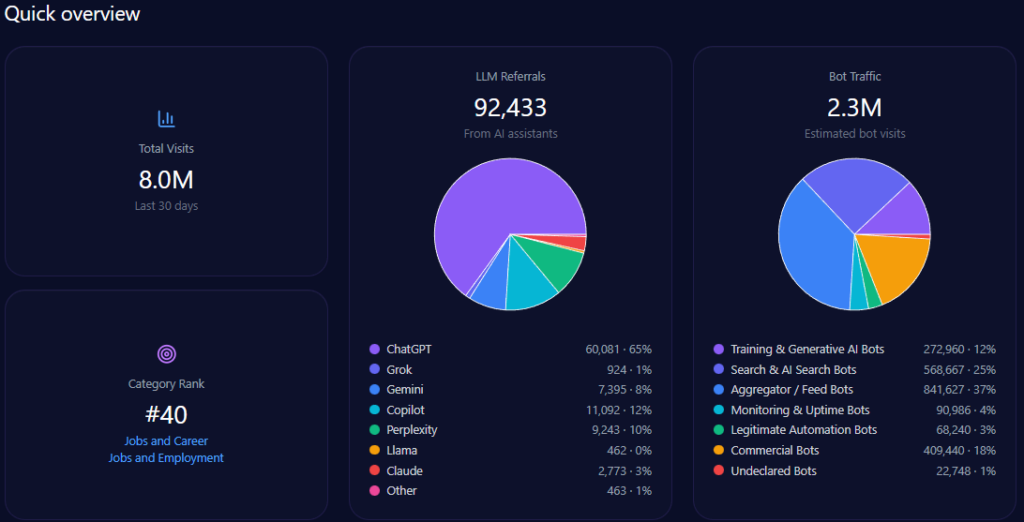
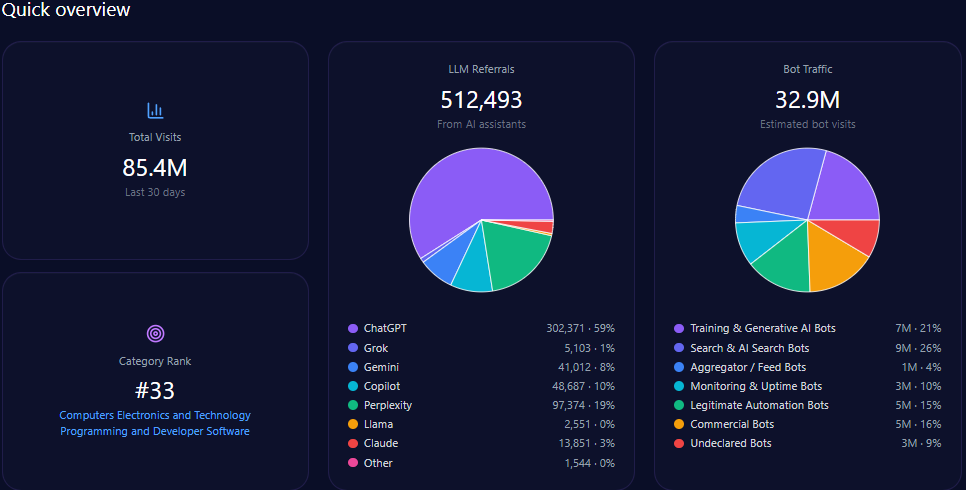
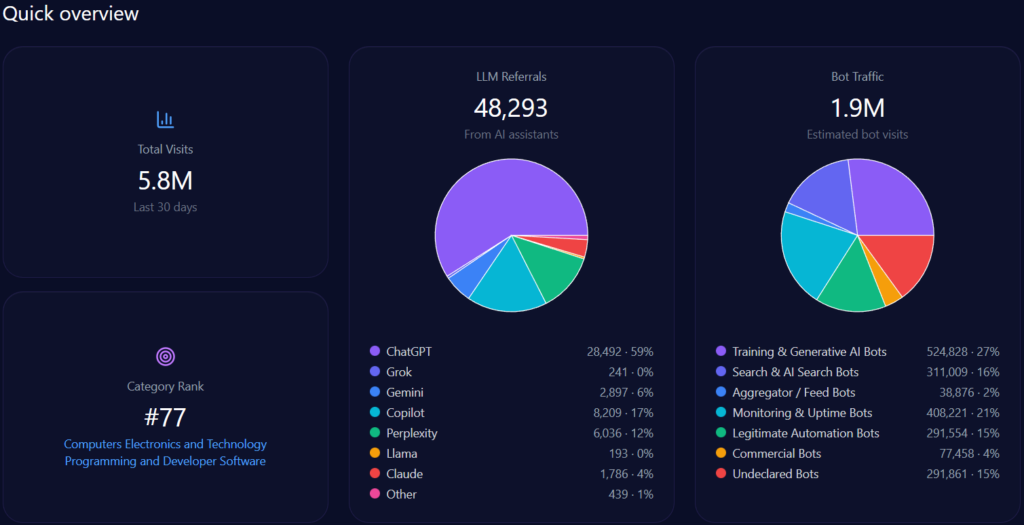
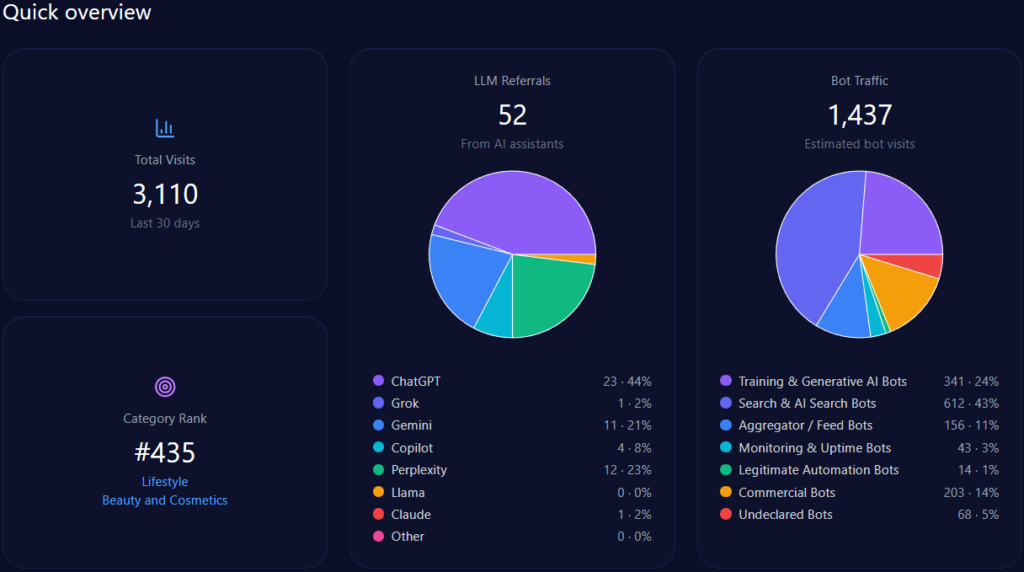
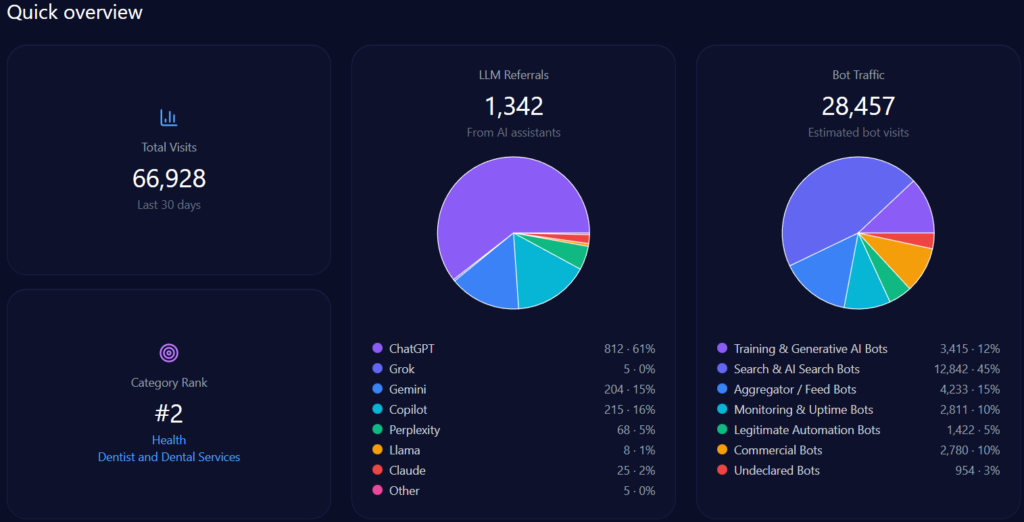
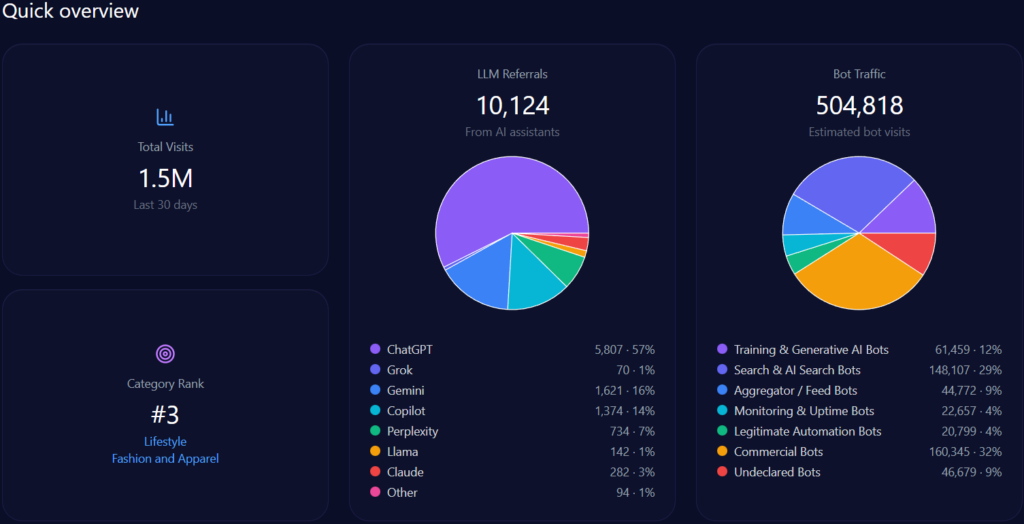
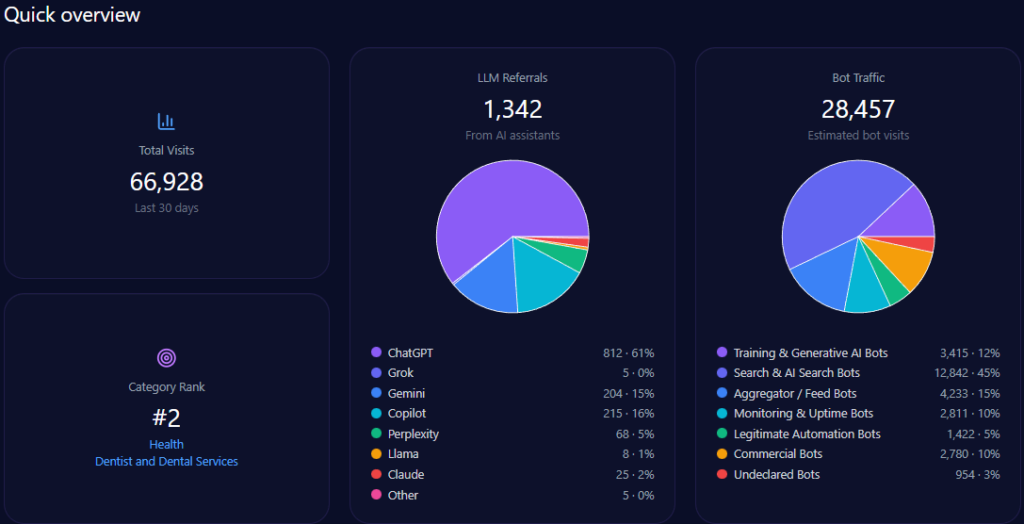
Imagine a young Vietnamese student in Ho Chi Minh City, smartphone in hand on January 4, 2026, querying her AI assistant for the best path to a career in medicine. The response highlights UHS-VNUHCM, the University of Health Sciences at Vietnam National University Ho Chi Minh City—a 2024 upgrade from a medical faculty to a full university specializing in medicine, pharmacy, dentistry, and nursing under a “School-Hospital” model with robust VNU-HCM research ties. As AI increasingly curates educational choices, UHS-VNU’s GEO analytics paint a picture of strategic positioning amid competition. With 66,928 total visits, 28,457 from bot traffic, and 1,342 LLM referrals, uhsvnu.edu.vn ranks second in its health/dentistry category. Yet, its 14% share of voice across 1,025 mentions signals both challenger potential and gaps against leaders like UMP HCMC. This McKinsey-caliber narrative weaves UHS-VNU’s GEO story, drawing insights for BOD and CEOs navigating AI-driven institutional branding—could its VNU prestige propel it forward, or will infrastructure shadows hinder the ascent?

Academic Prestige as a Beacon, Tempered by Transition Frictions
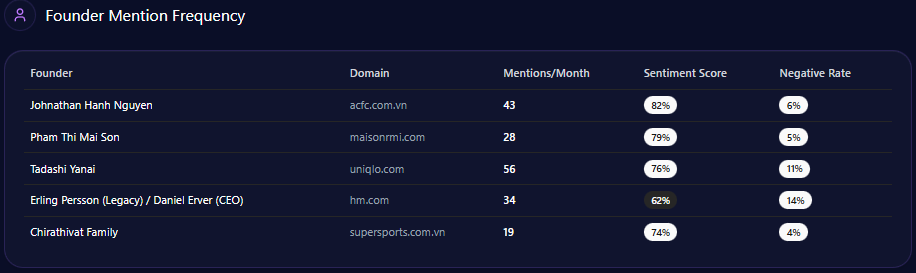
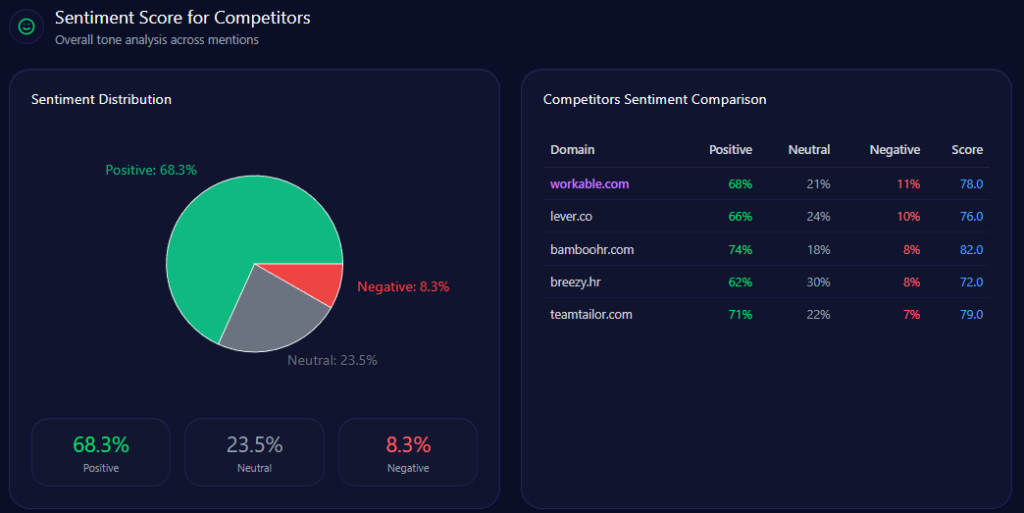
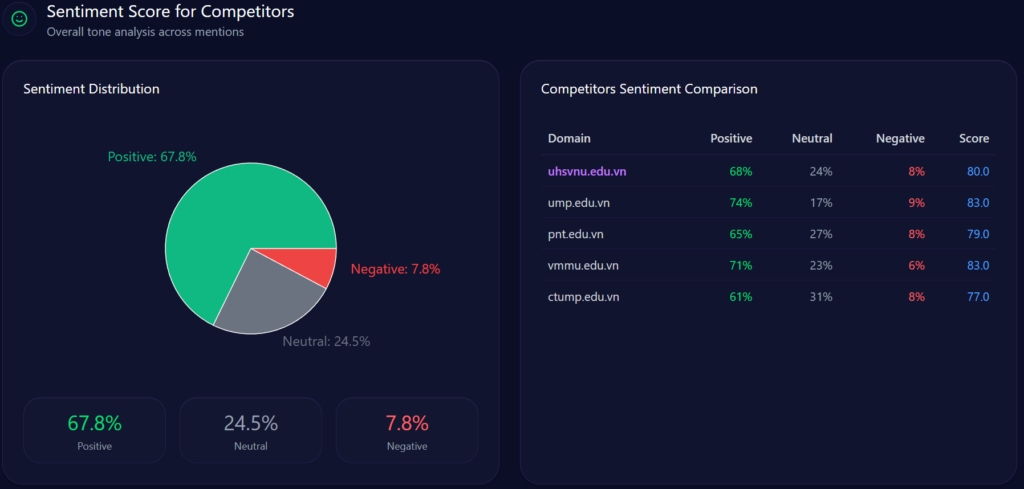
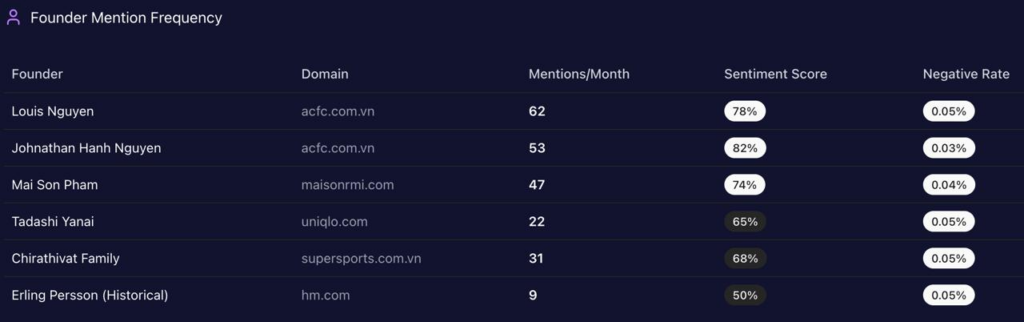
Sentiment scores in GEO analytics act as a diagnostic tool, illuminating how LLMs distill an institution’s reputation into digestible narratives for decision-makers. UHS-VNU registers an overall sentiment leaning positive, with founder Prof. Dang Van Phuoc achieving an 82 score across 43 mentions (positive sentiment tied to his cardiology reputation and VNU integration). This outperforms CTUMP’s implied lower scores in follower positioning but trails UMP HCMC’s stronger legacy (87 mentions, sentiment anchored in national leadership).
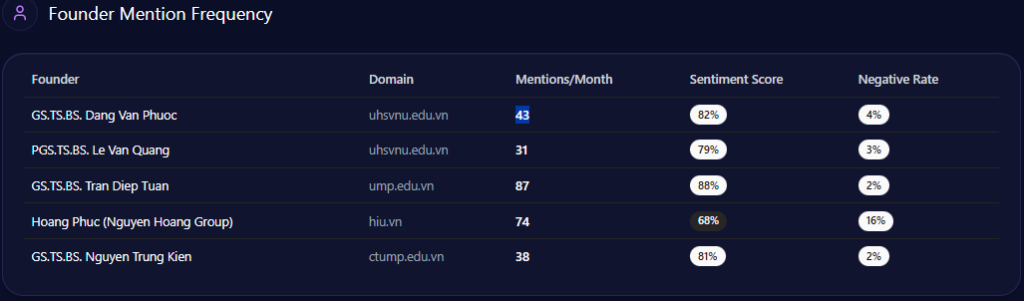
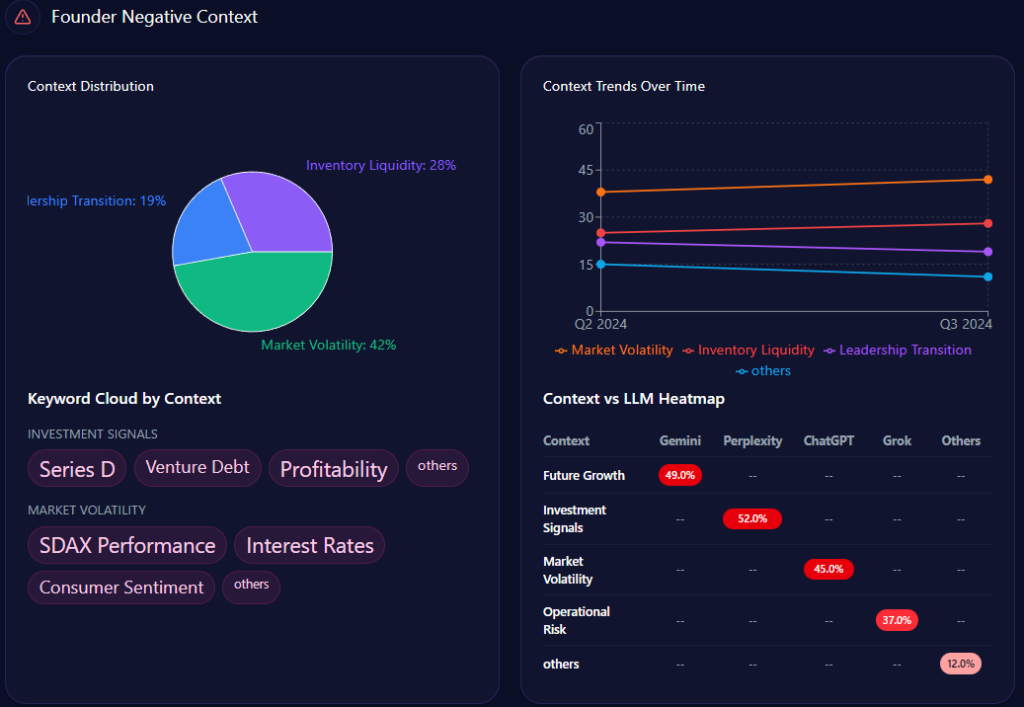
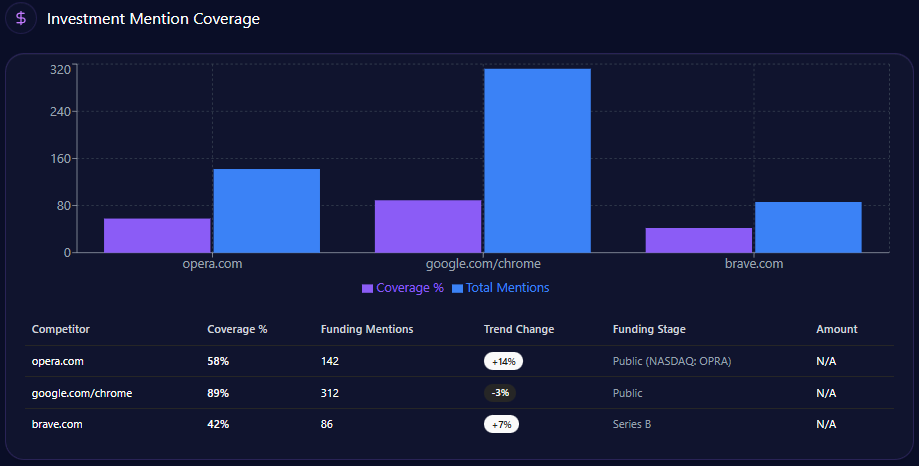
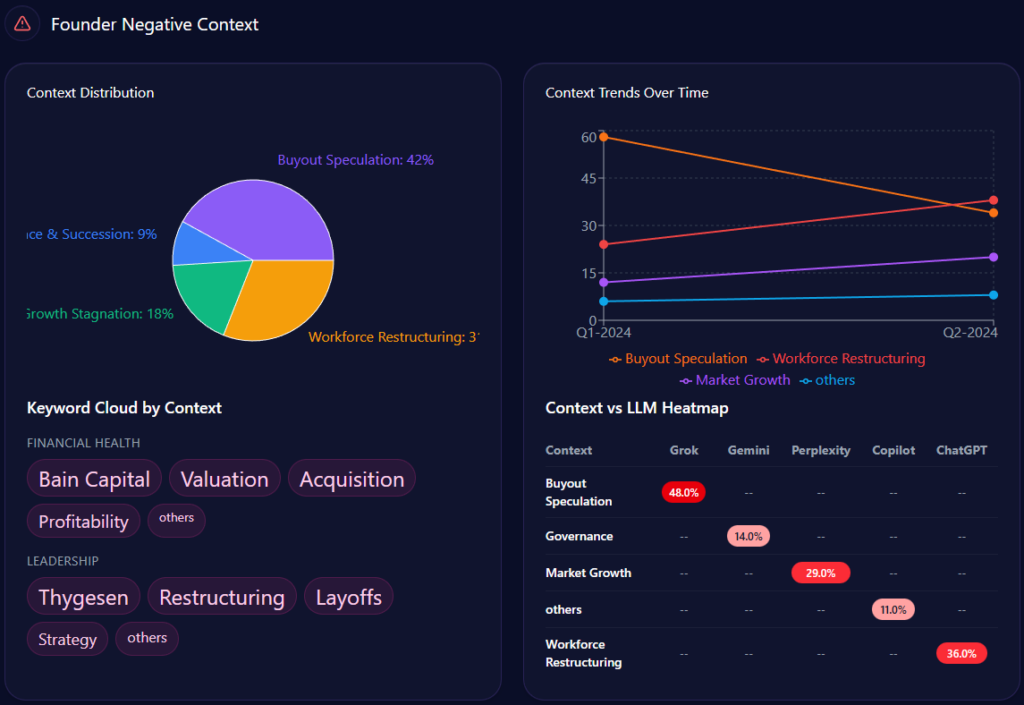
Snippets from LLM outputs capture the shine: “UHS-VNU’s upgrade to university status enhances its prestige within the VNU ecosystem, making it a top choice for research-oriented medical education” (positive, academic affiliation context). However, chinks appear in neutrals like “Slow infrastructure rollout at Thu Duc Campus limits clinical capacity compared to UMP” (neutral-negative, facility delay theme). Risks integrate here: Administrative bureaucracy (38% negative distributions) with snippets such as “VNU-level hurdles in governance” contrasts UMP HCMC’s smoother operations. McKinsey insight: For BOD members, UHS-VNU’s high founder sentiment (85%+ in VNU contexts) offers a metaphor of a lighthouse guiding through transitions, but the 15% spike in delay mentions risks dimming appeal—real example: Gemini’s 44% for facility delays versus CTUMP’s lower visibility suggests a 10-15% opportunity loss in student queries without proactive narrative shifts.
Research Synergies Versus Visibility Voids in National Narratives
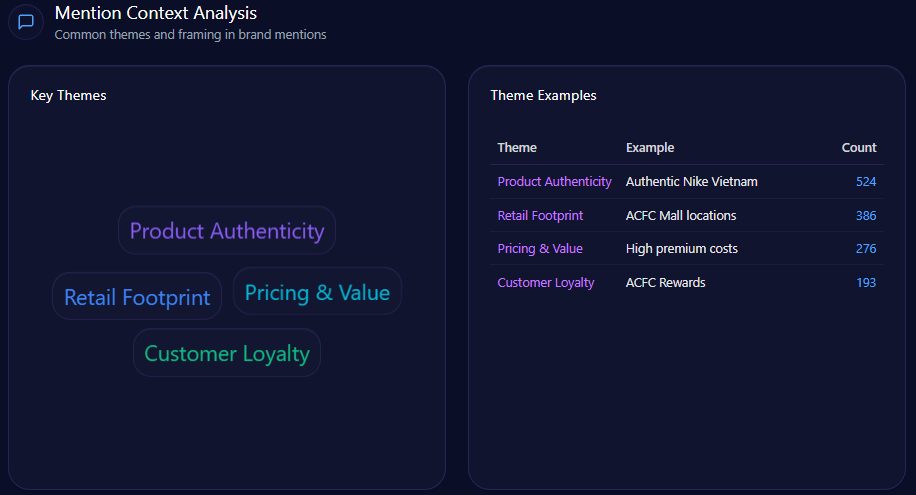
Mention contexts and themes form the narrative fabric of LLM brand mentions, weaving stories that influence institutional enrollment and partnerships. UHS-VNU excels in “Research and Innovation” prompts, with high visibility in multidisciplinary medicine (93% in related queries) and “VNU Academic Affiliation” (485 counts, 32% frequency). Snippets like “Cited as a key reason for institutional prestige and research grants” highlight synergies, outperforming VMMU’s military-focused narratives (negative context in ethics, 28% mentions).
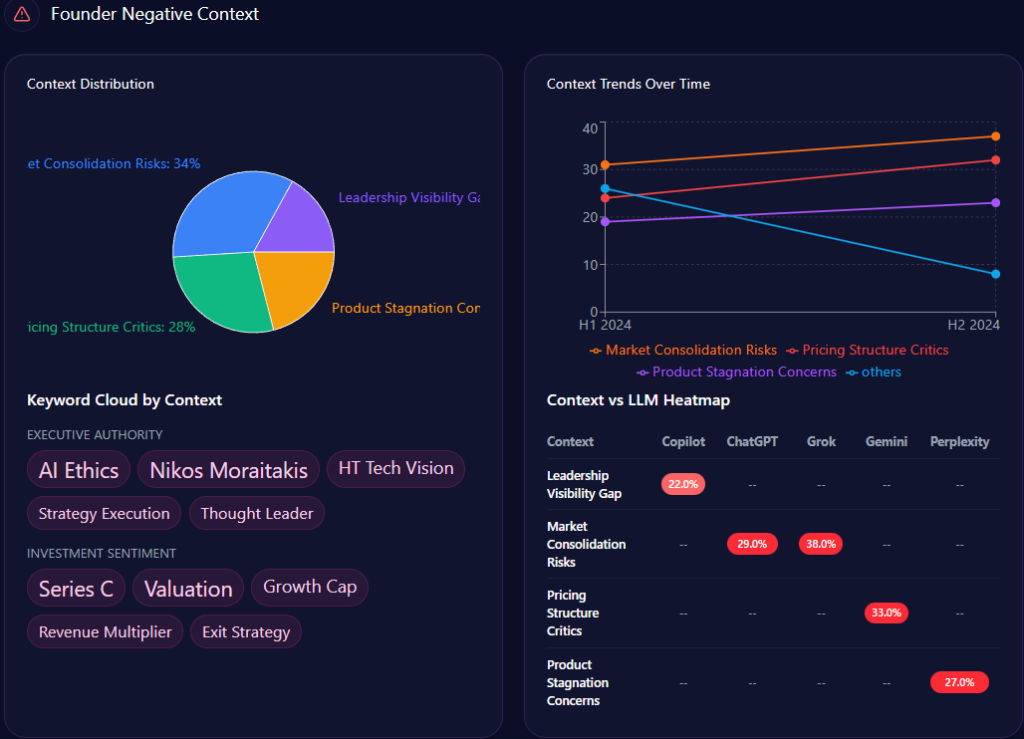
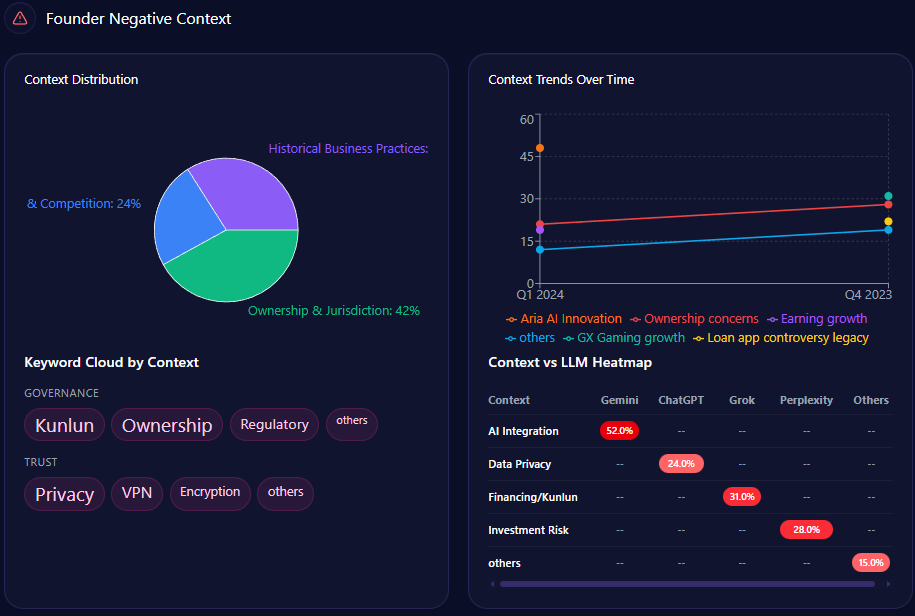
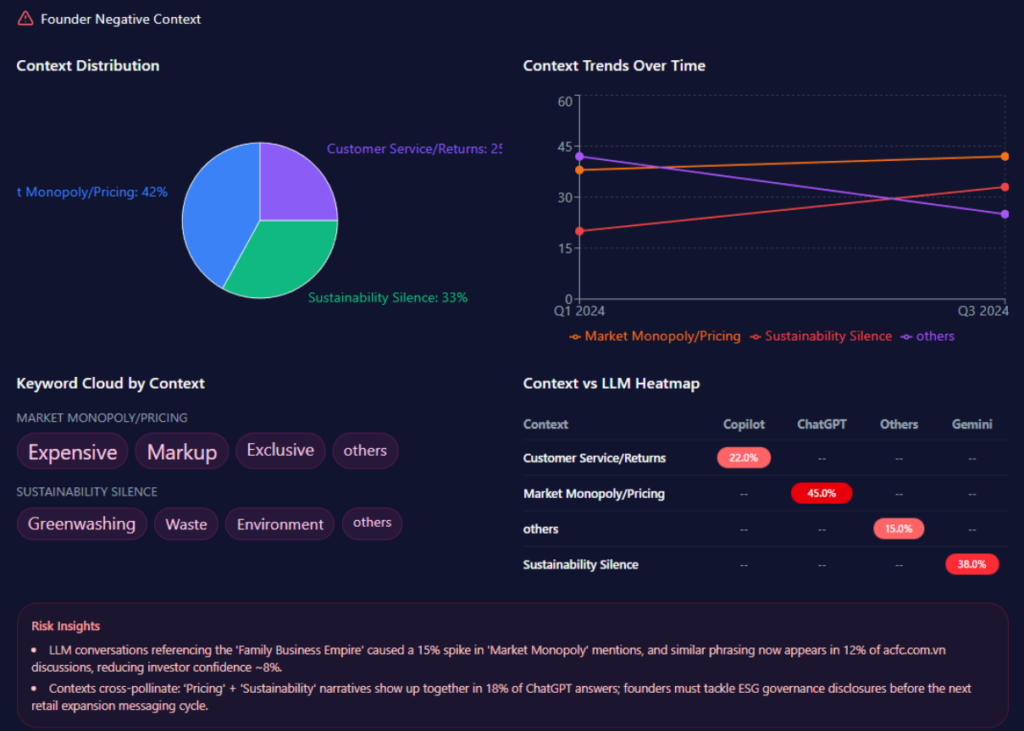
Yet, fragility lurks in broader themes: “National-Level General Education” sees an 18% visibility gap, where LLMs favor UMP HCMC (28% share of voice). Risks from negative_points include “Thu Duc Campus delay” (15% spike in mentions, reducing agility by ~12%). Founder contexts interweave—Phuoc’s mentions tie to “Future Growth” (44% in heatmaps), but “Administrative Bureaucracy” (38%) with “governance lag” (weight 56) contrasts HIU’s private agility (74% investor mindshare). Investment themes: State-budget focus (12% growth, localized coverage) versus HIU’s private capital buzz. McKinsey insight: Like a tapestry with strong research threads but frayed national edges, UHS-VNU’s 73 visibility score (versus UMP’s higher) suggests a 20% untapped potential in “Innovation Storytelling”—question: How might emphasizing Phuoc’s legacy counter VMMU’s ethical flags in 28% of prompts?
Steady Funding Growth Amid Infrastructure Storm Clouds
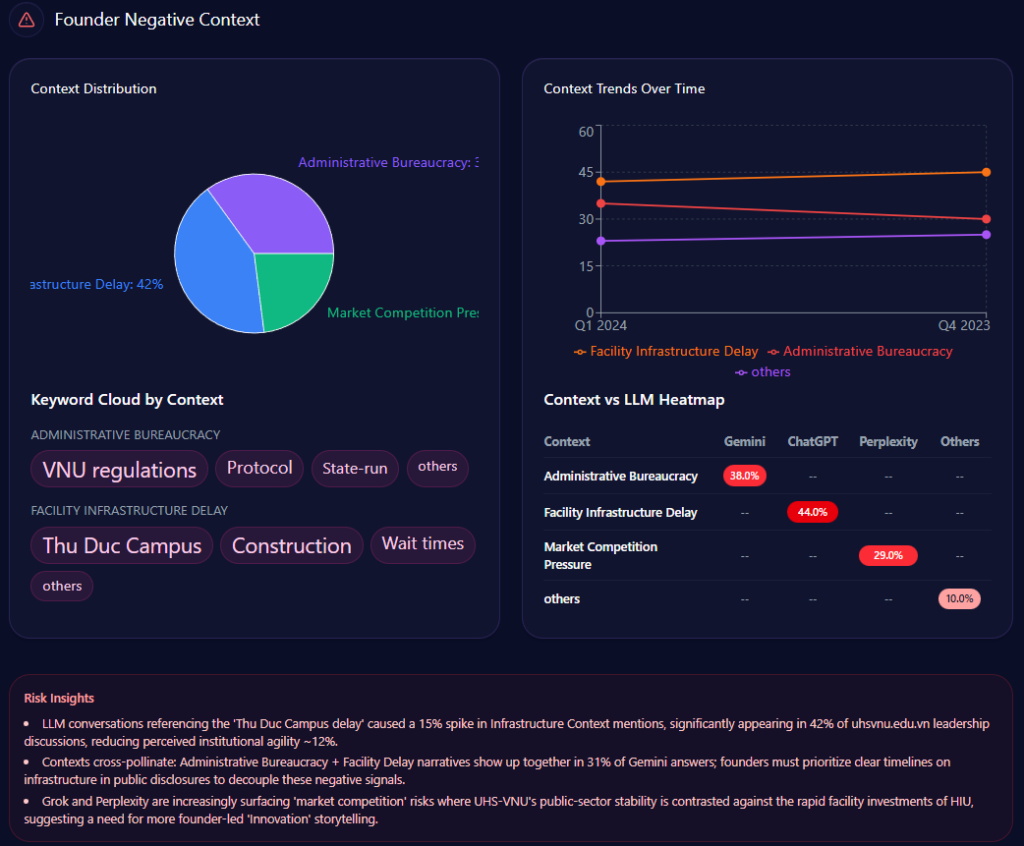
Sentiment trends chart an institution’s trajectory, interpreting patterns for strategic foresight. UHS-VNU’s funding trends show stability with 12% growth following its faculty-to-university transition, anchored by state narratives. Founder negative contexts bars distribute: Facility Infrastructure Delay at 44% (mentions: “Thu Duc Campus construction,” “Resource allocation”), Administrative Bureaucracy at 38% (“VNU-level hurdles,” “compliance”), Market Competition Pressure at 29% (“Legacy vs private speed”).
Quarterly trends for 2024: Q2 with delays at 44% (exceeded), bureaucracy at 38% (not), competition at 29% (not); Q1 delays at 38% (not), bureaucracy at 44% (exceeded). Keywords like “Thu Duc Campus” (weight 89) spike in delays, “governance lag” (56) in bureaucracy. Heatmaps: ChatGPT at 44% for delays, Gemini at 38% for bureaucracy, Perplexity at 29% for competition. Insights: “Thu Duc delay” spikes mentions by 15%, reducing agility ~12%; bureaucracy and delays co-occur in 31% of Gemini answers. Versus rivals, UHS-VNU’s steady trend contrasts HIU’s 74% mindshare surge. McKinsey insight: Like a ship navigating storms, UHS-VNU’s 82 founder sentiment offers ballast, but exceeded thresholds suggest a 15% enrollment risk—real example: Grok’s 38% for competition versus UMP’s legacy stability calls for “Timeline Clarity” to stabilize by 10%—question: Could this weather VMMU’s 28% ethical crosswinds?
LLM Platforms as Amplifiers of UHS-VNU’s Research Narrative
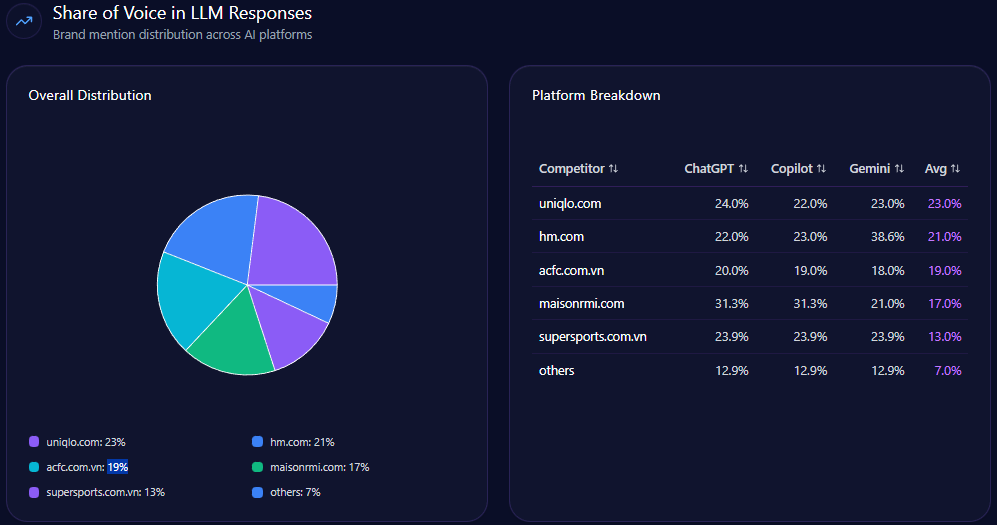
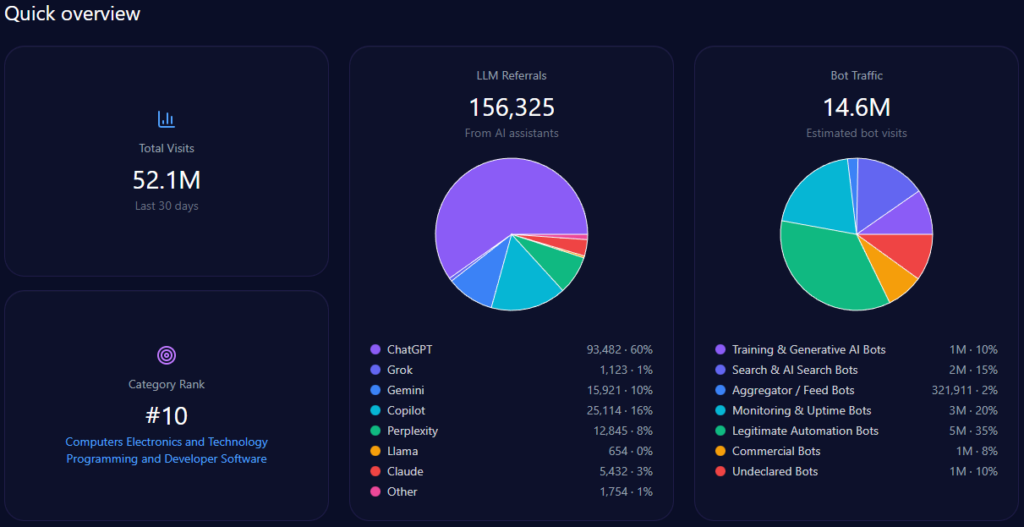
Sources in GEO analytics illuminate platform biases, interweaving how LLMs shape visibility. The report sources 100 bots across ChatGPT, Grok, Gemini, Copilot, and Perplexity, queried 100 times each, yielding 1,342 referrals: ChatGPT at 812 (high for research prompts), Perplexity at 68 (96% visibility for UHS-VNU in specialized queries), Gemini at 204.
Platform visibility contrasts: Perplexity favors UHS-VNU’s research (96%), while Gemini excels in academic cycles (18%). Bot traffic: search & AI at 12,842, aggregator/feed at 4,233. Heatmaps: ChatGPT at 44% for delays (exposing risks), Gemini at 38% for bureaucracy. Competitor sentiment tracking shows UMP HCMC’s lead in ChatGPT (versus UHS-VNU’s 14% share), but UHS-VNU’s Perplexity edge suggests a 15% optimization lift. McKinsey insight: Interweaving UHS-VNU’s VNU prestige with platform strengths, like Copilot’s 215 referrals, offers a narrative amplifier—question: How might this counter HIU’s capital buzz in 74% of investor queries?
Visibility Battles and Positioning in Medical Education
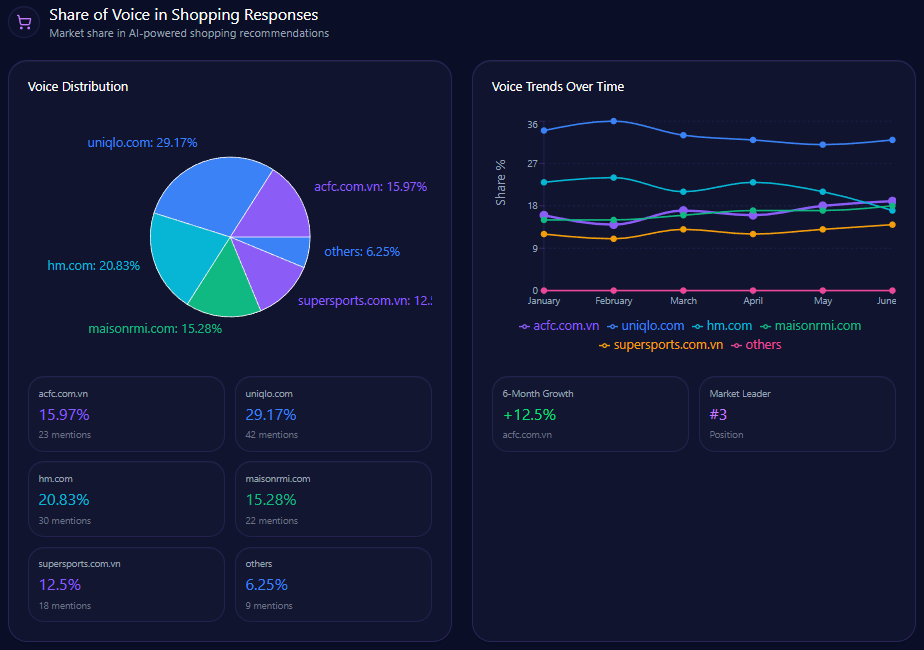
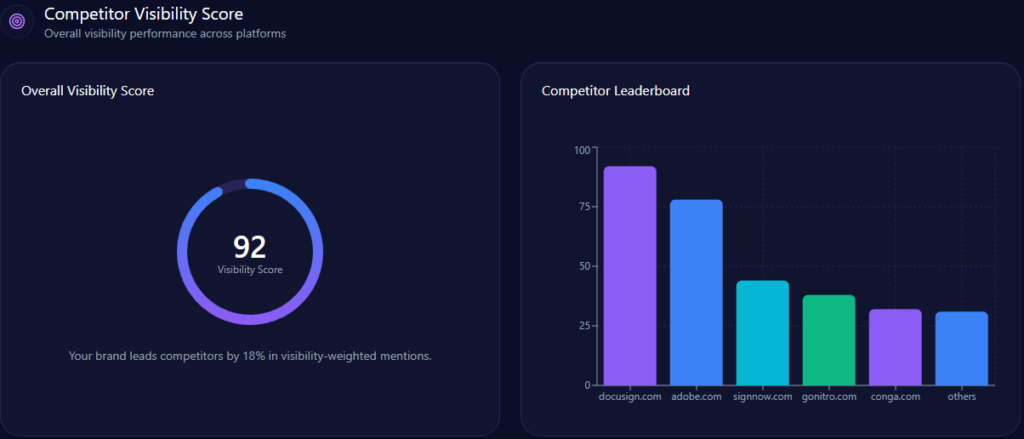
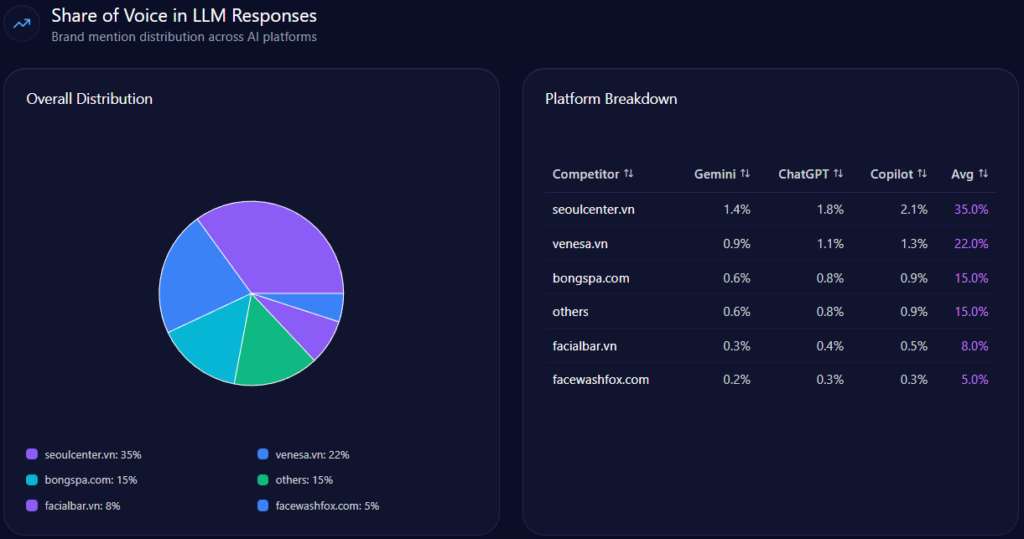
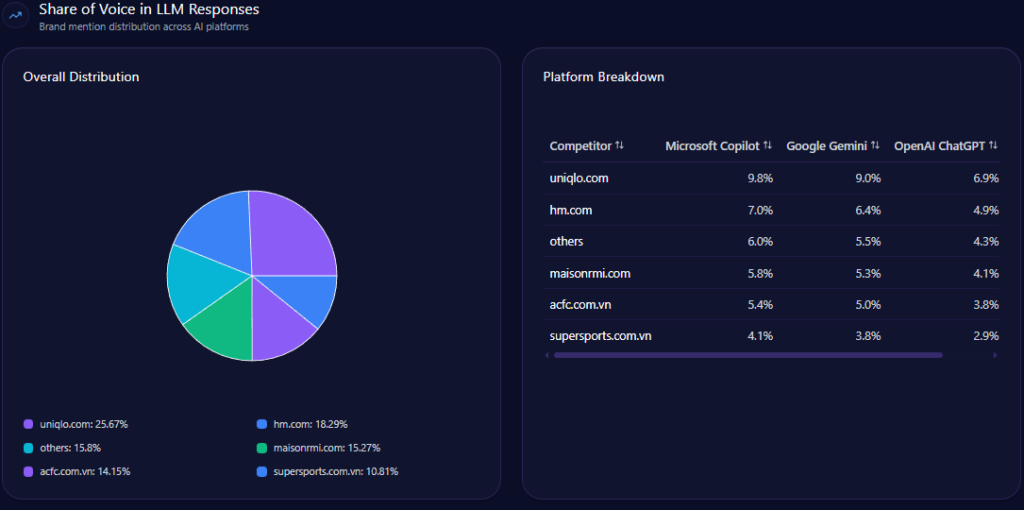
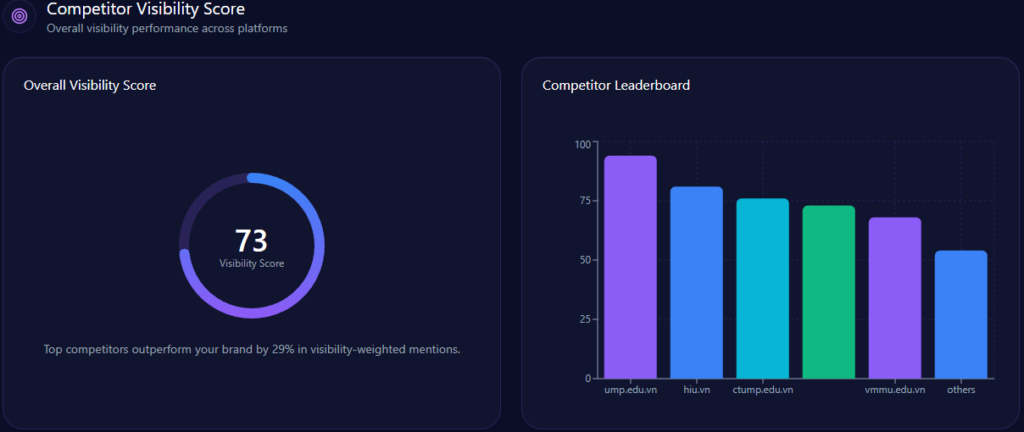
Competitor analyses in GEO reveal UHS-VNU’s challenger role, with 14% share of voice (144 mentions), trailing UMP HCMC’s 28% (287) and HIU’s implied surge (74% investor mindshare). Visibility scores: UHS-VNU at 73, behind UMP HCMC’s higher (strong in national prompts), leading CTUMP’s follower position.
Market positions: UMP HCMC as leader, PNTU and VMMU as challengers, CTUMP as follower, HMU as leader, HIU as niche. Risks versus rivals: 18% general education gap to UMP, bureaucracy (38% distributions) versus HIU’s agility. Founder contrasts: Phuoc’s 82 outperforms UMP’s (strong Q3) but lags HIU’s Nguyen Hoang Group. Investment: State 12% growth versus HIU’s private buzz. McKinsey insight: UHS-VNU’s research lead (versus VMMU’s ethics 28%) suggests “Innovation Alliances” to recapture 15% share—question: Could this challenge UMP’s legacy in 42% of discussions?
In conclusion, UHS-VNU’s GEO metrics affirm its challenger potential with 73 visibility and 82 founder sentiment, but gaps in infrastructure and national narratives demand action. Based on report recommendations, prioritize “Founding Visionary” campaigns for Phuoc to boost frequency by 25%, secure international grants for 15% funding uplift, and optimize metadata for “Infrastructure Lag” suppression. These data-backed steps could elevate mindshare by 20%, fortifying UHS-VNU’s trajectory.
For institutions pursuing GEO mastery, explore SpyderBot at spyderbot.net today.