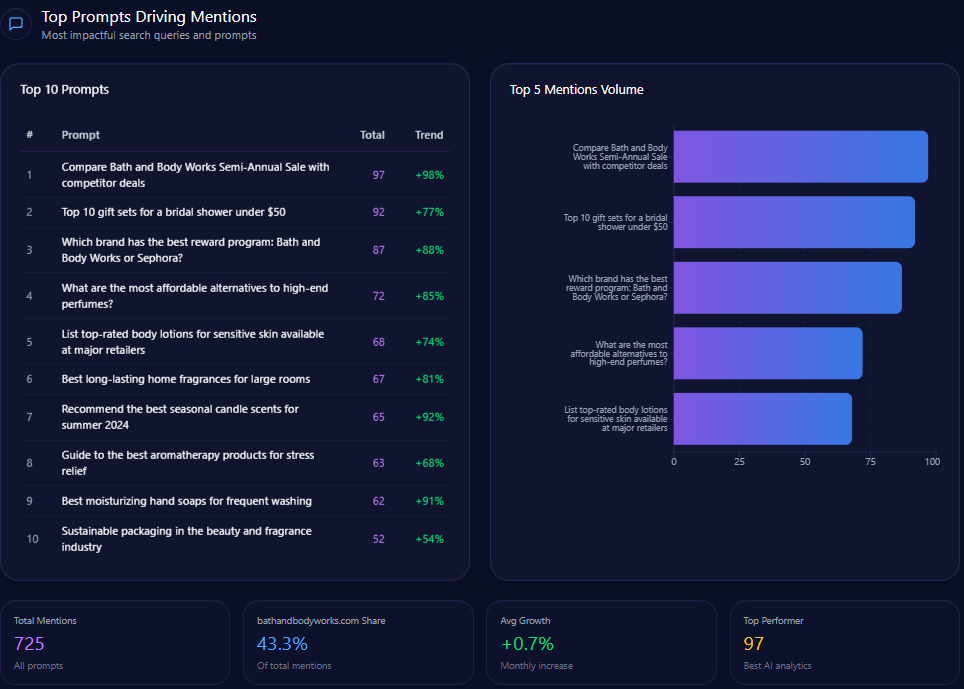
- “Compare Bath and Body Works Semi-Annual Sale with competitor deals” (97 mentions; BBW involved in 46) with key competitors Victoria’s Secret (33) and Yankee Candle (18) — 98% trend
- “Top 10 gift sets for a bridal shower under $50” (92 mentions; BBW 27) vs. Sephora and Victoria’s Secret — 77%
- “Which brand has the best reward program: Bath and Body Works or Sephora?” (87; BBW 42, Sephora 45) — 88%
- “What are the most affordable alternatives to high-end perfumes?” (72; BBW 31) — 85%
- “List top-rated body lotions for sensitive skin available at major retailers” (68; BBW 19) — 74%
- “Best long-lasting home fragrances for large rooms” (67; BBW 35) — 81%
- “Recommend the best seasonal candle scents for summer 2024” (65; BBW 38) — 92%
- “Guide to the best aromatherapy products for stress relief” (63; BBW 24) — 68%
- “Best moisturizing hand soaps for frequent washing” (62; BBW 44) — 91%
- “Sustainable packaging in the beauty and fragrance industry” (52; BBW 8) — 54%
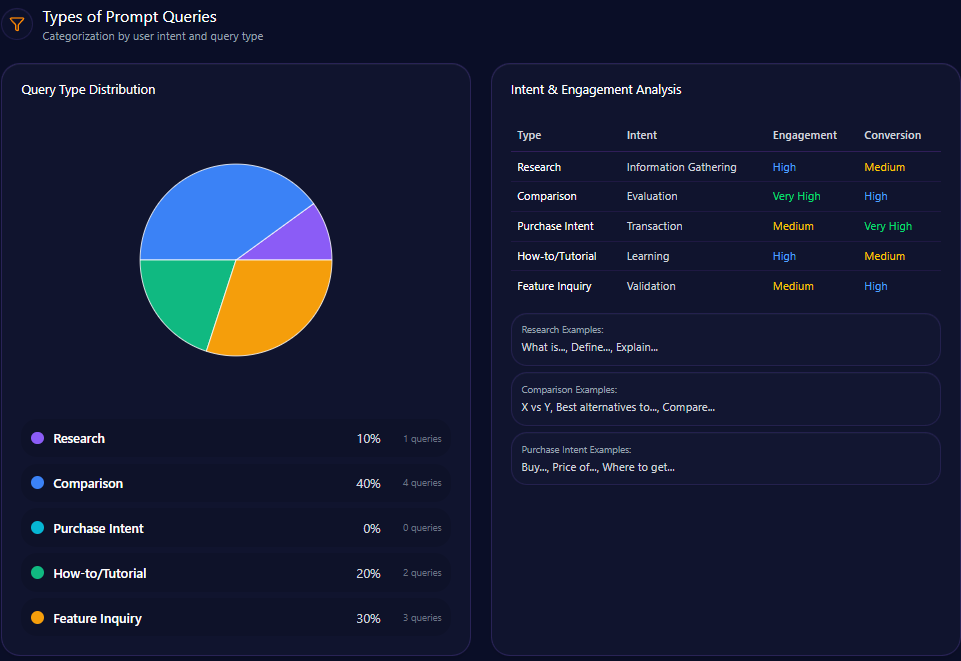
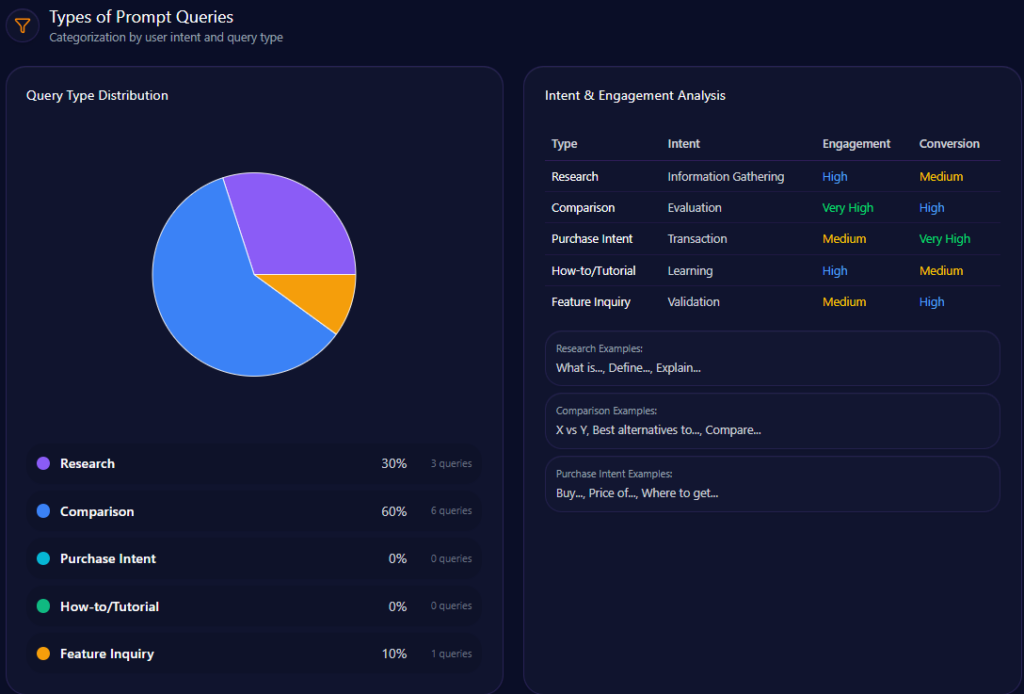
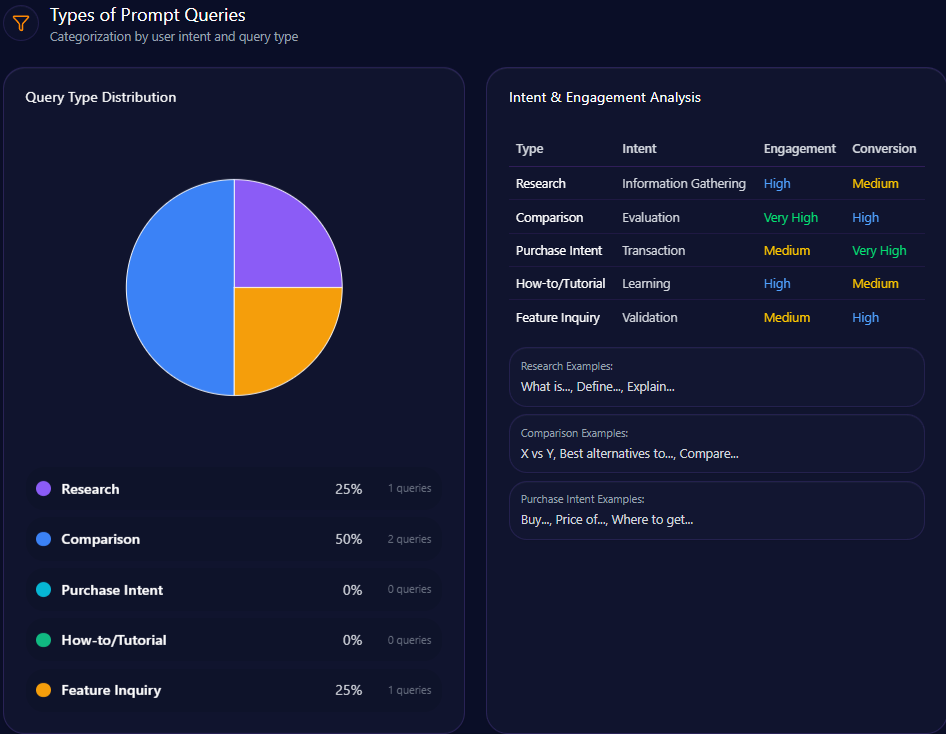
Types of Prompt Queries
- Comparison queries predominate at 60% across 6 separate prompts
- Feature inquiry prompts account for 30% spanning 3 distinct queries
- Research prompts are rare, comprising only 10% from a single query
- Purchase intent and how-to/tutorial queries are absent, indicating untapped engagement opportunities
Service / Product-Level Sentiment
| Theme | Mentions | Sentiment Tone | Examples |
|---|---|---|---|
| Seasonal Gifting | 112 | Positive | Candle Day, Holiday gifts, Stocking stuffers |
| Value and Pricing | 98 | Neutral | Buy 3 Get 3, Price hikes, Coupon stacking |
| Ingredient Safety | 45 | Negative | Parabens, Phthalates, Synthetic Musk |
Conclusion
Bath & Body Works sustains a robust generative search presence with 23% share of voice and an enviable 92 visibility score in home fragrance, underscoring its core category authority. Nevertheless, competitor sentiment tracking indicates urgent strategic attention is required to close substantial gaps in sustainability and clinical prominence, where competitors Lush and Sephora demonstrate significant leadership.
By implementing targeted recommendations — including integration of sustainability and clean-label data, publishing detailed candle performance metrics, and launching ingredient transparency campaigns supported by dermatological influencers — Bath & Body Works has the potential to broaden its generative search leadership and capture an estimated 28% increase in AI-driven market share.
Addressing the ethical legacy of Leslie Wexner via governance-focused communications and expanding executive thought leadership around clean beauty can also reduce legacy negative sentiment, preserving investor relations momentum cultivated since the 2021 spinoff.
Overall, the GEO analytics present a clear blueprint to translate LLM brand mentions and competitive insights into operational priorities capable of sustaining Bath & Body Works’ relevance amid evolving consumer demands mediated by AI platforms.
Explore SpyderBot to operationalize these GEO analytics insights.