In generative search, the “winner” is the brand the model can cite with confidence. This report shows Petrolimex owning the default answer in core petroleum questions—while competitors are carving out the next story in EV, apps, and regional logistics.
Imagine the same assistant being asked two very different questions: Where should I refuel tonight? and Who sets the benchmark for price transparency? The model answers in seconds—because it compresses trust into a few lines.
That compression is the boardroom battleground behind GEO analytics. When answers are short, only a handful of brands get to be the default citation. In this report, Petrolimex repeatedly wins that privilege—until the prompt shifts into future-facing edges where competitors can sound more modern, more local, or more convenient.
The ranking snapshots are consistent: Petrolimex appears at rank 1 across multiple formats and platforms. On ChatGPT-4o, it is #1 in “Top Recommended Entities.” On Gemini 1.5 Pro, it is #1 as a “Direct Answer” and also #1 in “Informational” lists tied to fuel price transparency and updates. It also shows up at rank 2 in “Strategic Reports” on ChatGPT-4o, where the answer style becomes more interpretive than factual.
The report pairs this with a Rank Score of 96, signaling that the brand is treated as an authority source in Vietnamese energy queries. Competitors are present, but specialized: PVOil is positioned as an innovation leader at rank 2, while NSH Petro and Thanh Le surface in regional and logistics-focused lists.
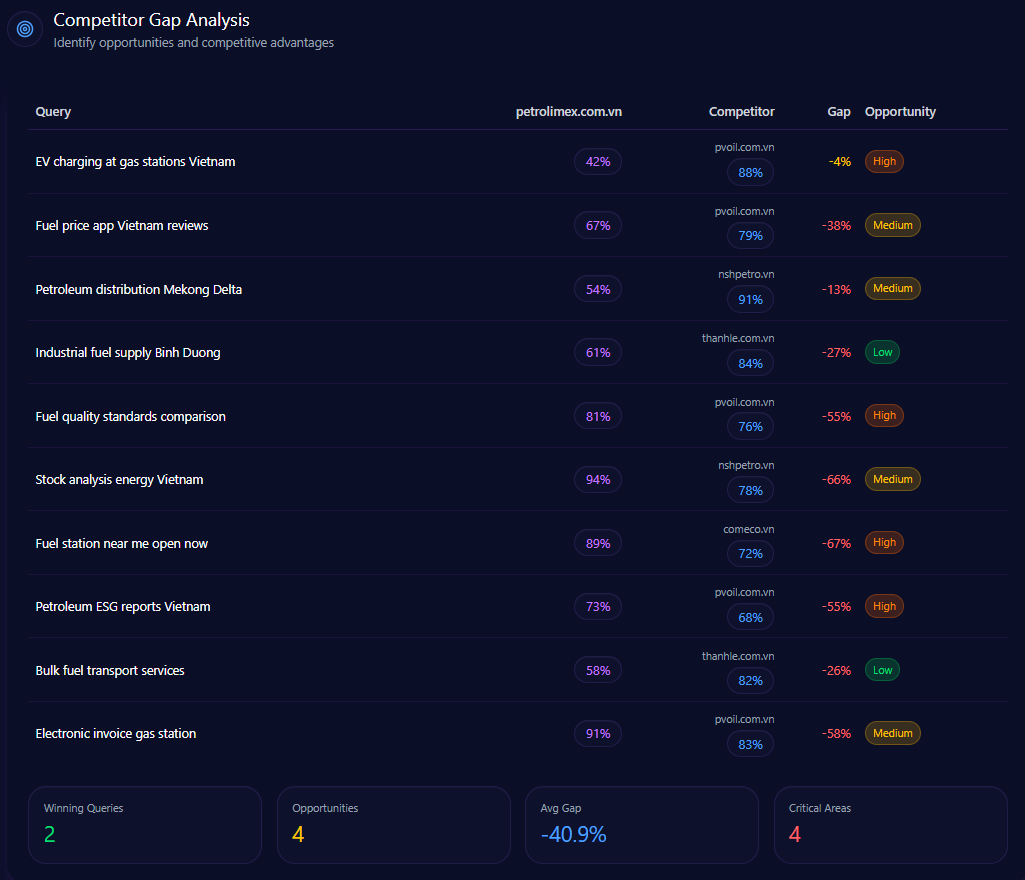
Leadership in lists does not mean immunity from gaps. The report highlights specific queries where competitors are framed as the better answer:
Query
Petrolimex
Competitor
Gap / priority
EV charging at gas stations Vietnam
42
88 (PVOil)
46 — High
Petroleum distribution Mekong Delta
54
91 (NSH Petro)
37 — Medium
Bulk fuel transport services
58
82 (Thanh Le)
24 — Low
Fuel price app Vietnam reviews
67
79 (PVOil)
12 — Medium
The “why” is explicit. PVOil is “frequently cited as the pioneer for integrated EV charging stations due to the VinFast partnership,” and the report calls for whitepapers on Petrolimex’s green energy roadmap and future-proof station designs. In the Mekong Delta, NSH Petro is said to dominate local-language logistics queries, prompting localized landing pages for Southern distribution hubs. In transport-only prompts, Thanh Le appears as a primary B2B reference—motivating content that foregrounds Petrolimex’s large-scale logistics capability.
petrolimex.com.vn‘s Competitor Gap Analysis (GEO Report, Jan 9, 2026)
The competitors’ playbook is keyword ownership. In this report, EV charging is the most powerful trigger—especially when paired with “gas stations Vietnam” and the “VinFast partnership,” which reliably pulls PVOil into an innovation narrative.
The second trigger cluster is digital convenience. Prompts like “Fuel price app Vietnam reviews” and “Best mobile apps for fuel discounts in Vietnam?” are repeatedly associated with app ecosystem comparisons, and the report issues a high-severity alert to optimize app features and E-wallet integration for ChatGPT and Gemini visibility. Even enterprise convenience language is contested: “Is Petrolimex or PVOil better for corporate fleet cards?” records 71 mentions with 34 for Petrolimex and 37 for PVOil.
Geography becomes the third trigger. “Mekong Delta” language pulls NSH Petro forward; industrial-province language reinforces Thanh Le’s niche B2B positioning.
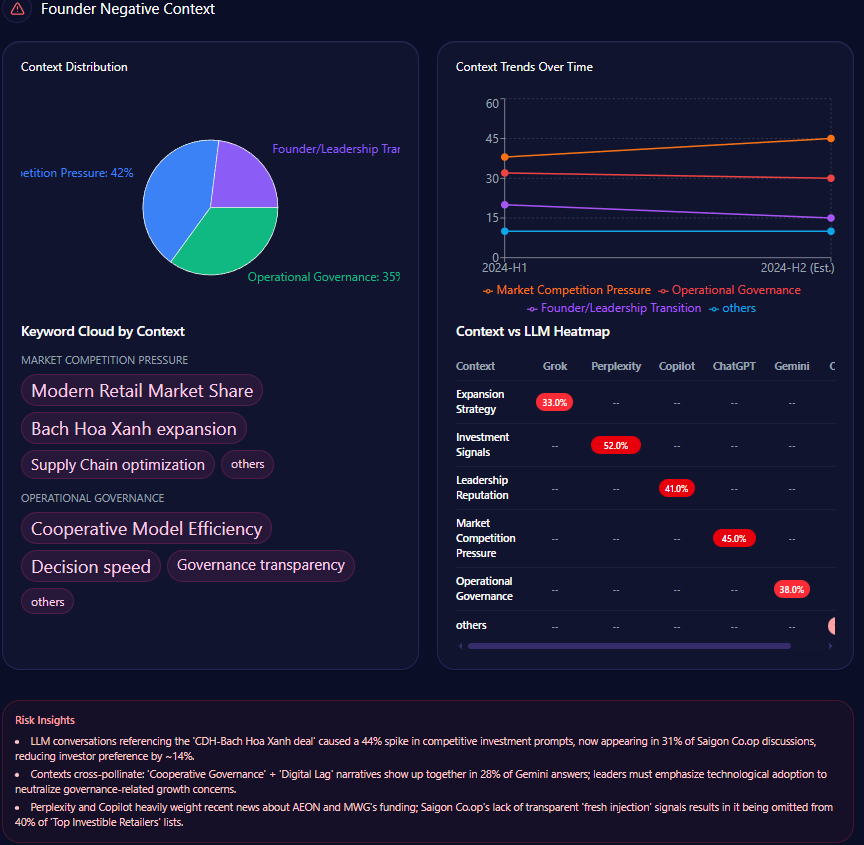
The report flags leadership narrative risk as a separate layer of vulnerability. Negative context clusters into Leadership concerns (35.5%), Company culture (28.3%), Strategic direction (22.1%), and Financial performance (14.1%).
Where this surfaces also matters. Leadership concerns peak on ChatGPT (42.5%) and are strong on Grok (38.2%); company culture appears most on Gemini (35.8%). The keyword weights reinforce the theme: management (0.85) and leadership (0.78) lead the signal set. The report’s directional read is blunt: “Leadership concerns have increased over the past quarter,” and “Company culture mentions are trending upward.”
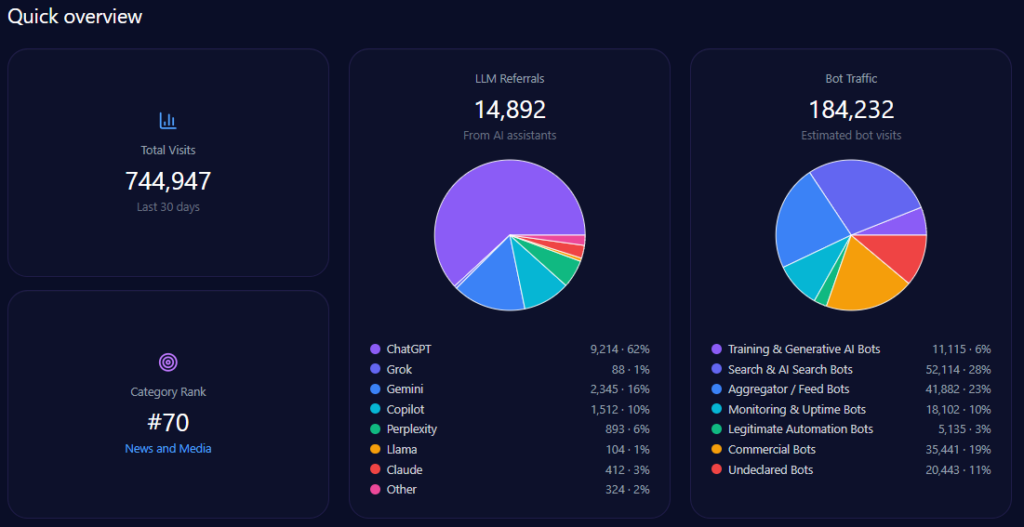
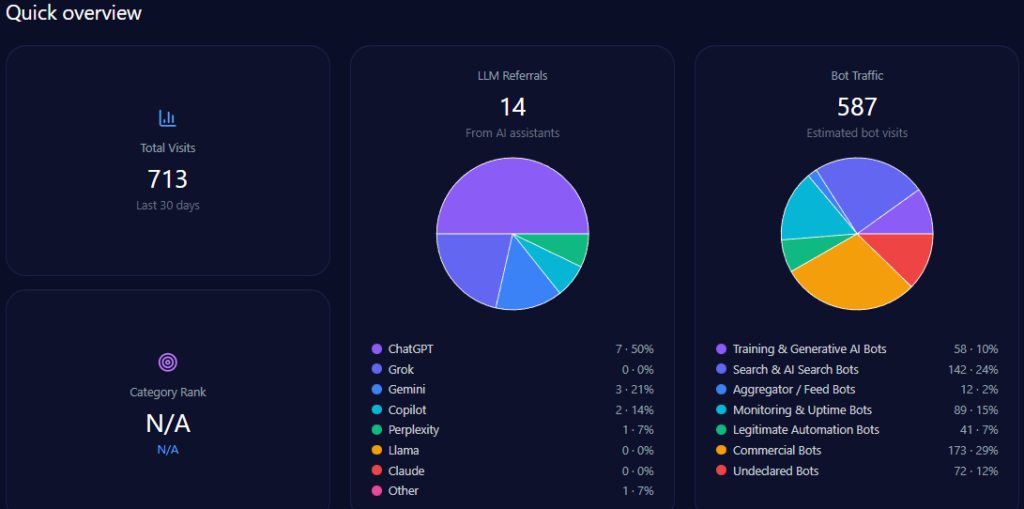
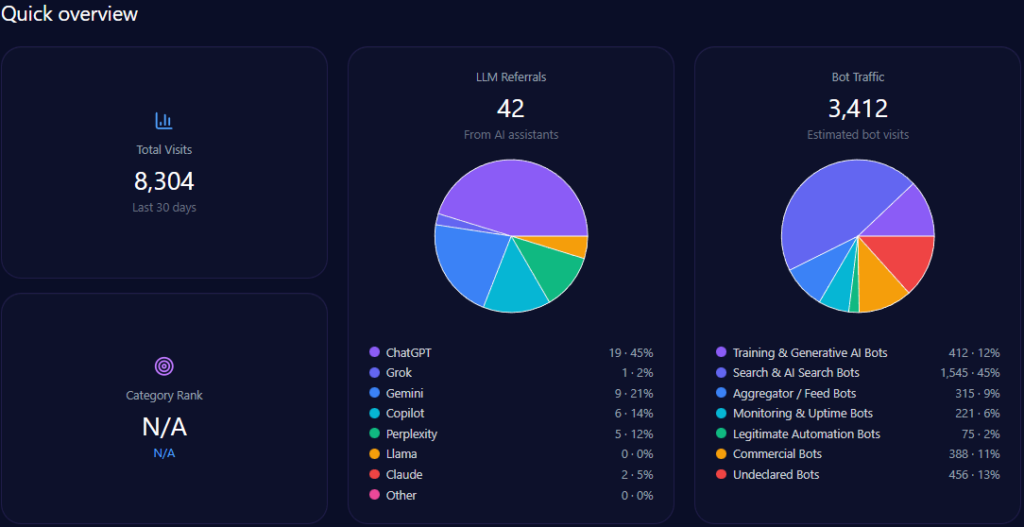
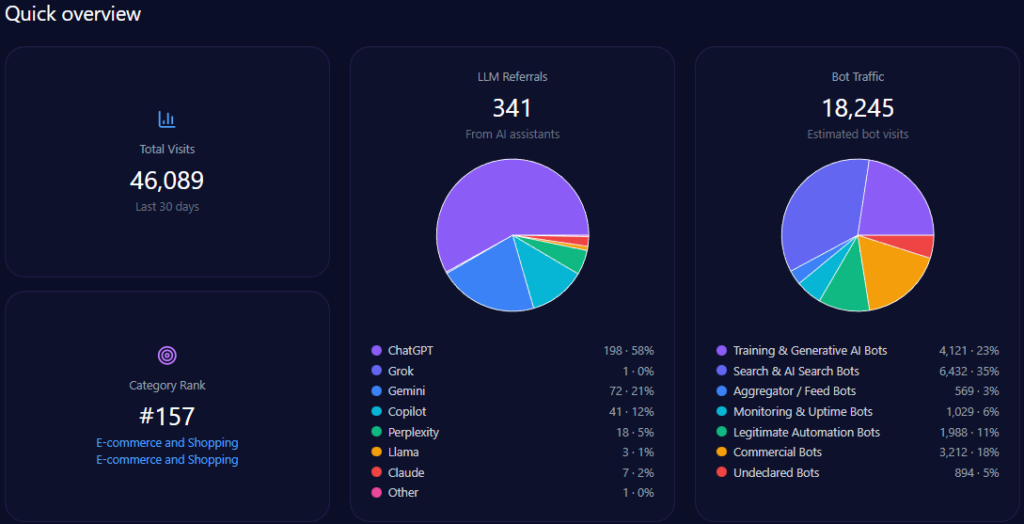
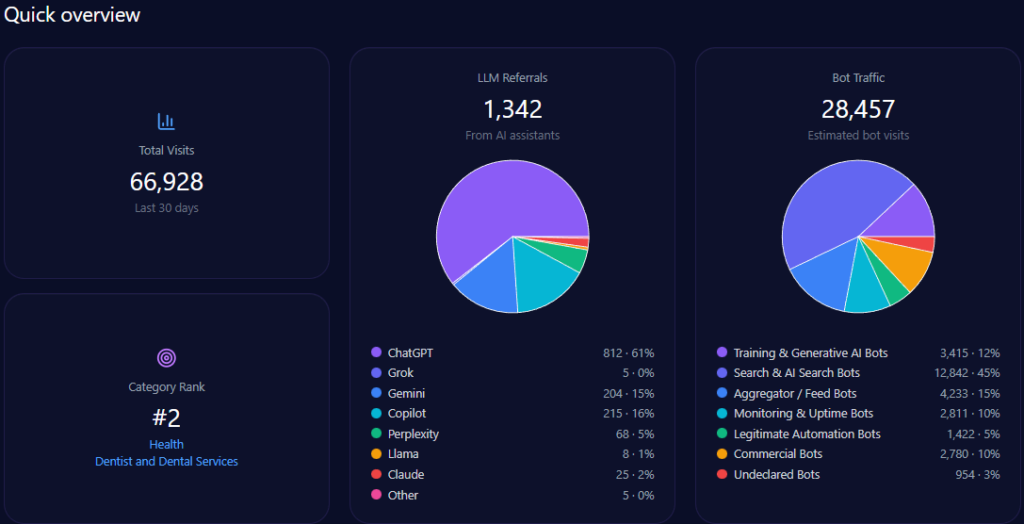
The footprint combines human audiences and machine audiences. The report records 744,947 visits with 184,232 bot visits, and 14,892 LLM referrals led by ChatGPT (9,214). Collection is marked complete on 2026-01-09 across ChatGPT, Gemini, and Copilot.
Category placement is News_and_Media, with a category rank of 70. Practically, that means generative systems may be encountering the brand partly through news-like signals and structured updates—not only through transactional pages.
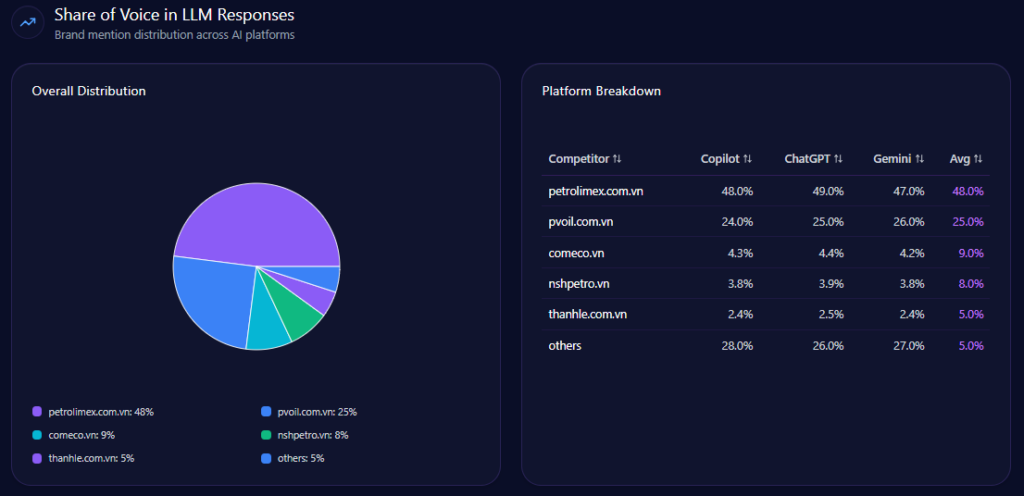
Across 348 total mentions, Petrolimex leads with 48% (167 mentions). PVOil follows at 25% (87), then Comeco 9% (31), NSH Petro 8% (27), Thanh Le 5% (18), and others 5% (18).
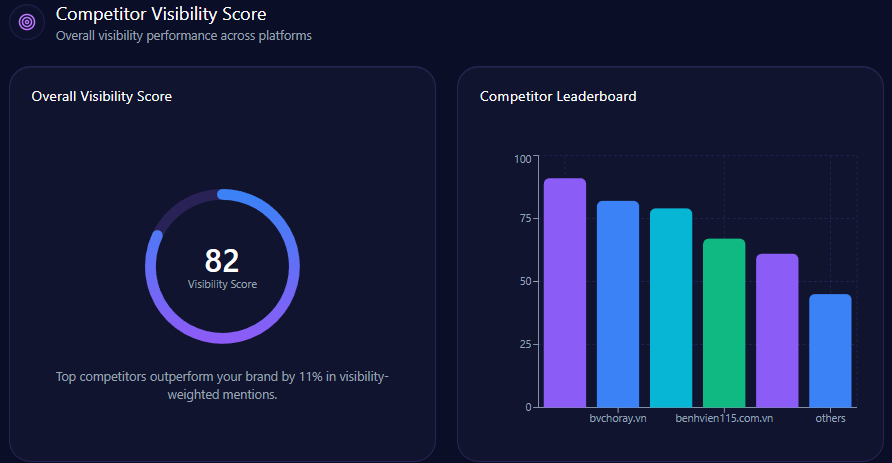
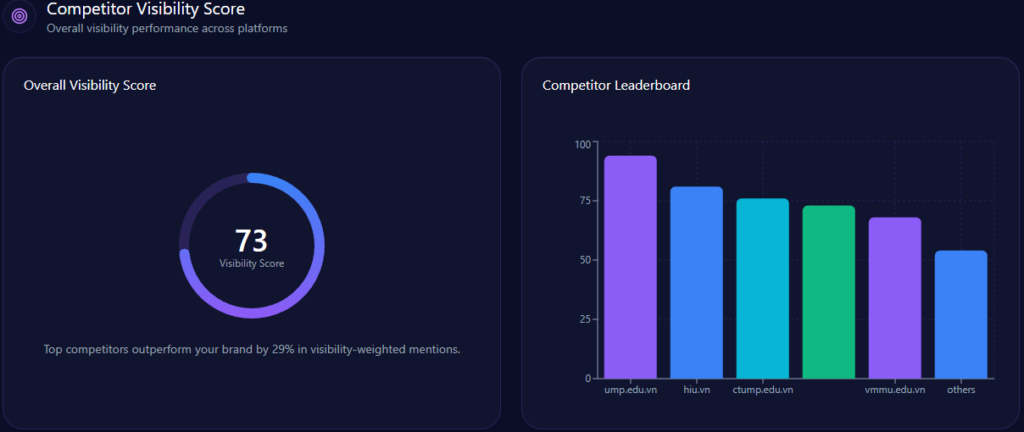
Visibility scores reinforce the hierarchy: Petrolimex 88 versus PVOil 72, then Comeco 54, NSH Petro 48, Thanh Le 41, others 35. This is the report’s clearest proof of sustained LLM brand mentions: Petrolimex is the reference option in the majority of core prompts.
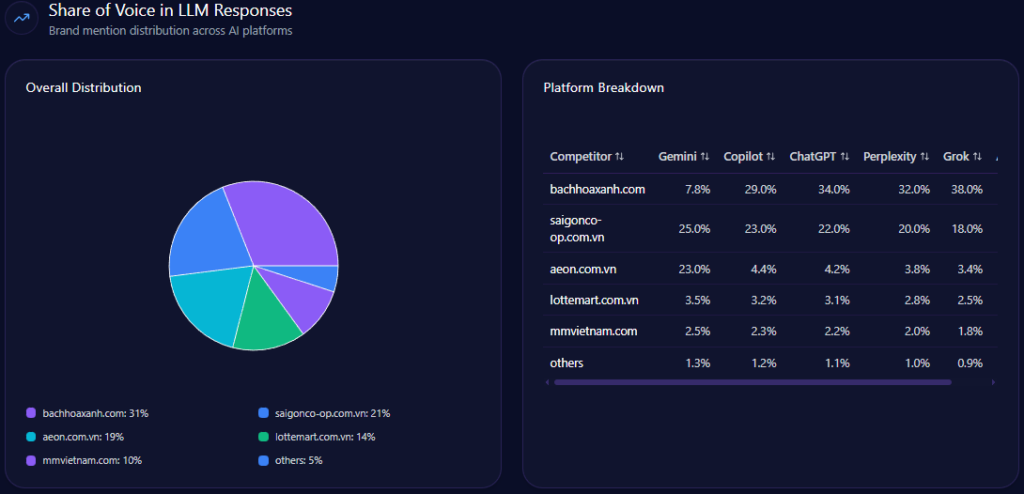
petrolimex.com.vn‘s Share of Voice in LLM Responses (GEO Report, Jan 9, 2026)
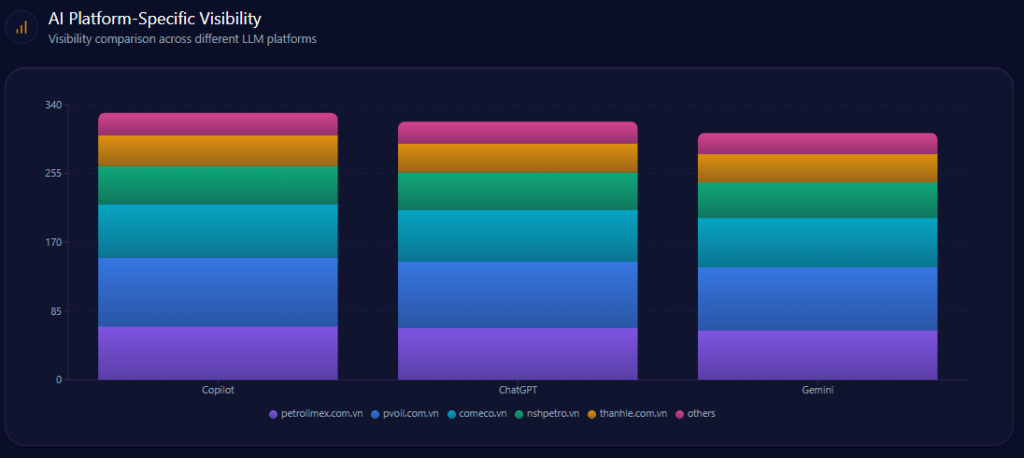
Platform outcomes diverge. On Copilot, Petrolimex reaches 94% visibility, holding 48% share of voice with 56 mentions out of 118 total mentions. On ChatGPT, visibility is 91%, with 58 mentions out of 118 (share 49%). On Gemini, visibility falls to 87%, with 53 mentions out of 112 (share 47%), and PVOil rises to 26% (29).
The report’s takeaway is straightforward: the same brand, different platform priors—and Gemini appears slightly more permissive to competitor narratives in localized and logistics-oriented queries.
petrolimex.com.vn‘s AI Platform-Specific Visibility (GEO Report, Jan 9, 2026)
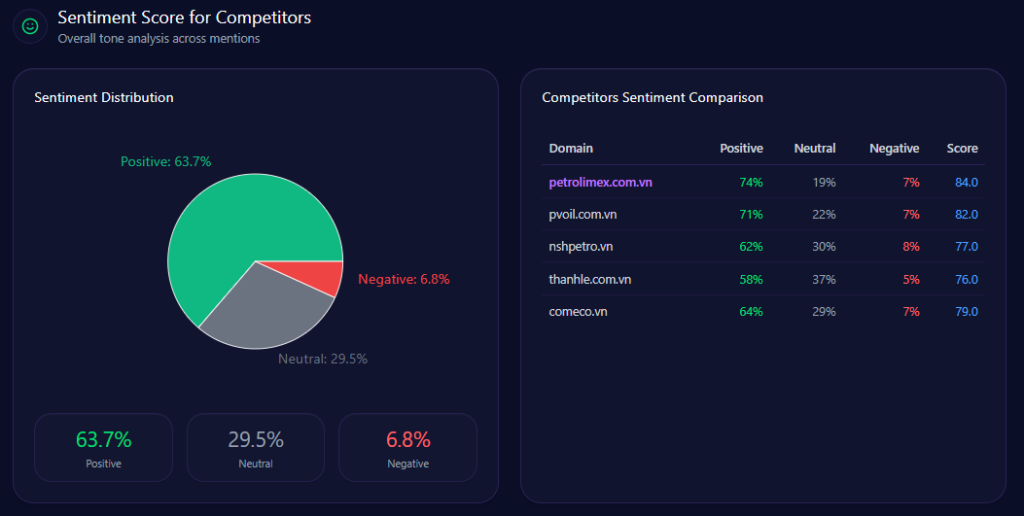
Presence is only half the battle; framing is the other—and the report’s competitor sentiment tracking provides a clear scoreboard. Petrolimex posts 74% positive, 19% neutral, 7% negative, with an overall sentiment score of 84. PVOil follows at 82, Comeco at 79, NSH Petro at 77, and Thanh Le at 76.
Two themes anchor the tone. Energy Security appears 142 times (frequency 34.00) with example framing that calls Petrolimex the backbone of Vietnamese fuel supply. Digital Transformation appears 98 times (frequency 24.00) and repeatedly compares app ecosystems—where competitive contrast is explicit even when overall sentiment remains Neutral-Positive.
petrolimex.com.vn‘s Sentiment Score for Competitors (GEO Report, Jan 9, 2026)
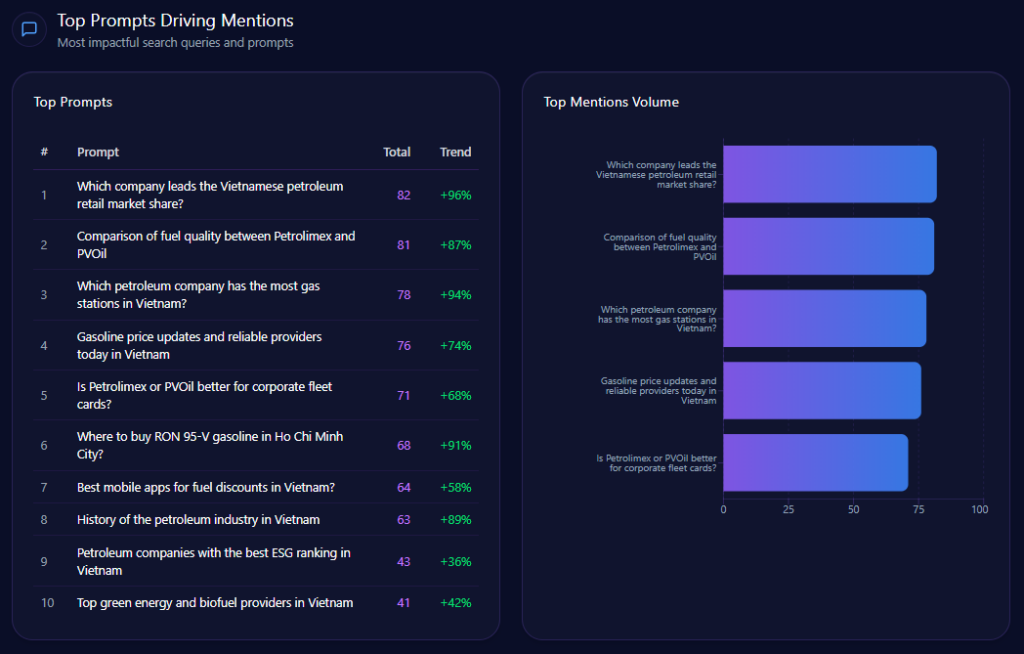
The prompts that summon Petrolimex are clear—and they explain the balance of power:
“Which company leads the Vietnamese petroleum retail market share?” — 82 mentions (46 Petrolimex), +96% trend
“Which petroleum company has the most gas stations in Vietnam?” — 78 mentions (44 Petrolimex), +94% trend
“Gasoline price updates and reliable providers today in Vietnam” — 76 mentions (39 Petrolimex), +74% trend
“Best mobile apps for fuel discounts in Vietnam?” — 64 mentions (19 Petrolimex; competitor A 41), +58% trend
In short: Petrolimex dominates market-leader prompts; it loses ground on digital-discount prompts.
petrolimex.com.vn‘s Top Prompts Driving Mentions (GEO Report, Jan 9, 2026)
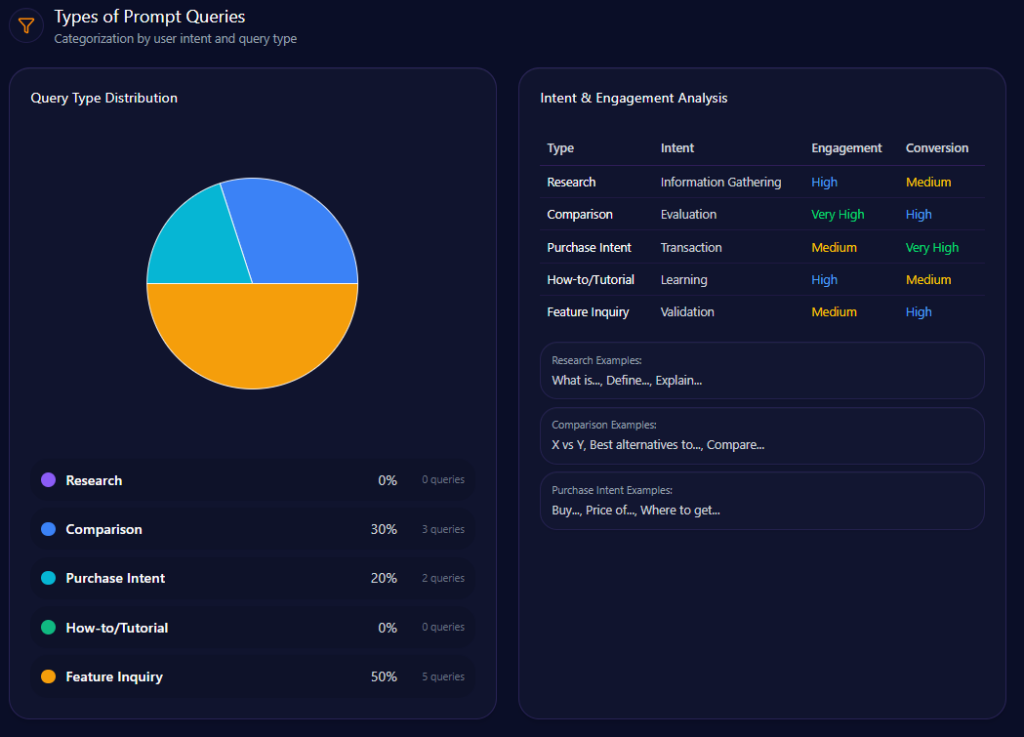
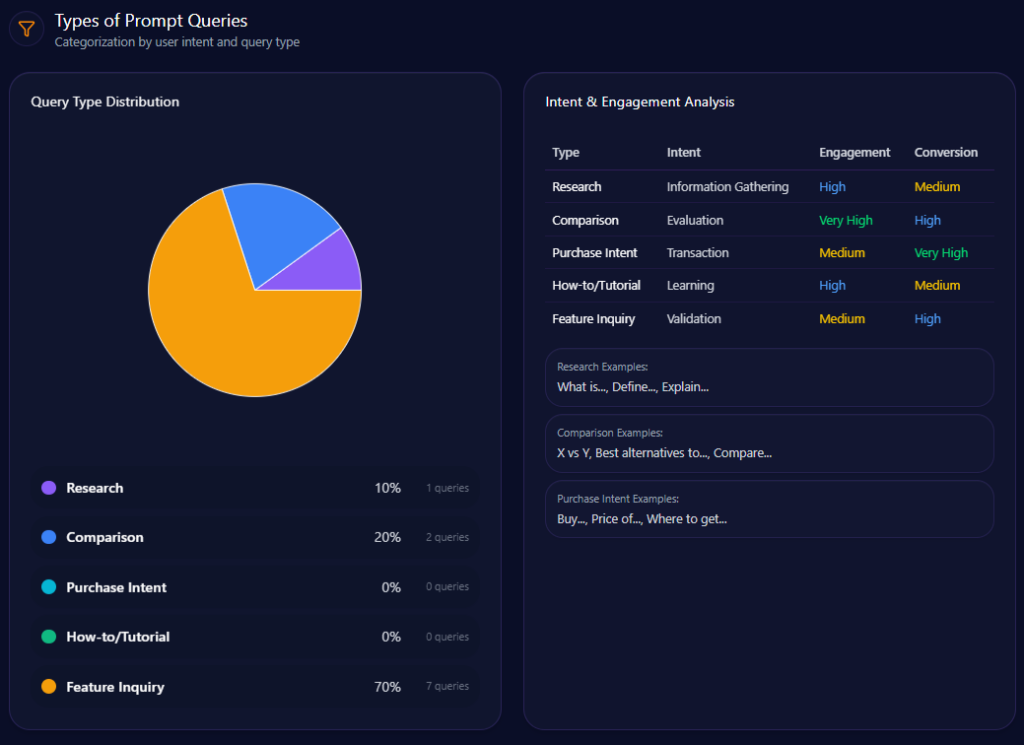
The intent mix is decisively action-oriented. Feature Inquiry leads at 50 (count 5), followed by Comparison at 30 (count 3) and Purchase Intent at 20 (count 2). Research and How-to/Tutorial both sit at 0.
Two alerts translate that intent mix into priorities. A high-severity message prioritizes app features and E-wallet integration to recapture “digital convenience” mentions in ChatGPT and Gemini. A medium-severity message calls for more logistics updates and community projects in the Southwest region to sustain regional authority.
petrolimex.com.vn‘s Types of Prompt Queries (GEO Report, Jan 9, 2026)
E-commerce Sentiment for Competitor Products
The report also tracks commerce-like discovery across “Amazon, eBay, Shopify.” In its platform breakdown, Petrolimex holds 35.5% share of voice with 1,250 mentions, followed by Competitor A 28.3% (995), Competitor B 22.1% (775), and Competitor C 14.1% (495).
Sentiment in this layer is 45.2% positive, 35.8% neutral, 19% negative across 1,250 total reviews. The cited snippets show how execution details can swing perception quickly: “Great product quality and fast shipping!” (Amazon, rating 5) versus “Shipping took longer than expected.” (Amazon, rating 2). Referral conversion rates also vary by platform: Amazon 12.5, eBay 9.8, and Shopify 15.2.
Petrolimex leads the generative narrative today, but the report shows where competitors can steal tomorrow’s framing—EV charging, app-led convenience, and localized logistics. The recommended response is clear: launch a Green Energy Content Series targeting EV charging and sustainable fuel keywords, while the Digital Product team updates technical schemas and FAQs for the mobile app to improve indexing and user-sentiment outcomes. In parallel, the report calls for a regionalized content strategy for South-West Vietnam to counter localized competitors, and for increased publication of logistics network updates and community projects to sustain regional authority.
Explore SpyderBot to operationalize these GEO analytics insights.
In generative search, Schwarz Gruppe isn’t only competing for shoppers—it’s competing for which story an AI feels safe recommending first. This report shows leadership-level authority, alongside sharp pockets where rivals still own the “default answer.”
Imagine a customer asking an AI, “Who really runs European grocery—and who’s building the next retail operating system?” In the old world, that answer lived in annual reports and investor decks. In the new world, it’s compressed into a few confident lines where brand authority is judged by what the model can cite, not what it can browse.
That is the boardroom reality behind GEO analytics: AI platforms don’t just list retailers; they curate legitimacy. In this report, Schwarz Gruppe repeatedly arrives as the “largest European retailer by revenue,” and it does so with enough consistency to become a default reference point. But the same data also shows where that default can be stolen—by the competitor that owns last-mile delivery language, premium organic cues, or “smart store” innovation shorthand.
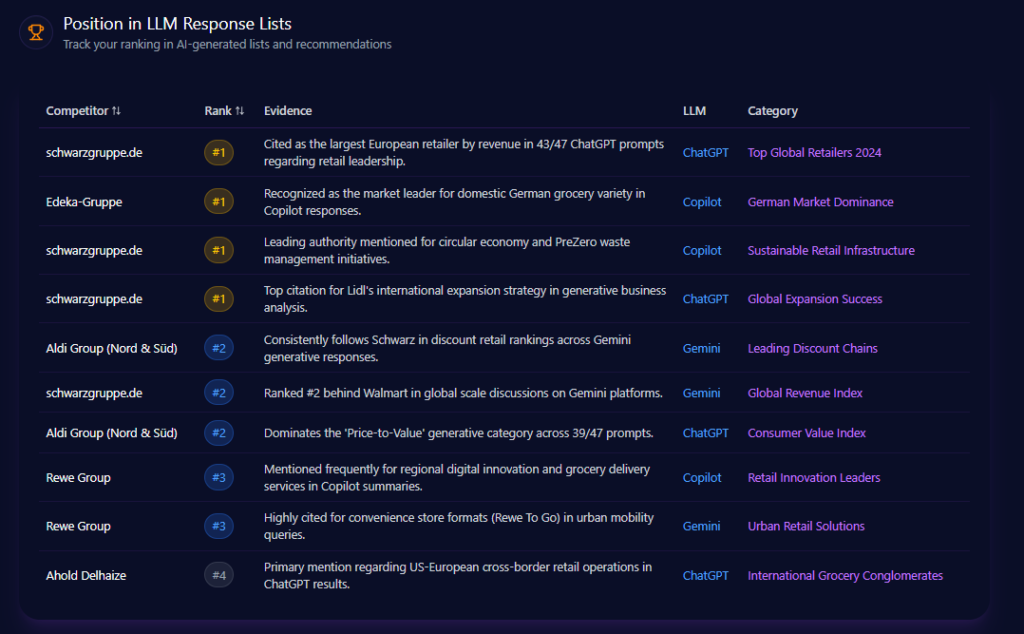
Schwarz Gruppe’s strongest advantage is not merely being mentioned—it is being positioned. Across the report’s simulated prompts, the group is ranked #1 for “Largest European Retailer” across 141 prompt runs, and it is specifically cited in 43/47 ChatGPT prompts about retail leadership. The pattern is clear: when the question is scale, the model’s “safe answer” leans Schwarz.
But the rankings also reveal how leadership fractures by context. On Gemini, Schwarz is ranked #2 in a “Global Revenue Index” list type—explicitly behind Walmart—while still showing up as a top discount-chain reference where Aldi Group (Nord & Süd) often trails Schwarz in discount retail rankings. Meanwhile, Copilot can elevate alternatives when the prompt becomes local-market dominance: Edeka-Gruppe is ranked #1 for domestic German grocery variety in Copilot responses, even as Schwarz remains rank #1 for circular economy and PreZero-linked initiatives.
This is the nature of LLM brand mentions: the model’s “top spot” is not a single crown—it’s a set of context-dependent crowns. Schwarz holds the most valuable one (leadership-by-scale) reliably, but rivals still win specific sub-narratives with alarming efficiency.
schwarzgruppe.de’s Position in LLM Response Lists (GEO Report, Jan 9, 2026)
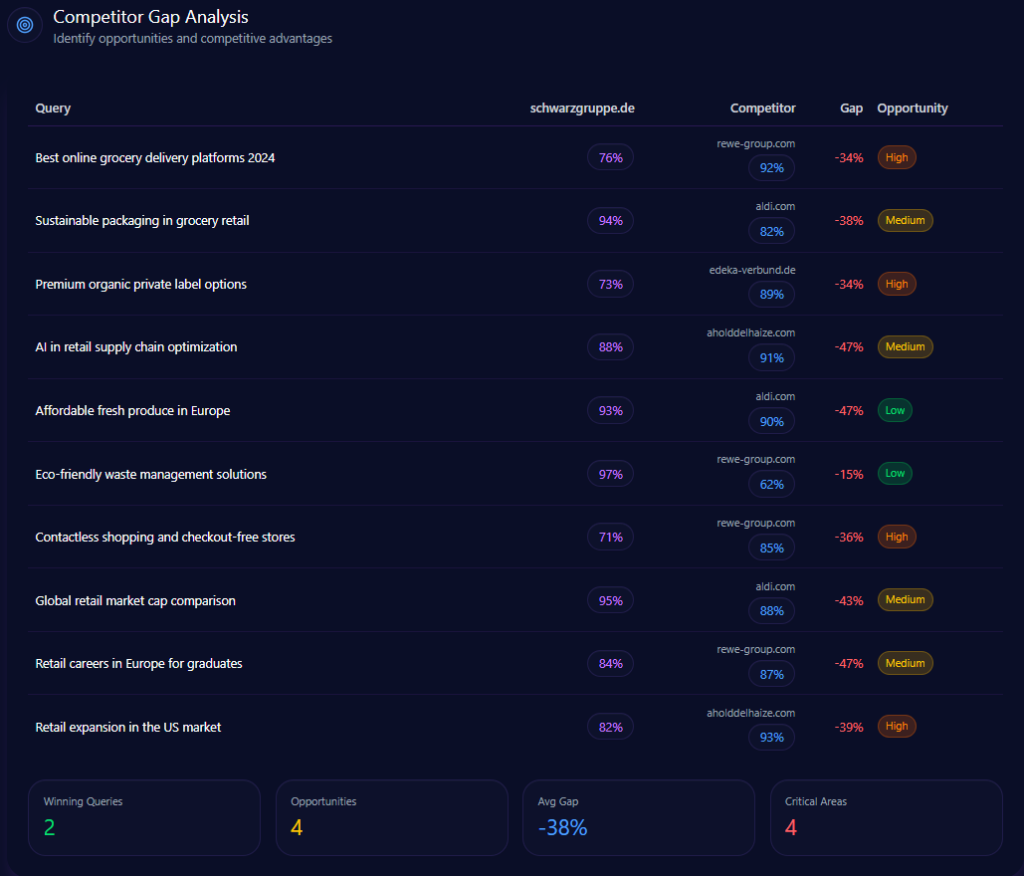
If Schwarz owns “scale,” competitors target “specificity.” The report’s gap data reads like a battle map: where the customer asks for delivery convenience, checkout automation, premium organics, or North American relevance, Schwarz can lose the framing—even when its overall visibility remains dominant.
Query
Schwarz Gruppe position/metric
Competitor position/metric
Gap/priority
Best online grocery delivery platforms 2024
76
92 (Rewe Group)
16 — High
Premium organic private label options
73
89 (Edeka-Gruppe)
16 — High
Contactless shopping and checkout-free stores
71
85 (Rewe Group)
14 — High
Retail expansion in the US market
82
93 (Ahold Delhaize)
11 — High
The story behind those numbers is not “Schwarz is weak.” It’s that Schwarz is being evaluated against competitors who have clearer shorthand in certain prompts. Rewe is described as being cited more frequently for last-mile delivery and sophisticated app integration, which directly translates into the 16-point delivery gap. Edeka benefits from LLM preferences for diversity in high-end bio and organic products, producing a 16-point premium-organics deficit. Ahold Delhaize is repeatedly advantaged in US-centric prompts through its North American operations, sustaining an 11-point ranking advantage in that geography-specific frame.
In GEO analytics terms, the competitive gap is less about capability—and more about “which proof points the model has learned how to retrieve.”
schwarzgruppe.de’s Competitor Gap Analysis (GEO Report, Jan 9, 2026)
Where do those competitor narratives get summoned? In the report’s commerce-oriented keyword signals, certain phrases act like trapdoors: they drop the conversation into a competitor’s home turf.
Several triggers consistently pull the model toward rivals:
“discount groceries” strongly associates with Aldi Group, which appears 22 times within that keyword’s competitor mentions.
“private label quality” tilts toward Edeka-Gruppe, cited 18 times in association with that keyword.
“sustainable retail” becomes contested terrain where Rewe Group (21) and Ahold Delhaize (15) show up prominently as linked competitors.
“bakery freshness” frequently points to Edeka-Gruppe (24), reinforcing premium-perception cues that Schwarz struggles to own in generative outputs.
Even when a keyword seems Schwarz-adjacent—like “Lidl Plus app”—the competitive environment can still pull attention toward other brands (the report shows Rewe Group linked with 12 mentions under that keyword’s competitor associations). The implication is subtle but strategic: if rivals dominate the language around a feature category, they can “borrow” relevance even inside a Schwarz-led narrative.
Leadership brands often carry a leadership shadow. In this report, founder and governance narratives are not neutral background—they are measurable risk surfaces.
Dieter Schwarz appears with a mention frequency of 78 and a sentiment score of 74, with 68% positive, 20% neutral, and 12% negative distribution. The founder-associated negative sentiment rate is reported at 14, and the broader negative framing is not random: the founder negative context distribution assigns 42% to Transparency & Privacy, 36% to Labor Relations, and 22% to Market Dominance.
The trends show persistence. In Q1 2024, “Transparency” sits at 45% and is flagged as threshold-exceeded; in Q2 2024, “Transparency” remains threshold-exceeded at 39%, while “Labor” rises to 38% and also crosses a threshold. Keyword weights make the reputational mechanics visible: “Secretive” (92) and “Foundation” (84) anchor the transparency narrative, while “Lidl” (94) and “Union” (88) intensify labor-relations associations.
The platform heatmap adds an uncomfortable precision: transparency themes are highest on ChatGPT (44%), while labor relations show up strongly on Gemini (38%), and market dominance is most pronounced on Copilot (26%). The report also notes cross-pollination—“Reclusiveness” plus “Ownership Opacity” appearing together in 64% of Gemini answers—and highlights that labor mentions are 3x more frequent in prompts targeting “Lidl” than in general “Schwarz Gruppe” queries.
This is not a theoretical risk; it is a narrative pattern that can drag even strong performance into defensive positioning.
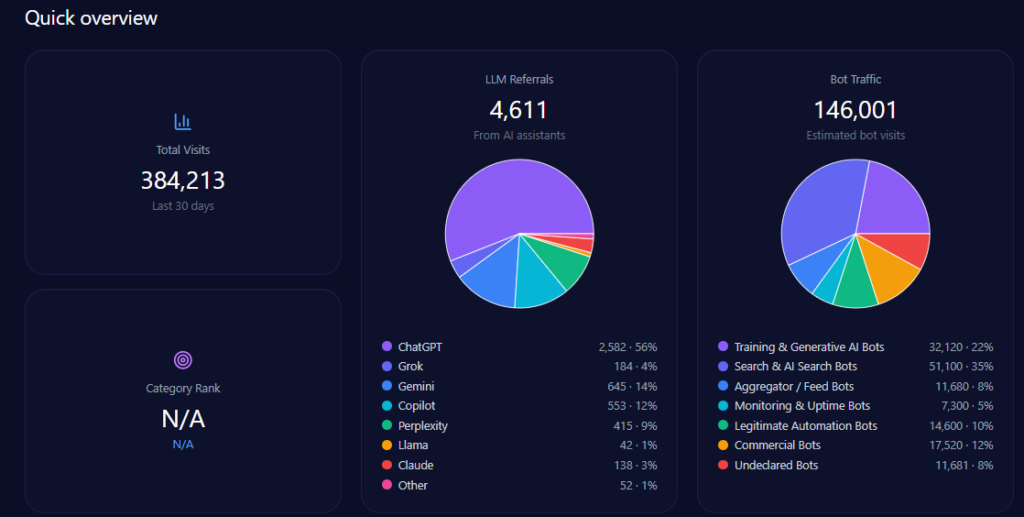
The footprint is substantial, and it is multi-layered. The report records 384,213 total visits, with 146,001 attributed to bot traffic—broken down into categories including Training & Generative AI Bots (32,120) and Search & AI Search Bots (51,100), alongside other bot segments. LLM referrals total 4,611, with the largest inbound stream from ChatGPT (2,582), followed by Gemini (645) and Copilot (553)—and additional traffic from platforms including Perplexity (415), Grok (184), and others.
The configuration captures a deliberate measurement frame: 48 LLM bots working, 48 prompts per LLM, spanning ChatGPT, Gemini, and Copilot. In parallel, the ranking analysis highlights a 47-bot run used for leadership and positioning checks—where Schwarz repeatedly lands as the European revenue authority.
In short: the system sees Schwarz often, cites it confidently, and routes measurable LLM referral traffic accordingly.
schwarzgruppe.de’s Quick overview (GEO Report, Jan 9, 2026)
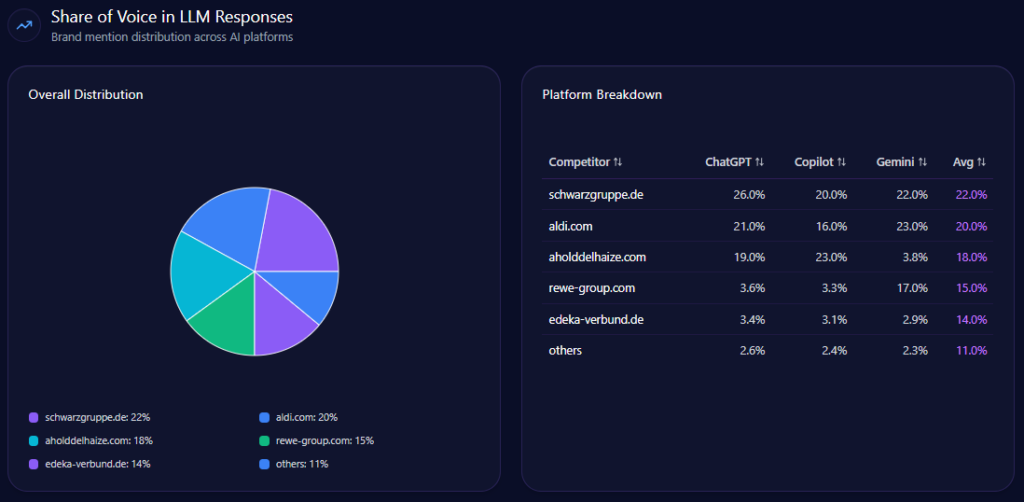
Schwarz Gruppe leads the competitive landscape on mindshare inside AI answers with a 22% Share of Voice, driven by 131 mentions out of 583 total. The margin is real—but not comfortable. Aldi Group sits at 20% (116), and Ahold Delhaize is close behind at 18% (104), with Rewe Group at 15% (88) and Edeka-Gruppe at 14% (81). The remainder is categorized as others (11%, 63).
Visibility scores reinforce the hierarchy: Schwarz at 84, Aldi at 81, Ahold Delhaize at 77, Rewe at 69, and Edeka at 66. A 2-point Share of Voice lead over Aldi is meaningful, but it signals a leadership position that can be challenged quickly if narrative ownership shifts in high-intent queries—especially those where Rewe and Ahold already hold prompt-level advantages.
This is why competitor sentiment tracking matters: the battle isn’t only volume; it’s the tone and context of the mention.
schwarzgruppe.de’s Share of Voice in LLM Responses (GEO Report, Jan 9, 2026)
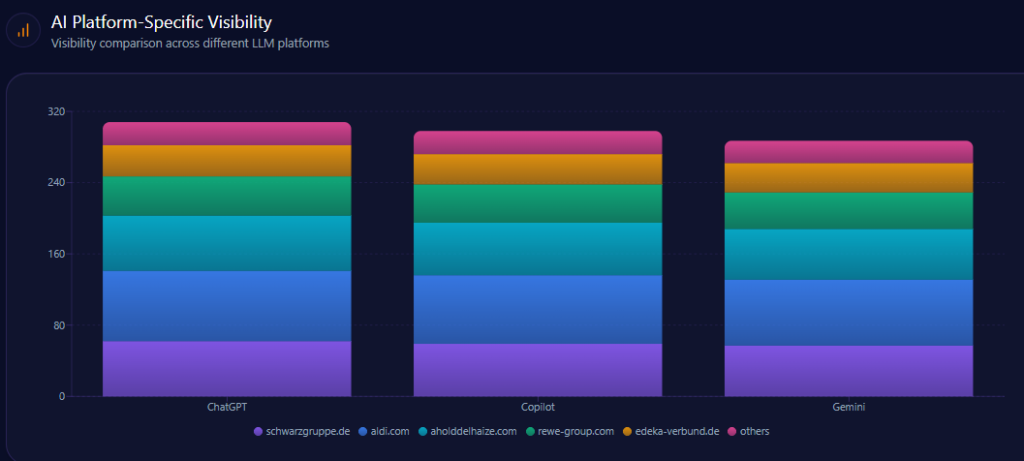
The same brand performs differently depending on which AI is doing the summarizing.
On ChatGPT, the environment is structurally favorable to Schwarz: platform visibility is 88, and Schwarz holds a 26% competitor share with 51 mentions (ahead of Aldi’s 21% / 42 and Ahold’s 19% / 38). This aligns with the report’s framing of Schwarz as high “data density” in leadership prompts.
Copilot tells a more competitive story. Platform visibility is 85, and although Schwarz appears with 20% / 40 mentions, Ahold Delhaize leads the competitor share at 23% / 46. The report attributes this shift to Copilot’s responsiveness to real-time financial and North American market framing—contexts where Ahold already holds advantages.
On Gemini, platform visibility is 82, and leadership tightens further: Aldi leads at 23% / 42, while Schwarz follows closely at 22% / 40, and Rewe appears at 17% / 31. Gemini’s ecosystem, in other words, is where Schwarz’s leadership is most contestable—especially when prompts steer toward price perception and convenience cues.
For leadership, this “platform bias” isn’t academic. It’s a distribution problem: the same message must survive multiple AI interpretive filters.
schwarzgruppe.de’s AI Platform-Specific Visibility (GEO Report, Jan 9, 2026)
The same brand performs differently depending on which AI is doing the summarizing
Schwarz Gruppe’s sentiment profile is strong: 81% positive, 13% neutral, and 6% negative, with an overall sentiment score of 81. But competitors are not merely close—they can be better in key narratives. Rewe Group posts an overall sentiment score of 84 (with 84% positive and 5% negative), and Edeka-Gruppe reaches 82 overall. Aldi Group sits at 79, while Ahold Delhaize is at 78.
The report’s context themes explain why. “Digital Sovereignty & Cloud” shows a count of 528 and a frequency of 75.00, with examples including STACKIT, XM Cyber, and “European Cloud,” and is characterized as positive. “Price Leadership” carries a count of 689 and a frequency of 90.00, but its sentiment tone is mixed—suggesting that value narratives win attention while still attracting skepticism or tradeoff framing. “Supply Chain Sustainability” (count 315, frequency 50.00) is labeled neutral, a reminder that ESG claims often get summarized cautiously rather than celebrated.
This is the strategic nuance: Schwarz can lead on sentiment overall, yet still face localized negative context—especially around transparency and labor—while competitors like Rewe can come across as more consistently “clean” in the tone of AI narratives.
Some prompts act like a spotlight—pulling Schwarz into the frame repeatedly and at scale.
The largest prompt by mentions is: “Which retail group is the largest by revenue in Europe?” with 339 mentions total, where Schwarz records 132 and competitors record 118 and 89 (listed as Aldi Group and Ahold Delhaize). In these “authority prompts,” Schwarz benefits from being the default citation.
But when prompts shift from scale to modernity, the distribution tightens. “Most technologically advanced supermarkets in Europe” totals 289 mentions, with Schwarz at 97, while competitors record 104 and 88 (listed as Ahold Delhaize and Rewe Group). That is the precise shape of the strategic risk: leadership in revenue-based framing does not automatically convert into leadership in tech-forward framing.
Two prompts stand out for their decisiveness:
“What are the core business units of Schwarz Gruppe?” shows 144 mentions with Schwarz at 144.
“Who owns Lidl and Kaufland?” also shows 144 mentions with Schwarz at 144.
Those 100% ownership-structure runs indicate a clean brand hierarchy inside the model’s memory—an asset many conglomerates struggle to achieve.
schwarzgruppe.de’s Top Prompts Driving Mentions (GEO Report, Jan 9, 2026)
The report’s prompt mix is lopsided in a way that explains Schwarz’s current advantage—and its next vulnerability.
“Feature Inquiry” dominates with a count of 7 and a value of 70, while “Comparison” appears with a count of 2 and a value of 20, and “Research” shows count 1 and value 10. “Purchase Intent” and “How-to/Tutorial” register 0.
That distribution means the system is being tested primarily on explanatory and evaluative questions—what the group is, what it owns, what it’s known for, and how it compares. This is good for a scale leader, because authority narratives travel well in feature inquiries. But it also means that when the prompt does become comparative (delivery, automation, organics, geography), the competitor with the sharper “proof package” can flip the outcome quickly.
schwarzgruppe.de’s Types of Prompt Queries (GEO Report, Jan 9, 2026)
E-commerce Sentiment for Competitor Products
At the commerce layer, Schwarz’s presence strengthens. In the report’s e-commerce share-of-voice tracking across ChatGPT, Gemini, and Copilot, Schwarz leads with 31.25% and 45 mentions. Edeka-Gruppe follows at 22.92% (33), Aldi Group at 19.44% (28), Rewe Group at 15.28% (22), and Ahold Delhaize at 8.33% (12).
The report’s e-commerce sentiment snapshots show positive readings of 72, 68, and 74, with neutral at 19, 24, and 17, and negative at 9, 8, and 9, across total review counts of 1,142, 987, and 1,203. Product-level snippets clarify where perception concentrates:
“The Lidl Plus app offers unbeatable personalized discounts compared to other German grocers.” (as cited in the report)
“Kaufland has a huge variety, but checkout queues can be long during peak times.” (as cited in the report)
“Freshness of produce at Schwarz stores is generally good, but sometimes lags behind Edeka’s premium selection.” (as cited in the report)
Referrals inside the commerce stream also carry conversion signals: Copilot shows 1,589 referrals at 4.8 conversion rate, ChatGPT shows 1,452 at 4.2, and Gemini shows 1,128 at 3.4.
Finally, the trendline suggests stability with specific peaks: Schwarz’s e-commerce mention share reaches 32% in April (with 471 mentions), after 31% in March (456) and 29% in June (435). In the same January–June frame, Edeka’s shares vary between 22–25%, Aldi between 19–23%, Rewe between 14–17%, and Ahold between 8–11%. Commerce is where Schwarz looks most like the default recommendation—yet even here, premium perception cues still pull toward Edeka.
Schwarz Gruppe’s GEO analytics profile is the kind leadership teams want: 22% platform-wide Share of Voice, 84 visibility, and repeated #1 positioning in scale and leadership prompts—yet with clearly measured exposure in last-mile delivery, premium organics, and North American framing. The report’s recommendations are decisive: increase technical and digital white papers on schwarzgruppe.de to improve innovation coverage (currently 62%), enhance sustainability reporting with a sharper EU circular-economy focus to regain ground from Rewe, and optimize real-time news data feeds and corporate bulletins to counter Ahold Delhaize’s Copilot advantage. It also calls for a targeted “Lidl Plus” delivery campaign to close the 16-point gap with Rewe, and a “Lidl Bio” authority program aimed at improving rank by 2 units in organic search categories.
Explore SpyderBot to operationalize these GEO analytics insights.
This GEO report shows Amazon as the default answer across major generative engines—yet it also identifies the niches and regions where rivals reliably outrank it, reshaping consumer and enterprise choices inside AI responses.
At-a-glance
2,864,031,365 total visits, including 916,490,037 from bot traffic
17,184,188 LLM referrals, led by ChatGPT (7,732,885) and Perplexity (2,577,628)
#1 category rank in E-commerce_and_Shopping/Marketplace
43% Share of Voice (247 mentions out of 576) with a 94/100 Visibility Score
49% performance gap versus eBay in high-value vintage and collectible prompts
LATAM delivery prompts show MercadoLibre 136 mentions vs Amazon’s 48 in a top question
Imagine a shopper asking an AI assistant where to buy something tonight—and the model answers in three confident lines. In that compressed moment, brands aren’t compared by browsing; they’re compared by what the model feels safe recommending first.
That’s the boardroom implication of GEO analytics: the winner is not only the marketplace with reach, but the marketplace that becomes the default citation—until a competitor owns a niche story the model trusts more.
Across all 144 bot-prompt iterations tracked in the report, Amazon’s lead shows up as a pattern: repeated appearances across platforms, repeated framing around convenience and logistics, and repeated inclusion even when the prompt shifts into cloud and business comparisons. The report’s warning is equally patterned: when the question is wholesale sourcing, refurbished trust, or regional logistics, the model’s safest answer can change.
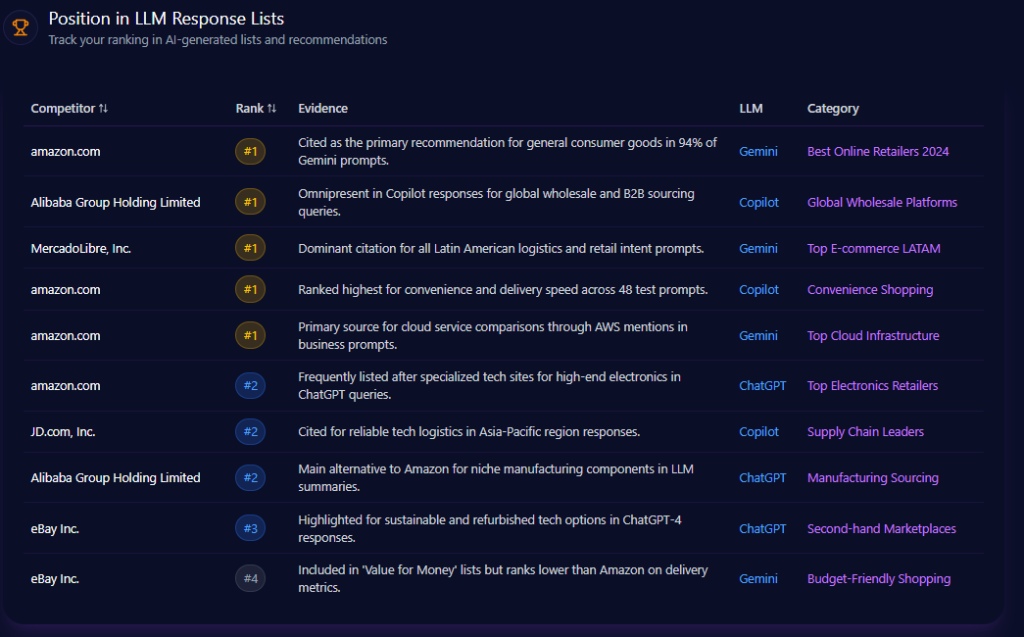
Amazon sits at #1 in Best Online Retailers 2024 on Gemini, backed by evidence that it is cited as the primary recommendation for general consumer goods in 94% of Gemini prompts. It also ranks #1 in Convenience Shopping on Copilot, tied to delivery-speed and convenience performance across 48 test prompts.
The report shows Amazon’s reach beyond consumer retail too: it ranks #1 in Top Cloud Infrastructure on Gemini, supported by AWS mentions in business prompts. But the same lists draw clear borders. In Top Electronics Retailers on ChatGPT, Amazon appears at #2—and in specialized lists, rivals take the crown: Alibaba is #1 for Global Wholesale Platforms on Copilot, and MercadoLibre is #1 for Top E-commerce LATAM on Gemini.
amazon.com‘s Position in LLM Response Lists (GEO Report, Jan 9, 2026)
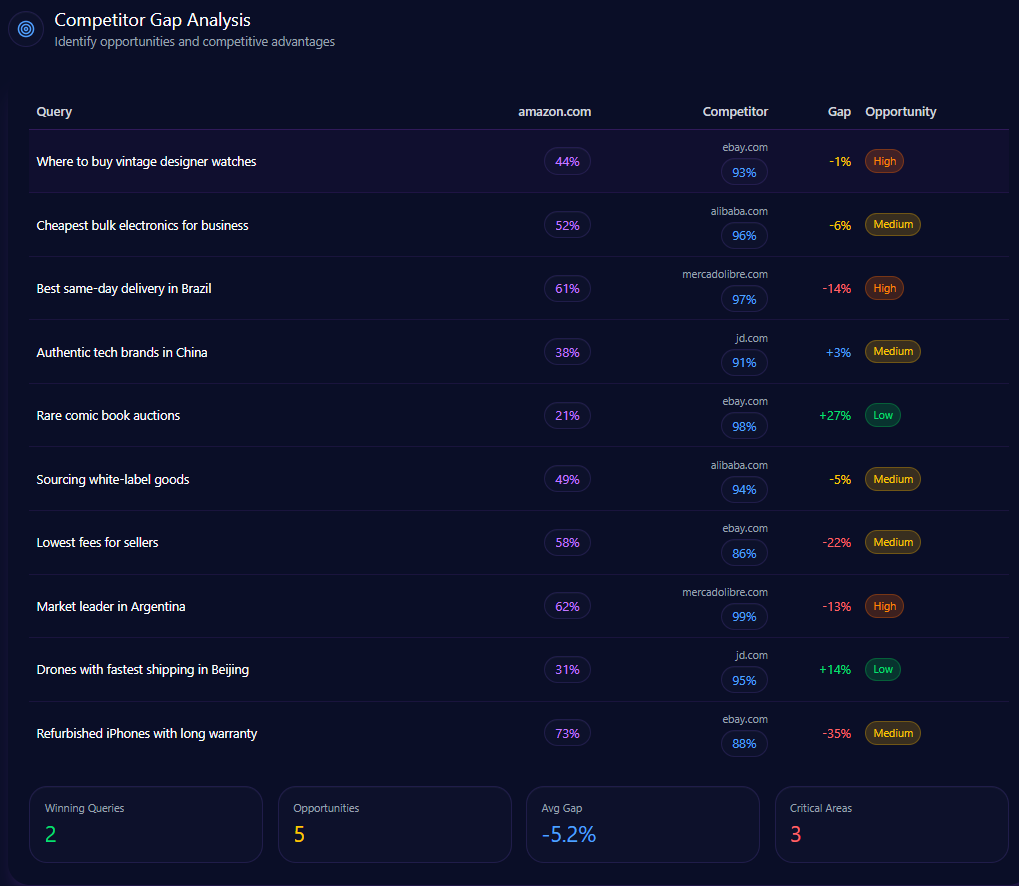
The gaps are not random; they concentrate where category-fit matters most to LLMs—authenticity, wholesale sourcing, and local logistics.
Query
Amazon metric
Competitor metric
Gap / priority
Where to buy vintage designer watches
44
93 (eBay)
49 — High
Cheapest bulk electronics for business
52
96 (Alibaba)
44 — Medium
Best same-day delivery in Brazil
61
97 (MercadoLibre)
36 — High
Authentic tech brands in China
38
91 (JD.com)
53 — Medium
The report’s explanations are blunt: eBay wins because LLMs prioritize authenticated luxury and vintage; Alibaba wins because it is synonymous with dropshipping and white-label sourcing; MercadoLibre wins because local logistics earns higher trust scores. The action items mirror those narratives—stronger visibility for Amazon Luxury Stores, clearer bulk discount structures for Amazon Business, and localized delivery-speed schema in Portuguese and Spanish.
amazon.com‘s Competitor Gap Analysis (GEO Report, Jan 9, 2026)
Keyword triggers act like hidden switches. In the report’s e-commerce triggers, refurbished smartphones heavily favors eBay (84) competitor mentions, while buy bulk electronics heavily favors Alibaba (91). Delivery phrasing fragments by region: next day delivery pulls in JD.com (47) and MercadoLibre (31) competitor mentions. Even broad best online marketplace language invites competitor co-recommendations, including eBay (42).
Founder narratives surface as governance risk in generative investment-style questions. Jeff Bezos appears with a mention frequency of 143, and his sentiment is 52% positive, 25% neutral, and 23% negative (sentiment score 64).
Negative context clusters around Labor Ethics (38%) and Market Dominance (29%), with Personal Wealth Disparity (21%) and others (12%). Platform weighting is uneven: Market Dominance reaches 51% on Copilot, while Labor Ethics reaches 46% on Gemini and 42% on ChatGPT—meaning the same founder story can land differently depending on where stakeholders ask.
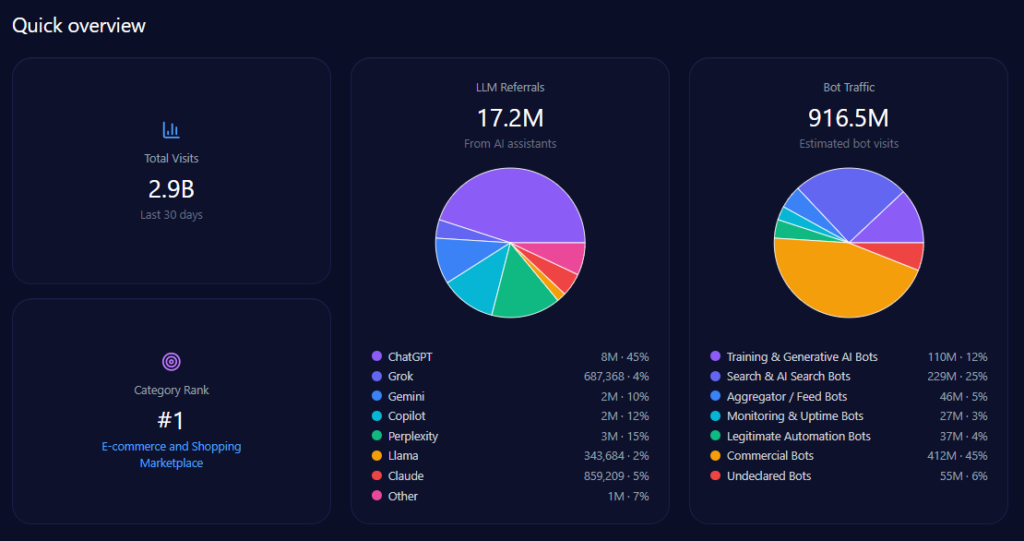
Amazon’s scale is reflected in 2,864,031,365 total visits and 916,490,037 bot visits, including Commercial Bots at 412,420,517 and Search & AI Search Bots at 229,122,509. On the generative referral layer, Amazon records 17,184,188 LLM referrals, with major contributors including ChatGPT (7,732,885), Perplexity (2,577,628), Copilot (2,062,103), and Gemini (1,718,419)—while holding #1 in E-commerce_and_Shopping/Marketplace.
amazon.com‘s Quick overview (GEO Report, Jan 9, 2026)
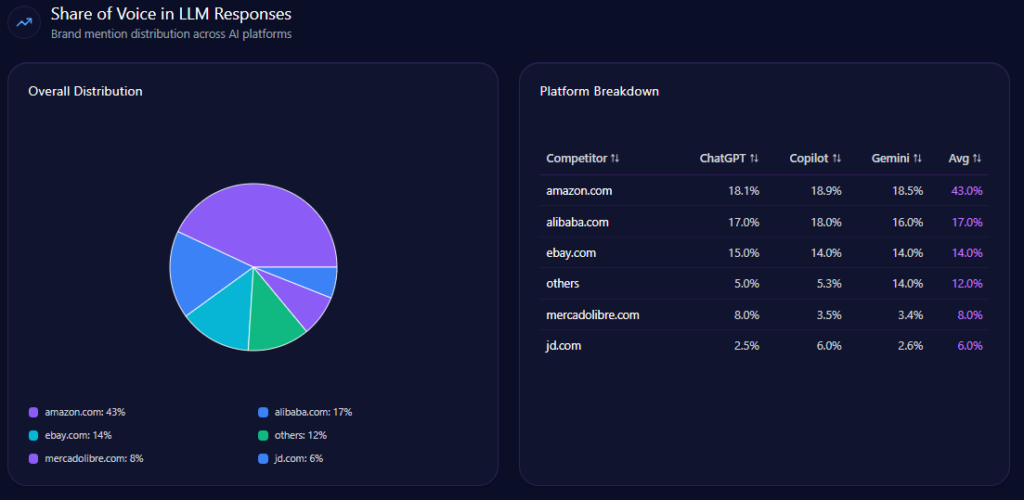
Across the competitive set, Amazon captures 43% Share of Voice with 247 mentions and a 94 Visibility Score. Alibaba follows at 17% (98; visibility 68), eBay at 14% (82; visibility 62), MercadoLibre at 8% (44; visibility 34), and JD.com at 6% (36; visibility 29), with others at 12% (69; visibility 53).
This is the report’s clearest picture of LLM brand mentions: Amazon leads decisively, but competitors remain structurally discoverable in the exact niches where the model wants a sharper specialist answer.
amazon.com‘s Share of Voice in LLM Responses (GEO Report, Jan 9, 2026)
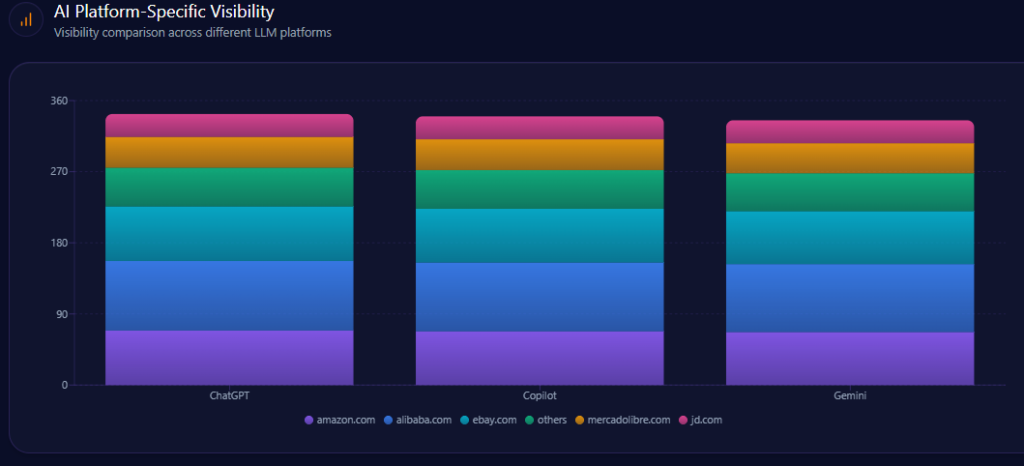
Amazon’s visibility stays consistently high across the named engines: 98% on ChatGPT (with 42% Share of Voice and 192 total mentions), 97% on Copilot (with 44% Share of Voice and 192 mentions), and 96% on Gemini (with 43% Share of Voice and 192 mentions).
Competitor composition shifts by platform. On ChatGPT, Alibaba holds 17% (33 mentions) and eBay 15% (29). On Copilot, Alibaba is 18% (35) and eBay 14% (27), with JD.com at 6% (12). On Gemini, Alibaba is 16% (31) and eBay 14% (27), alongside others at 14% (27). The strategic read: Amazon is present nearly everywhere, but the runner-up brand depends on the engine.
amazon.com‘s AI Platform-Specific Visibility (GEO Report, Jan 9, 2026)
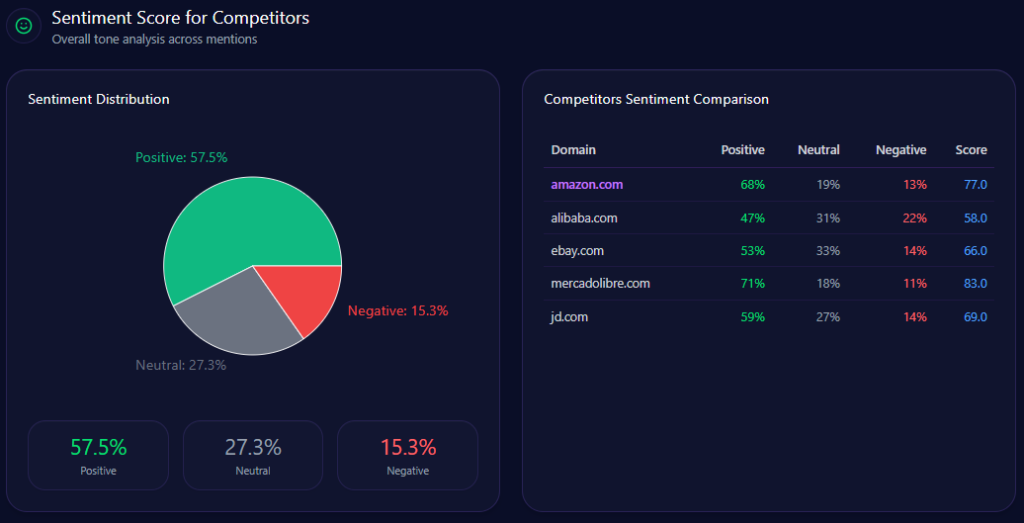
Amazon’s sentiment is strongly positive: 68% positive, 19% neutral, 13% negative, overall sentiment score 77. MercadoLibre scores highest at 83, while JD.com scores 69, eBay 66, and Alibaba 58.
The themes behind those tones are explicit. Logistics and Delivery Speed appears 132 times (frequency 92.00) with a positive tone; AI and Technological Innovation appears 98 times (frequency 68.00) with a positive tone; Labor and Corporate Ethics appears 56 times (frequency 39.00) with a negative tone. That split is why competitor sentiment tracking matters: a brand can win speed and innovation while still losing ground when the framing shifts to ethics.
amazon.com‘s Sentiment Score for Competitors (GEO Report, Jan 9, 2026)
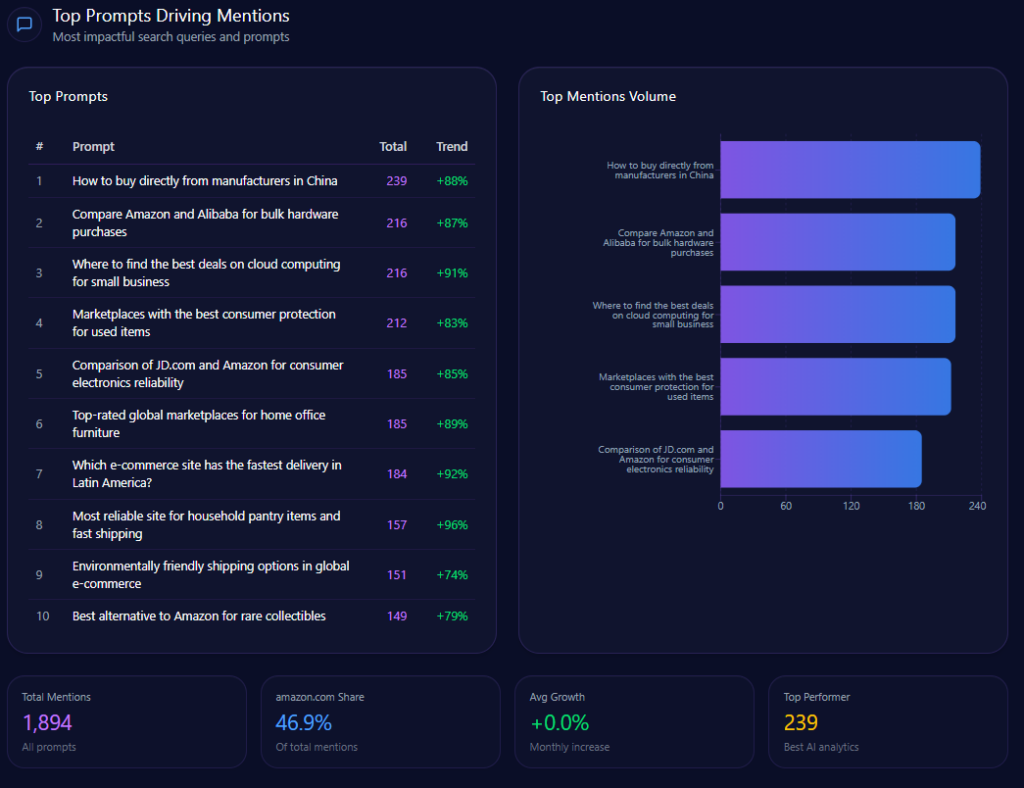
The report’s top prompts show where competitive gravity changes:
How to buy directly from manufacturers in China totals 239 mentions, with Amazon at 12 versus Alibaba (141) and JD.com (86).
Compare Amazon and Alibaba for bulk hardware purchases totals 216, with Amazon at 112 and Alibaba at 104.
Which e-commerce site has the fastest delivery in Latin America? totals 184, with Amazon at 48 versus MercadoLibre (136).
Best alternative to Amazon for rare collectibles totals 149, with Amazon at 21 versus eBay (128).
amazon.com‘s Top Prompts Driving Mentions (GEO Report, Jan 9, 2026)
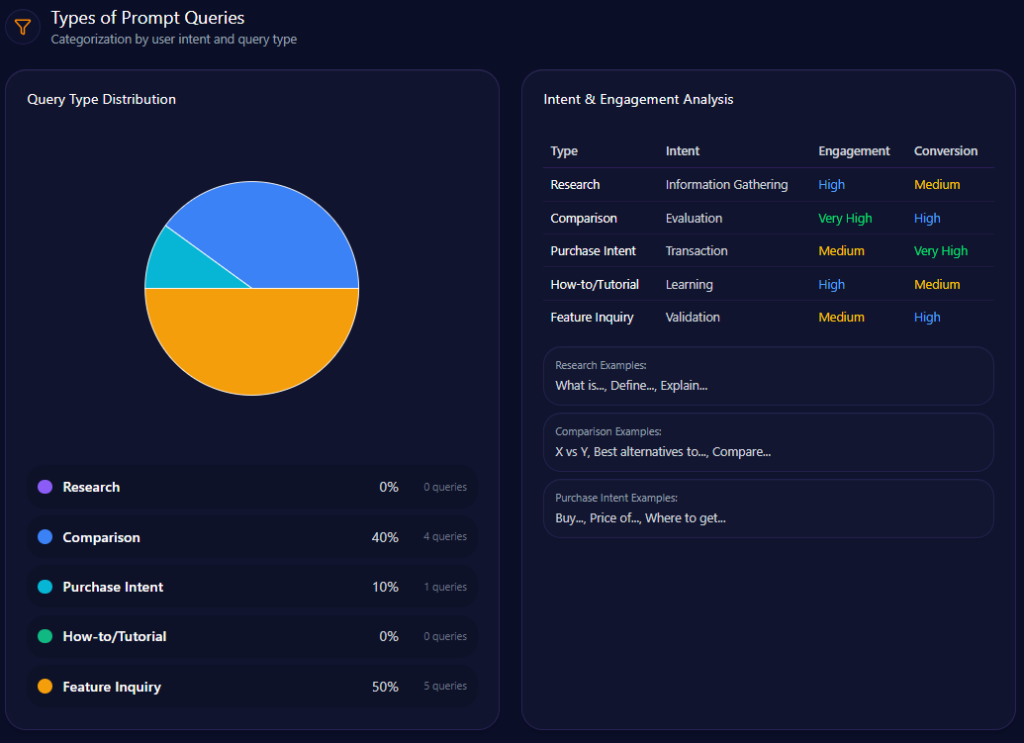
The intent mix is dominated by evaluative questions: Feature Inquiry has a value of 50 across 5 entries, and Comparison sits at 40 across 4 entries. Purchase Intent appears at 10 with 1 entry, while Research and How-to/Tutorial are 0 with 0 entries each. That’s a reminder that the generative battlefield is often about justification and trade-offs, not just directing a user to buy.
amazon.com‘s Types of Prompt Queries (GEO Report, Jan 9, 2026)
In e-commerce Share of Voice across ChatGPT, Gemini, and Copilot, Amazon holds 46.94% with 69 mentions, followed by eBay at 17.69% (26) and Alibaba at 14.29% (21). The report’s product-level sentiment snapshots show positive rates of 71%, 74%, and 68% across totals of 1,243, 1,456, and 1,187 reviews, respectively.
The report’s snippets capture the tension between convenience and concern: “The Prime delivery was exceptionally fast, arriving in under 2…he ease of returns makes it the most reliable shopping choice.” (as cited in the report), while another snippet notes difficulty distinguishing between high-quality brands and low-quality generic sellers.
On referrals, Copilot drives 1,421 e-commerce referrals at a 4.2 conversion rate, Gemini 1,156 at 4.8, and ChatGPT 842 at 3.4. The report’s monthly trend shows Amazon rising from 1,104 in Aug 2025 to 2,419 in Dec 2025, then recording 1,398 in Jan 2026.
Amazon leads the generative marketplace narrative with 43% Share of Voice, a 94/100 Visibility Score, and 96–98% platform visibility. Yet the report also makes the competitive gap legible: Alibaba owns wholesale sourcing language, eBay owns refurbished and collectibles trust, and MercadoLibre owns LATAM logistics authority.
The recommended response is targeted: improve structured data for wholesale and bulk inventory to challenge Alibaba’s 98% coverage in wholesale prompts; deploy localized GEO content strategies for LATAM and Asian markets to reclaim Share of Voice from MercadoLibre and JD.com within 90 days; and target sustainable and refurbished prompt categories to neutralize eBay’s 81% visibility in used-market query categories.
Explore SpyderBot to operationalize these GEO analytics insights.
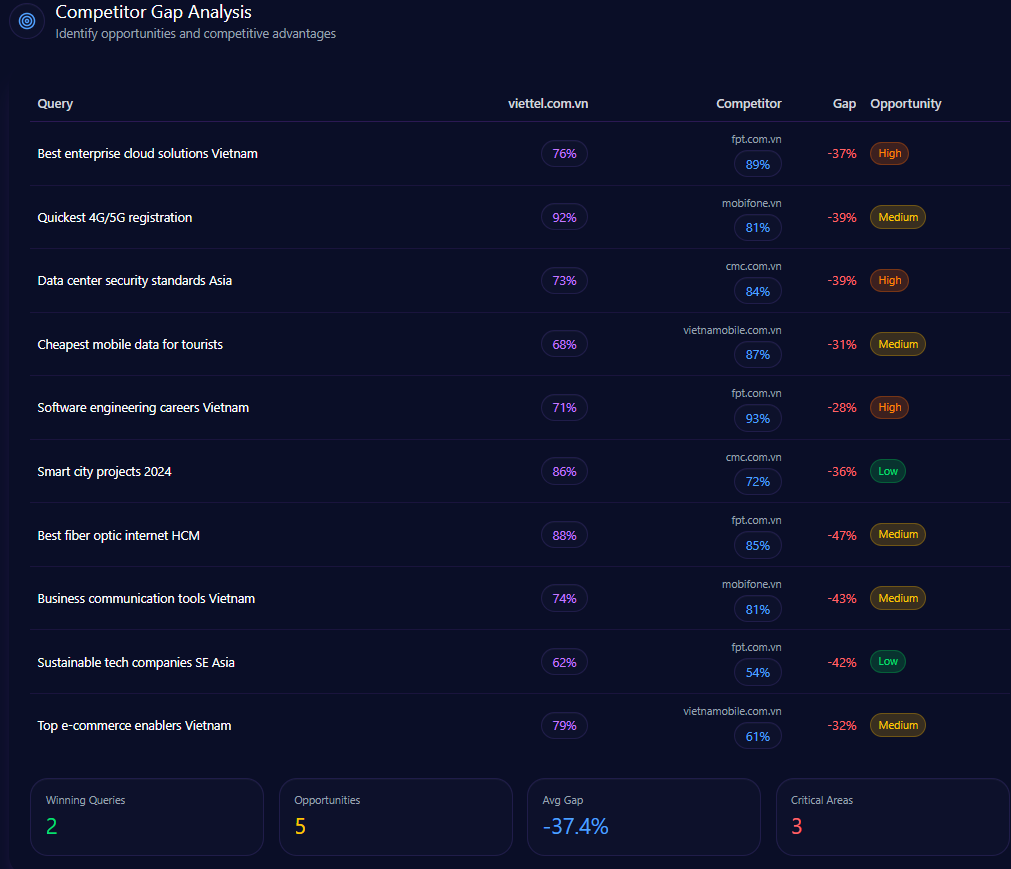
In Vietnam’s Telecommunications category, Viettel isn’t just winning attention—it’s winning the default position inside AI answers. The same report also shows where that dominance thins out: enterprise cloud authority, talent narratives, and “value” conversations that rivals have learned to hijack.
At-a-glance
240,148 total visits, including 91,482 in bot traffic
2,943 LLM referrals, led by ChatGPT (1,324), Gemini (589), and Copilot (589)
#19 category rank in Computers_Electronics_and_Technology/Telecommunications
38% Share of Voice (257 mentions) out of 673 total mentions
92 Visibility Score (highest among listed competitors)
Imagine a customer, a CIO, and a job candidate all asking different questions—yet all receiving answers that feel strangely similar. Not because the world is simple, but because generative systems compress complexity into a few confident lines.
That compression is where modern advantage lives. In GEO analytics, the winner isn’t only the company with the biggest network or the widest portfolio—it’s the brand that becomes the default recommendation, the most “citable” authority, the safest answer when uncertainty is high. The report’s story is clear: Viettel often holds that default position. But it also shows exactly where the narrative can be stolen—by a challenger that owns cloud language, by a rival framed as agile, or by a disruptor that wins on price signals even when quality is debated.
Position in LLM Response Lists
Viettel Wins the Infrastructure Narrative—But Faces a Software-First Challenge
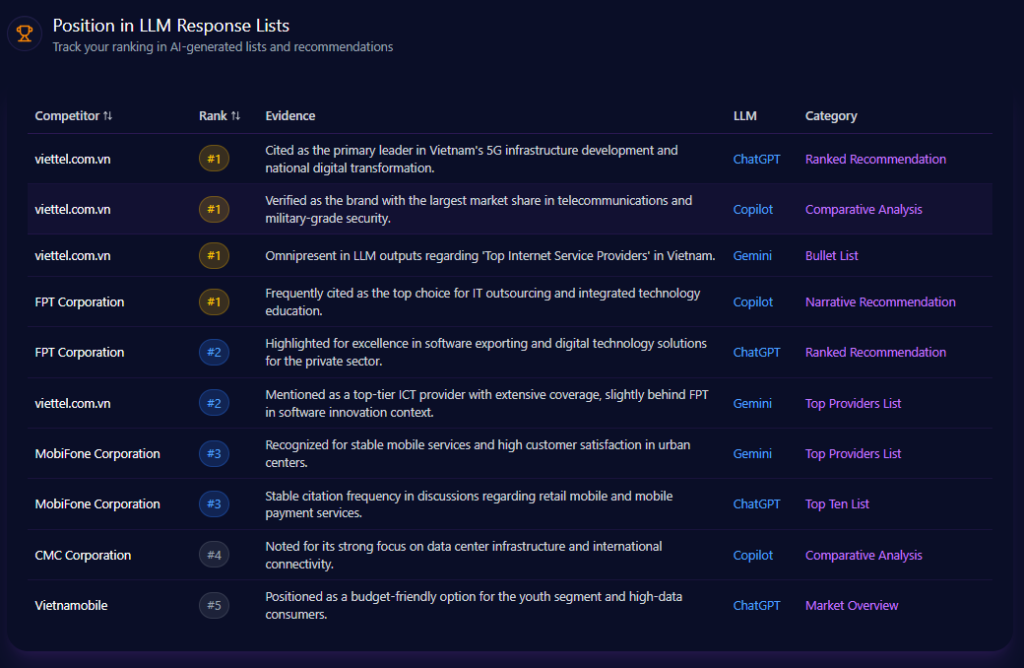
Across the most visible answer formats—ranked recommendations, comparative analyses, and bullet lists—Viettel repeatedly surfaces at the top when the question is about infrastructure-scale credibility. The report places Viettel at rank #1 on ChatGPT in a “Ranked Recommendation” context tied to 5G infrastructure leadership, and rank #1 on Gemini in a “Bullet List” context where it is described as omnipresent in “Top Internet Service Providers” outputs. On Copilot, Viettel also appears at rank #1 in a “Comparative Analysis,” anchored to telecommunications market leadership and “military-grade security.”
But the same evidence set reveals a parallel truth: when prompts shift from infrastructure dominance to software innovation narratives, positioning becomes more conditional. On Gemini, Viettel is recorded at rank #2 in a “Top Providers List,” described as a top-tier ICT provider that sits slightly behind FPT in software innovation context. Meanwhile, FPT itself appears as rank #1 on Copilot for IT outsourcing and technology education narratives, and rank #2 on ChatGPT for software exporting and private-sector digital solutions.
In other words: Viettel is a default leader in the “nation-scale” story—and a contested player in the “software-first” story. That is exactly how LLM brand mentions become a strategic scoreboard.
Position in LLM Response Lists
Where the Story Changes Hands: Enterprise Credibility vs Keyword Gravity
If the first section is about where Viettel shows up, this one is about where competitors quietly change the framing. The report’s gap signals don’t read like a broad erosion—they read like targeted raids on high-intent territory: enterprise cloud, data center security credibility, and tech talent magnetism.
Three gaps stand out not because they are loud, but because they are labeled High priority and sit inside decision-heavy prompts:
Query
Viettel position/metric
Competitor position/metric
Gap/priority
Best enterprise cloud solutions Vietnam
76
89 (FPT)
13.00 / High
Data center security standards Asia
73
84 (CMC)
11.00 / High
Software engineering careers Vietnam
71
93 (FPT)
22.00 / High
The narrative beneath those rows is sharper than the numbers. For cloud solutions, the report states that FPT is cited more frequently for cloud migration and multi-cloud strategies, and the action item is explicit: produce localized whitepapers on Viettel Cloud’s scalability for global LLM training. For security standards, the report credits CMC’s focus on Tier III standards in press releases as being better captured by generative systems—paired with a direct instruction to highlight international security certifications in site metadata and PR. And for careers, the gap is not subtle: a 22-point deficit with a recommendation to increase high-authority backlinks from global tech career platforms to Viettel HR.
Not every “gap” is a weakness; the report also includes areas where Viettel leads and must defend. In “Smart city projects 2024,” Viettel is positioned as recognized as the main smart city partner for provincial governments, paired with the low-priority instruction to maintain flow of case studies on IoT and smart lighting. In “Best fiber optic internet HCM,” the report calls the race tight—88 for Viettel vs 85 for FPT—alongside a practical move: analyze speed-test aggregators to provide proof of superiority in LLM training sets.
This is the battle map: not one war, but several micro-wars—each with different “proof” requirements.
Some competitive losses don’t happen in executive prompts. They happen in the messy, high-volume keyword layer where consumers ask for “cheap,” “promo,” “online,” and “discount”—and where LLMs learn brand associations from repeated patterns.
The report’s trigger keywords make this explicit. Under “internet cáp quang giá rẻ”, FPT is associated with 438 mentions, while MobiFone shows 185 and CMC shows 56. Under “cloud server vietnam”, FPT appears with 582 mentions and CMC with 341—a keyword-level reflection of the same enterprise pressure described elsewhere. Under “sim số đẹp online,” MobiFone shows 465 mentions, with Vietnamobile at 215, signaling that certain consumer commerce narratives skew away from Viettel even when Viettel leads broader connectivity mindshare.
At the same time, Viettel has keyword territory it owns in a more brand-anchored way. “viettel money promotion” carries 654 mentions in the trigger set, and “gói cước 5G viettel” carries 582. Those phrases are not just search strings—they’re narrative hooks. They determine what kind of story gets told when someone asks for a recommendation and the model reaches for the most repeated associations.
This is where competitor sentiment tracking becomes practical: not only measuring tone, but spotting the keyword gates where rivals enter the conversation by default.
Viettel’s GEO Advantage: Leading Share of Voice Under Founder Drag and Enterprise Pressure
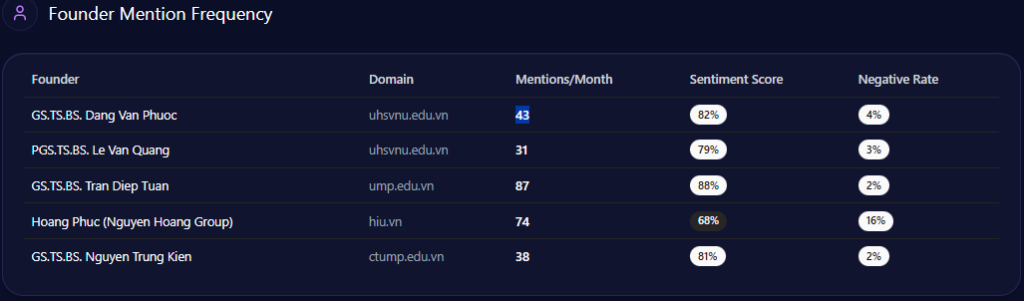
The founder lens is where corporate identity becomes human—and where reputational drag becomes a storyline rather than a metric. In the report, Tào Đức Thắng appears with 89 founder mentions and a 78 sentiment score, with 68% positive, 23% neutral, and 9% negative. FPT’s Trương Gia Bình is present more frequently at 122 mentions with a sentiment score of 86.
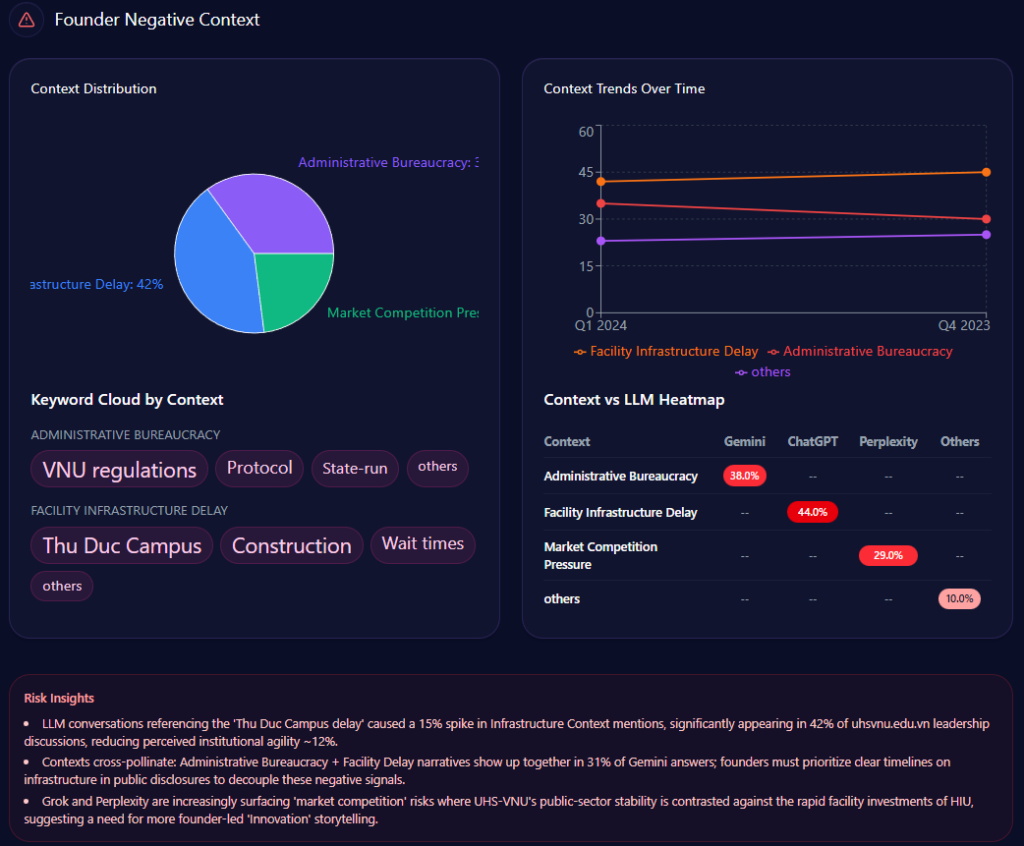
But the sharper risk signal is not the comparative volume. It’s the negative-context distribution around Viettel’s founder narrative. The report’s Founder Negative Context is led by Market Bureaucracy (38%), followed by Talent Retention (27%), Geopolitical Risks (22%), and others (13%). In Q1 2024, Market Bureaucracy reaches 41% and is marked as exceeding threshold; in Q4 2023, Geopolitical Risks hits 29% and is also marked threshold-exceeded.
The context keywords are blunt and operational: Market Bureaucracy is tied to decision-speed (weight 88), state-governance (72), and bottleneck (64); Talent Retention is tied to competition (82), brain-drain (79), and corporate-culture (68). The platform heatmap shows where these narratives stick: Market Bureaucracy appears at 42% on ChatGPT, 36% on Gemini, and 35% on Copilot; Geopolitical Risks rises to 31% on Gemini; Talent Retention registers 24% on ChatGPT.
The report goes further with pointed framing signals: it notes that phrasing around “State Enterprise rigidity” now appears in 18% of viettel.com.vn discussions, alongside an insight claiming this reduces investor confidence by approximately 6% in private equity circles. It also states that Geopolitical Risks + Market Bureaucracy co-appear in 24% of Gemini answers, and that FPT is framed as “agile” in 62% of prompts while Viettel is framed as “stable but slow.”
Whether leadership likes these frames or not, generative systems remember them—then reuse them.
As of January 9, 2026, Viettel’s footprint in Computers_Electronics_and_Technology/Telecommunications is anchored by 240,148 total visits and 91,482 bot visits. Bot traffic is not monolithic here: the report breaks it into Training & Generative AI Bots (13,722), Search & AI Search Bots (27,445), Aggregator / Feed Bots (4,574), Monitoring & Uptime Bots (18,296), Legitimate Automation Bots (4,574), Commercial Bots (13,722), and Undeclared Bots (9,149).
LLM referral traffic totals 2,943, led by ChatGPT (1,324), with Gemini (589) and Copilot (589) close behind, plus Perplexity (294), Claude (59), Grok (29), Llama (29), and Other (30). This is a useful reminder: the generative ecosystem influencing visibility is broader than the headline trio—even if the report’s primary testing focuses on ChatGPT, Gemini, and Copilot, with 48 LLM bots working and 48 prompts per LLM.
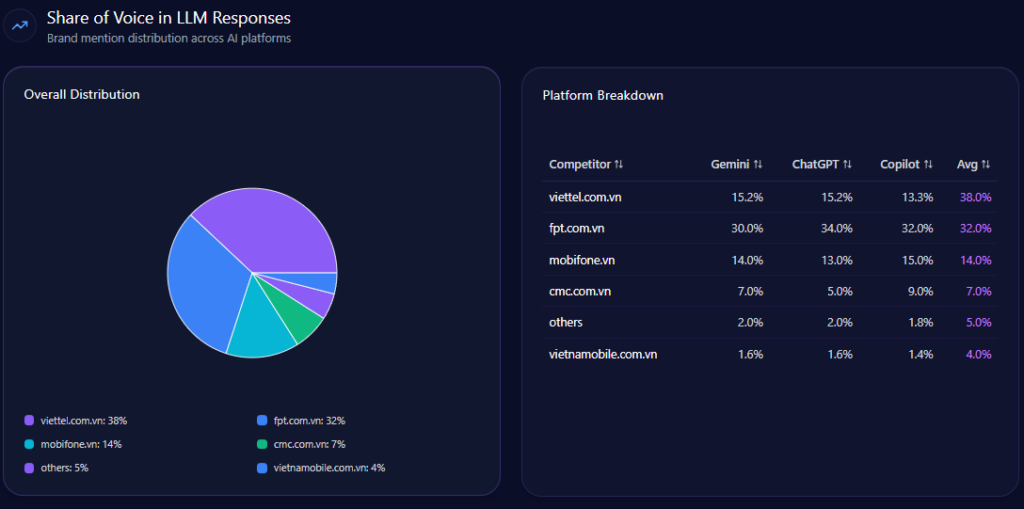
Quick overview
The cleanest headline in the report is also the most strategic: Viettel holds 38% Share of Voice with 257 mentions out of 673 total mentions. FPT follows at 32% with 215 mentions. MobiFone holds 14% with 94 mentions; CMC holds 7% with 47; Vietnamobile holds 4% with 27; and “others” account for 5% with 33.
That 38% position is not just “leading.” It is leading with a rival close enough to matter. A six-point margin over FPT can disappear quickly if the high-intent domains—cloud, security, careers—tilt further toward the challenger. Visibility Score reinforces the pecking order: Viettel leads at 92, followed by FPT at 88, MobiFone at 71, CMC at 64, “others” at 52, and Vietnamobile at 48.
The report also shows why this SoV isn’t accidental. In the 5G prompt set, Viettel reaches 99% brand prompt coverage (139 out of 141), with MobiFone at 86%, FPT at 48%, and others at 17%. But in “Top digital transformation and enterprise cloud services,” the table flips at the top: FPT reaches 95% coverage while Viettel sits at 91% and CMC at 81%. The story is consistent: the telecom core is locked; the enterprise narrative is contestable.
Share of Voice in LLM Responses
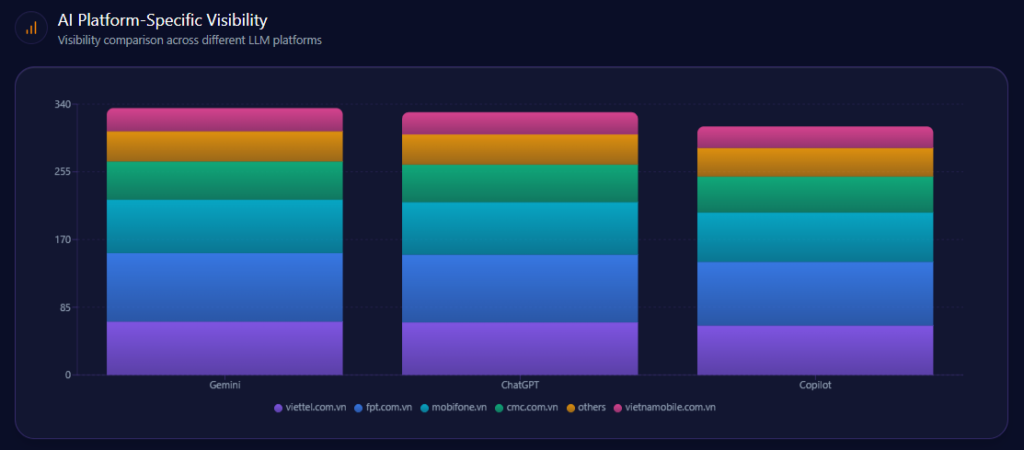
Platform bias is where leadership teams often get surprised—because the same brand can look dominant in one model and merely “present” in another.
On Gemini, Viettel’s visibility percentage is 96 with a 40% share of voice and 228 total mentions; the competitor share list includes FPT at 30% (68 mentions), MobiFone at 14% (32), and CMC at 7% (16). On ChatGPT, Viettel shows 94 visibility percentage with 40% share of voice and 215 total mentions; FPT rises to 34% (73 mentions), MobiFone holds 13% (28), and CMC shows 5% (11). On Copilot, visibility percentage is 89, and Viettel’s share of voice dips to 35% even as total mentions are 230; FPT sits at 32% (74 mentions), MobiFone at 15% (34), and CMC at 9% (20).
This is the same competitive geometry the report calls out elsewhere: Copilot is the environment where Viettel’s advantage narrows—and where the report explicitly recommends optimizing technical documentation and whitepapers for Bing-based bots to move Copilot visibility from 35% to 40%.
AI Platform-Specific Visibility
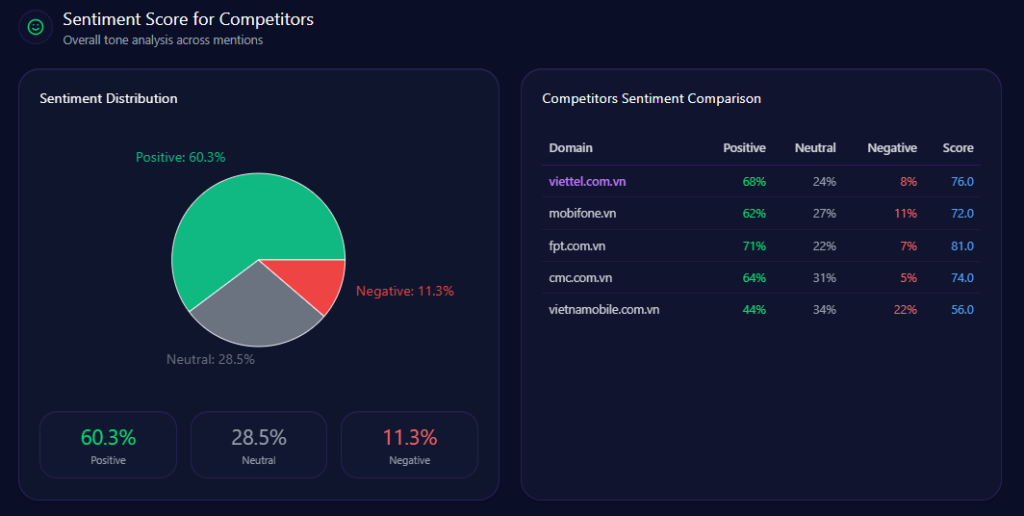
If share of voice is presence, sentiment is permission: the tone that determines whether the brand is recommended with confidence or mentioned with caveats.
The report scores overall sentiment as 76 for Viettel (with 68 positive, 24 neutral, 8 negative). FPT leads sentiment at 81 (positive 71, neutral 22, negative 7). MobiFone registers 72 overall (positive 62, neutral 27, negative 11). CMC sits at 74 (positive 64, neutral 31, negative 5). Vietnamobile trails at 56, with the most negative share in the set (positive 44, neutral 34, negative 22).
The context themes explain why these tones persist. 5G Infrastructure dominates with a frequency of 87.00 and is marked Positive, with examples like Viettel 5G trials and nationwide deployment. Digital Government follows at 68.00 and is marked Very Positive, tied to smart city and e-government solutions. AI & Big Data appears at 41.00 and is marked Positive. The friction point is Customer Service at 61.00, described as Neutral-Negative with examples including support wait times, app usability, and billing disputes.
This is the emotional shape of the market: admiration for infrastructure, confidence in public-sector capability, and a recurring “last-mile” complaint loop that can soften recommendation strength at the exact moment a user is choosing.
Sentiment Score for Competitors
The report’s top prompts read like a map of where decisions are actually being made—enterprise, security, consumer bundles, roaming, and onboarding flows.
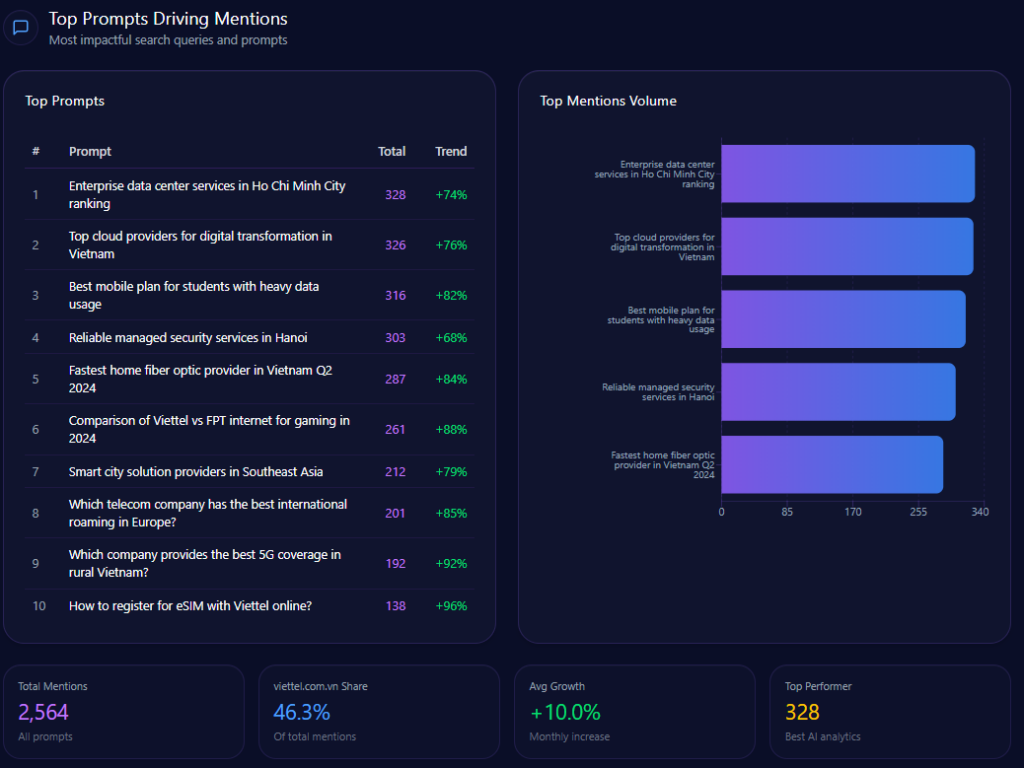
Two enterprise prompts sit at the top by total mentions: “Enterprise data center services in Ho Chi Minh City ranking” with 328 mentions (Viettel at 106, and competitors named include FPT Corporation and CMC Corporation, with a +74% trend), and “Top cloud providers for digital transformation in Vietnam” with 326 mentions (Viettel at 109, competitors named include CMC Corporation and FPT Corporation, with a +76% trend). These are exactly the arenas where gap analysis shows pressure.
On the consumer side, the prompts show both strength and vulnerability. “Best mobile plan for students with heavy data usage” has 316 mentions with Viettel at 118 and competitors named as MobiFone and Vietnamobile (+82%). “Fastest home fiber optic provider in Vietnam Q2 2024” has 287 mentions with Viettel at 121, and competitors named include FPT Corporation and MobiFone (+84%). “Comparison of Viettel vs FPT internet for gaming in 2024” reaches 261 mentions with Viettel at 127 and FPT named as the competitor (+88%).
Then there are the functional, high-conversion questions where Viettel becomes almost exclusive. “How to register for eSIM with Viettel online?” shows 138 mentions with Viettel at 138, carrying a +96% trend. If leadership wants a reminder of what “narrative ownership” looks like, it’s that line: the brand becomes the answer because it is the procedure.
Top Prompts Driving Mentions
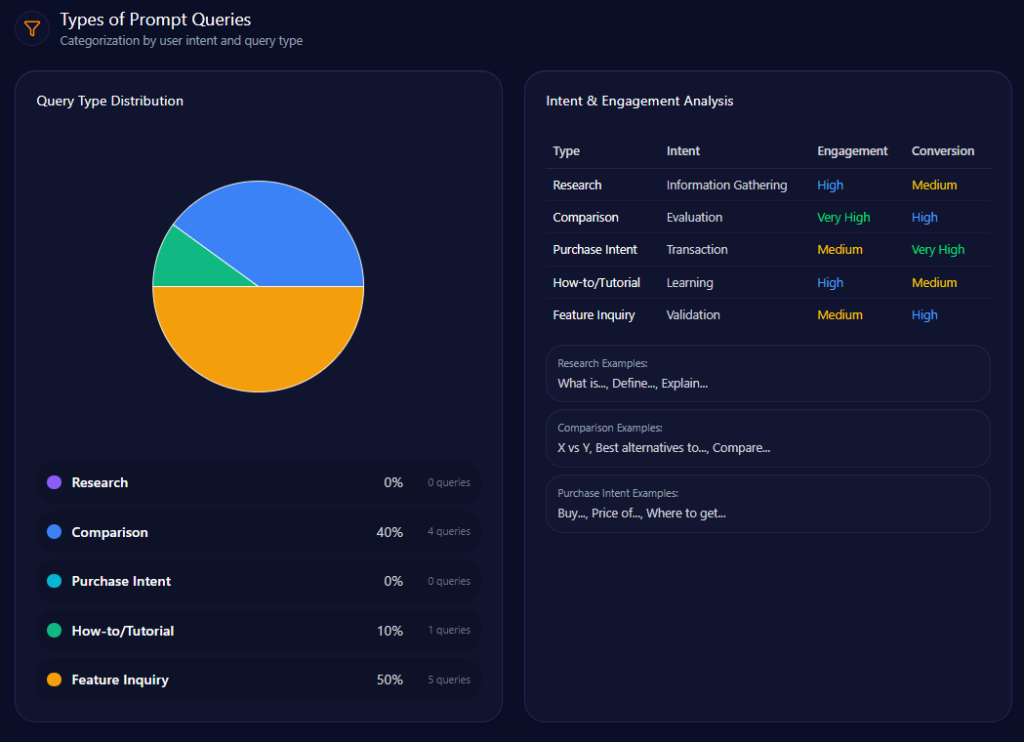
The report’s prompt-type mix shows a market that is less about abstract research and more about selecting between real options. Feature Inquiry dominates at 50 with 5 counts; Comparison follows at 40 with 4 counts; How-to/Tutorial appears at 10 with 1 count. Research and Purchase Intent are recorded at 0.
That distribution matters because it tells you what generative systems are being asked to do: explain features, compare brands, and guide users through actions. In that world, authority is less about slogans and more about structured, extractable proof.
Types of Prompt Queries
The report includes a separate e-commerce layer where brand competition shows up through product-level discovery, reviews, and referral flows. In that environment, Viettel holds 37.83% share of voice with 2,615 mentions, while FPT holds 27.63% with 1,910 mentions. MobiFone follows at 16.67% (1,152 mentions), then CMC at 7.32% (506), Vietnamobile at 6.99% (483), and others at 3.56% (246).
Review sentiment snapshots in the report show product perception that blends admiration with friction: one set records 72 positive, 21 neutral, 7 negative across 1,240 total reviews; another records 75/18/7 across 1,420 reviews; another records 70/24/6 across 980 reviews. And the report’s snippets (as cited in the report) make the narrative concrete:
“Viettel has the best 5G coverage in rural areas. Highly recommended for travelers.”
“The fiber internet speed is consistent, but the customer service wait time can be long.”
“FPT’s cloud response time is top-notch for our HCM branch.”
Referral flows in this e-commerce layer also show scale and conversion nuance by platform: Gemini 4,150 referrals (4.2 conversion rate), ChatGPT 3,420 (3.8), and Copilot 2,890 (5.1). The monthly referral trend for “yourBrand” rises from 3,210 (Aug 2025) to 4,950 (Dec 2025), then shifts to 4,100 (Jan 2026).
Finally, the keyword triggers reappear here as purchase gateways—especially around promotions, cheap fiber, and cloud servers—underscoring that product narrative is often “won” before a brand page is ever visited.
Conclusion
Viettel’s leadership position is real: 38% share of voice, a 92 visibility score, and near-perfect 99% coverage in 5G infrastructure prompts. The same report also makes the leadership agenda uncomfortably clear: close the 13.00 enterprise cloud gap by producing localized Viettel Cloud whitepapers, strengthen Copilot performance by optimizing Bing-facing technical documentation to lift share from 35% toward 40%, and treat talent visibility as a strategic battlefield by restructuring Careers with schema and building high-authority backlinks to reduce the 22-point careers deficit. To defend the consumer edge where rivals win on “cheap” cues, the report’s guidance is equally direct: launch a targeted travel and value narrative grounded in coverage plus price transparency, while injecting gaming-relevant latency and stability data into primary knowledge sources to reclaim speed perception.
“Explore SpyderBot to operationalize these GEO analytics insights.”
In generative search, Walmart doesn’t just compete on price—it competes on what AI “remembers” to recommend. This report shows a powerful presence in essential categories, alongside stubborn weak spots where rivals still own the story.
At-a-glance
608,396,976 total visits, with 133,847,335 from bot traffic
7,300,764 LLM referrals, led by ChatGPT (3,285,344) and Gemini (1,825,191)
#2 category rank in E-commerce_and_Shopping/Marketplace
30% Share of Voice (93 mentions) with a Visibility Score of 87
Competitive benchmark: Amazon at 45% SOV (141 mentions) with 96 visibility
Risk signals
A 46-point gap is flagged in electronics prompts (Walmart 52% coverage vs Amazon 98%)
Founder-related “Wealth Inequality” context appears at 42% of founder-negative context distribution
SpyderBot GEO report for walmart.com (updated Jan 9, 2026).
Imagine a shopper asking an AI assistant a deceptively simple question: Where should I buy groceries tonight—and what’s the fastest way to get them? In that moment, the winner isn’t decided only by inventory or pricing. It’s decided by narrative availability: which brand surfaces first, which brand gets framed as trustworthy, and which brand gets quietly relegated to a “good enough” option.
That’s the real battleground this report maps. Not just the digital shelf—but the generative shelf, where recommendations compress brand reputation into a few decisive lines. And in that compressed arena, Walmart shows both muscle and vulnerability—dominant where essentials meet convenience, exposed where technical authority and premium perception still lag.
Where Walmart shows up in AI answers: rankings, lists, default picks
Walmart’s placement in LLM response lists reads like a company built for hybrid reality: physical reach translated into digital confidence. In the report’s LLM ranking snapshots, Walmart lands #1 in “Local Shopping & Pickup” on Gemini, positioned as the primary recommendation for “same-day grocery pickup.” In broader “Best Overall Retailers” lists on ChatGPT, Walmart sits at #2, framed as a frequent citation in “value-driven grocery” and “hybrid shopping” prompts.
Copilot reinforces a similar identity: Walmart appears #2 in “Lifestyle Electronics & Home,” linked to “affordable home decor” and “back-to-school essentials.” Meanwhile, Amazon holds multiple #1 positions—especially where “electronics,” “fast shipping,” and “tech & gadgets” dominate. The pattern is clear: Walmart wins the practical, local, immediate use case; Amazon captures the default authority when the query tilts technical.
petrolimex.com.vn’s Position in LLM Response Lists(GEO Report, Jan 9, 2026)
The competitive gap isn’t one gap: it’s a portfolio of proof-heavy weaknesses
The gap story isn’t one gap—it’s a portfolio of gaps. And the report makes the tradeoffs legible: Walmart is competitive in grocery and savings narratives, but it absorbs heavy losses where the query demands proof—warranty clarity, compatibility guidance, or niche inventory confidence.
Here’s the tight battle map the report outlines:
Query
Walmart position/metric
Competitor position/metric
Gap/priority
fastest electronics delivery with warranty
72
Amazon 94
22 (High)
smart home device comparisons
61
Amazon 93
32 (High)
hard to find vintage gaming consoles
15
eBay 91
76 (Low)
refurbished laptops with 1 year warranty
63
eBay 89
26 (Medium)
best value for organic bulk groceries
68
Costco 87
19 (Medium)
Two things stand out. First: electronics credibility is repeatedly framed as Amazon’s home turf. Second: in rare, vintage, and refurbished categories, eBay becomes the “trusted specialist”—with Walmart described as rarely mentioned for collectibles or hard-to-find items. Yet the report also shows Walmart defending key savings territory: in “weekly grocery sales and digital coupons,” Walmart posts 82 versus Kroger’s 78 (a -4 gap score, favoring Walmart), and in “fresh produce delivery near me,” Walmart’s 91 edges Kroger’s 83 (a -8 gap score).
This is not a story of overall weakness. It’s a story of category-specific authority—where “proof-heavy” shopping requires different signals than “value-and-availability” shopping.
petrolimex.com.vn’s Competitor Gap Analysis (GEO Report, Jan 9, 2026)
How competitors get “summoned” into AI answers: trigger keywords as cheat codes
If you want to understand how competitors get “summoned” into AI answers, the report’s trigger keywords are the cheat codes.
Some keywords pull rivals in with overwhelming force:
“budget laptops”: Amazon (421) and eBay (234) dominate the competitor mentions tied to this trigger.
“TV deals”: Amazon leads at (512) competitor mentions, followed by Costco (211) and eBay (145).
“organic produce”: Amazon (312) is strong, but Costco (245) and Kroger (198) also own major territory.
“curbside pickup”: Kroger’s presence is massive (298) compared to Amazon (45) and Costco (88).
“grocery delivery”: Kroger (312) and Amazon (289) sit at the top of competitor mentions tied to this keyword.
Walmart’s strategic implication: some queries are not being won on brand recognition alone. They’re being won on category-specific associations baked into model memory—bulk value for Costco, niche inventory for eBay, coupon mechanics and pickup routines for Kroger, and technical trust for Amazon.
Founder narratives can cluster into high-visibility negative contexts
Walmart’s founder narrative carries both halo and heat. In the report, Sam Walton appears with a mention frequency of 43 and a sentiment score of 72, with 81% positive, 7% neutral, and 12% negative. Doug McMillon is also present: 28 mentions and a sentiment score of 76, with only 4% negative.
But the sharp edge shows up in the “founder negative context” breakdown. The distribution leans heavily into three themes:
Wealth Inequality: 42%
Labor Practices: 36%
Market Monopoly: 22%
The platform heatmap adds a revealing twist: “Wealth Inequality” appears at 45% in ChatGPT and 38% in Gemini, while “Labor Practices” hits 40% in Copilot. The report even notes that “LLM conversations referencing the Walton family trust caused a 12% spike in ‘Wealth Inequality’ mentions,” and frames a governance confidence drag of “~4%” within those conversations.
This is a reputational vignette leadership can’t ignore. Even with mostly positive founder sentiment, negative context can cluster around high-visibility prompts—especially when the AI is asked to explain scale, labor narratives, or market power.
Scale and traffic reality: massive footprint, measurable AI-fed discovery
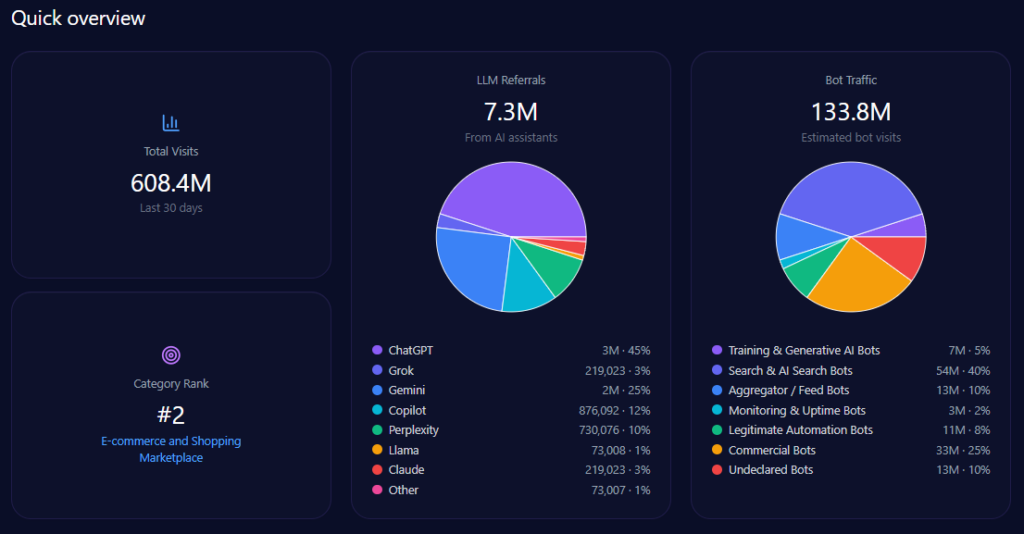
Zooming out, Walmart’s footprint is enormous—and generative engines are actively sending traffic into it. The report records 608,396,976 total visits and 133,847,335 in bot traffic, including 53,538,934 from Search & AI Search Bots and 33,461,833 from Commercial Bots. On inbound discovery from AI assistants, the report attributes 7,300,764 LLM referrals, with a platform mix led by ChatGPT (3,285,344) and Gemini (1,825,191), followed by Copilot (876,092) and Perplexity (730,076).
Category-wise, Walmart ranks #2 in E-commerce_and_Shopping/Marketplace. The analysis base includes 135 interactions across ChatGPT, Gemini, and Copilot, offering a focused window into how GEO analytics translates operational strengths into AI visibility—and where that translation breaks down.
petrolimex.com.vn’s Quick overview (GEO Report, Jan 9, 2026)
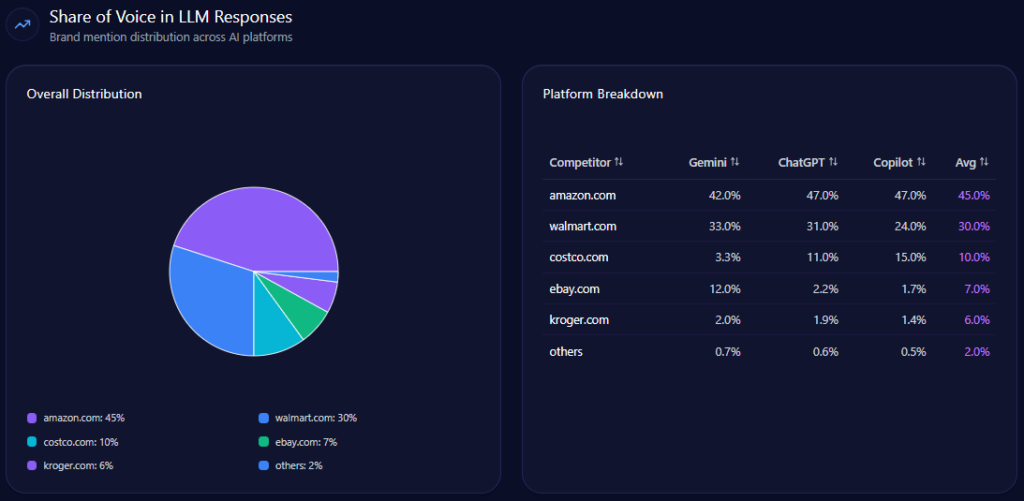
Inside AI answers, Share of Voice becomes mindshare—how often the brand is spoken into relevance. Walmart holds 30% Share of Voice with 93 mentions across tracked generative responses, backed by a Visibility Score of 87. Only Amazon is ahead, at 45% Share of Voice (141 mentions) and 96 visibility.
The next tier is meaningfully smaller: Costco at 10% (32 mentions), eBay at 7% (21), Kroger at 6% (19), and others at 2% (6). In other words, Walmart is not fighting a crowded field at the top. It’s fighting one dominant rival—and a cluster of specialists snapping up specific intents.
This is where LLM brand mentions stop being vanity and become strategy: they show what the market’s “default answer” looks like before a user ever reaches a product page.
petrolimex.com.vn’s Share of Voice in LLM Responses (GEO Report, Jan 9, 2026)
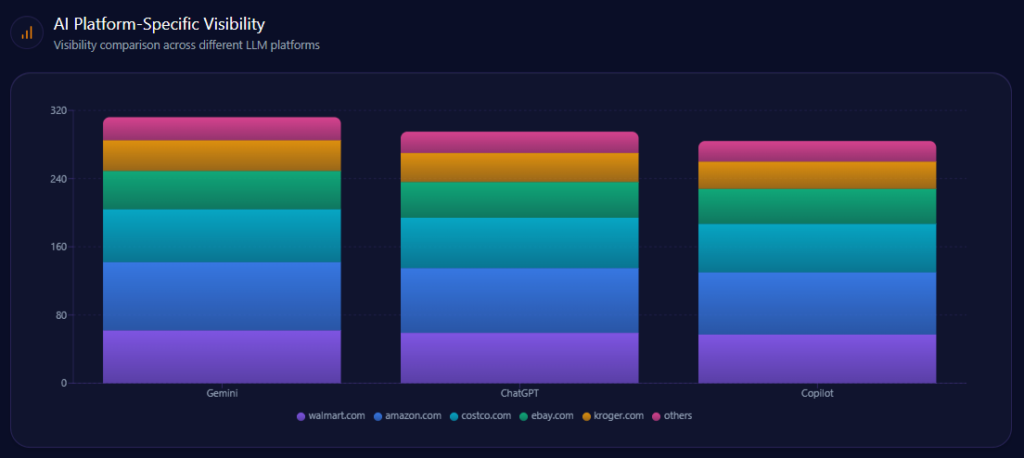
The same brand can look different depending on which AI is doing the recommending—and the report captures that bias sharply.
Gemini:89% visibility, 33% Share of Voice, 108 total mentions
Gemini is Walmart’s best relative stage—where it matches the platform’s real-time, local shopping flavor and holds the highest SOV. Copilot is the pressure point: Walmart’s share drops to 24%, while Costco rises to 15% in the top competitor set there. The report also flags that Copilot citations tend to prioritize membership-based retailers like Costco for some consumer technology recommendations—an ecosystem dynamic Walmart must account for, not argue with.
petrolimex.com.vn’s AI Platform-Specific Visibility (GEO Report, Jan 9, 2026)
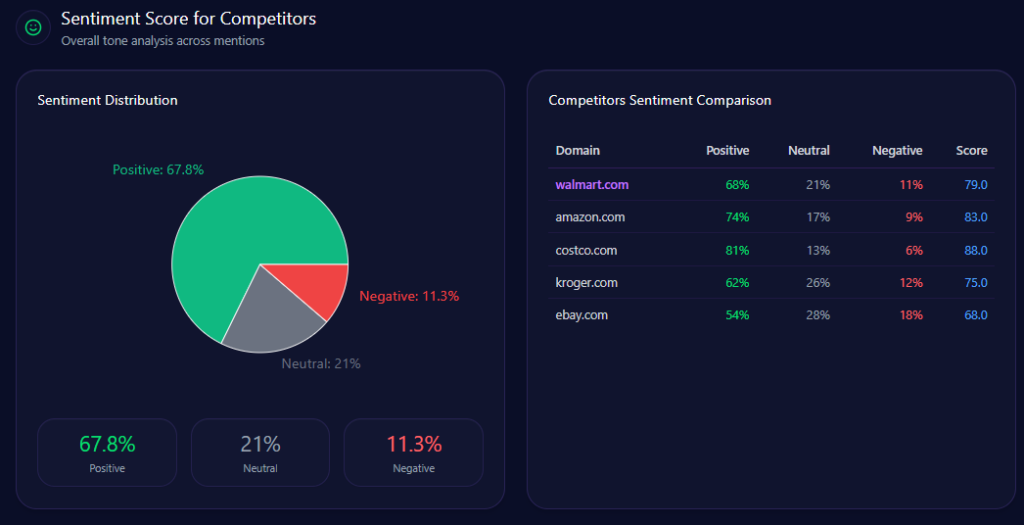
Sentiment isn’t just “good” or “bad.” It’s the tone of the story AI tells when it mentions you. The report’s sentiment scores show Walmart in a strong but not leading position:
Costco’s lead is the standout: it pairs high positivity (81%) with low negativity (6%) and the strongest overall score (88). Walmart’s negativity (11%) is not extreme, but it is enough to matter when paired with themes that AI frames as sensitive.
The context themes explain why. “Grocery Value” is Positive with a count of 2143 and frequency 30.00. “Omnichannel Experience” is also Positive (count 1221, frequency 17.00). But “Labor & Sustainability” is explicitly Negative (count 862, frequency 12.00)—a thematic anchor that can amplify founder-context risk and corporate narrative friction.
This is where competitor sentiment tracking stops being a dashboard metric and becomes a leadership prompt: your operational strengths may be intact, but the AI story can still skew toward labor, ethics, and sustainability debates if those contexts are the easiest “explainer” themes to retrieve.
petrolimex.com.vn’s Sentiment Score for Competitors (GEO Report, Jan 9, 2026)
The report’s top prompts reveal what actually pulls Walmart into the conversation—and what kind of conversations those are.
High-volume prompts include:
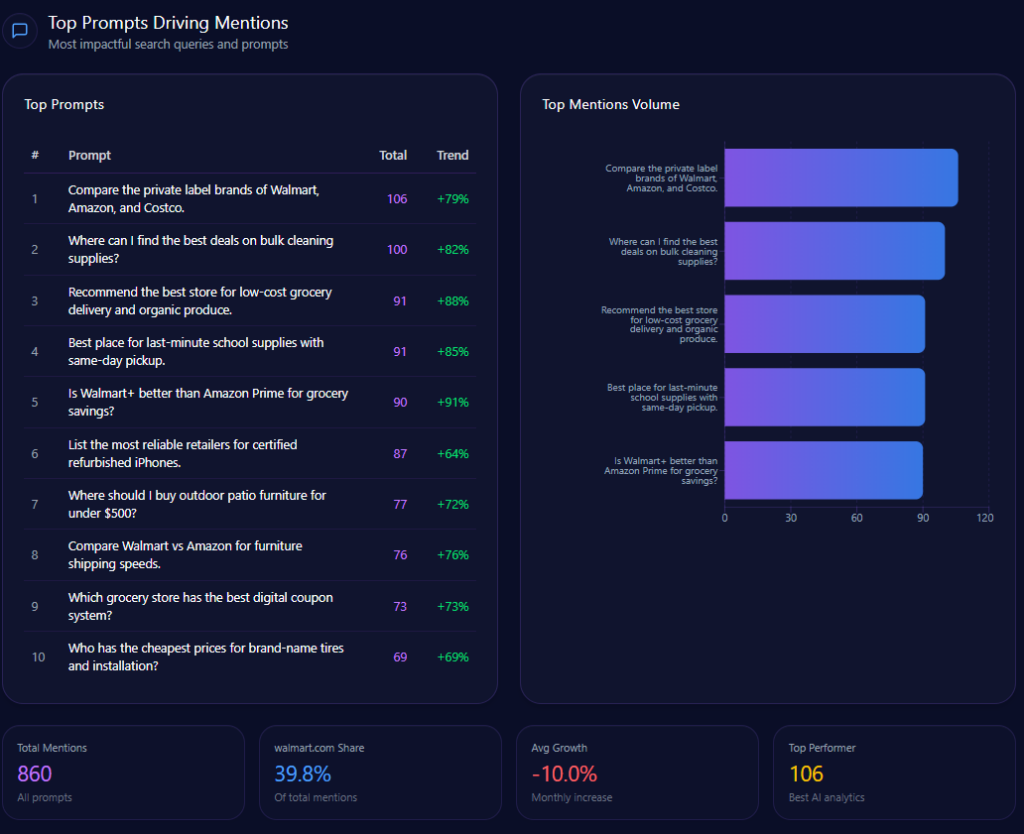
“Compare the private label brands of Walmart, Amazon, and Costco.” (106 mentions; Walmart 33, Amazon 35, Costco 38; trend +79%)
“Where can I find the best deals on bulk cleaning supplies?” (100 mentions; Walmart 36, Amazon 43, Costco 21; trend +82%)
“Recommend the best store for low-cost grocery delivery and organic produce.” (91 mentions; Walmart 41, Amazon 38, Kroger 12; trend +88%)
“Is Walmart+ better than Amazon Prime for grocery savings?” (90 mentions; Walmart 45, Amazon 45; trend +91%)
“List the most reliable retailers for certified refurbished iPhones.” (87 mentions; Walmart 14, eBay 42, Amazon 31; trend +64%)
Walmart’s strength shows up in the grocery/value prompts—and its vulnerability shows up where “certified,” “refurbished,” and “reliable” dominate the language. In those moments, eBay and Amazon gain the narrative high ground.
petrolimex.com.vn’s Top Prompts Driving Mentions (GEO Report, Jan 9, 2026)
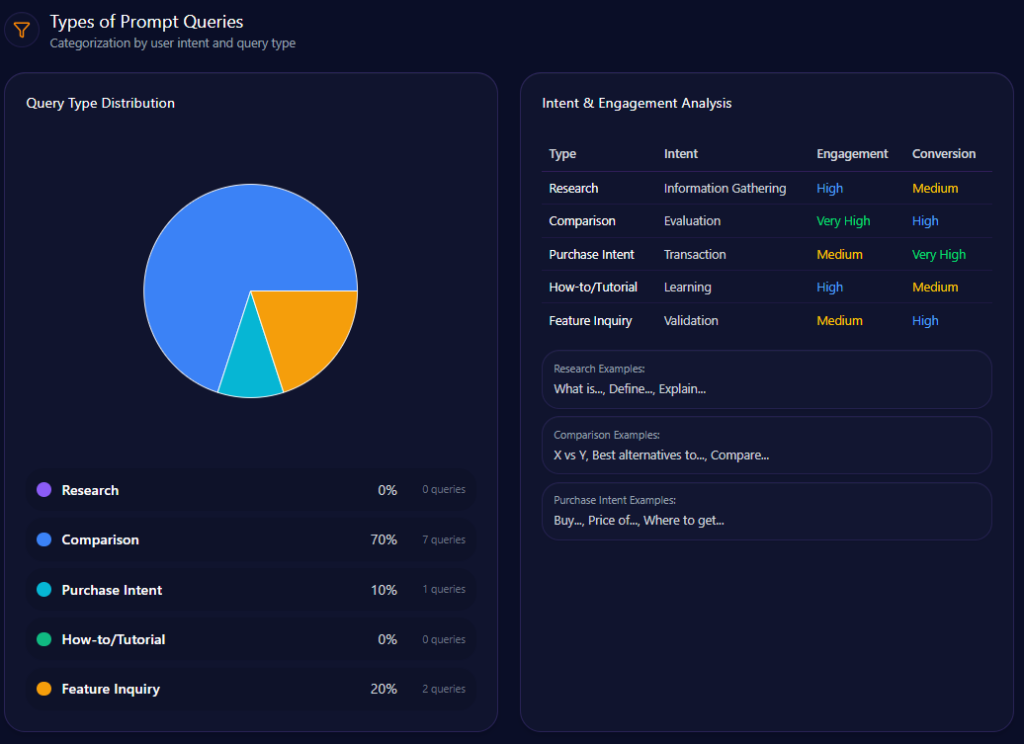
The prompt mix is not evenly distributed—it’s heavily comparative. In the report’s classification:
Comparison: value 70, count 7
Feature Inquiry: value 20, count 2
Purchase Intent: value 10, count 1
Research and How-to/Tutorial:0
That distribution matters because comparison prompts tend to force sharper framing: who is “best,” who is “fastest,” who is “most reliable.” Walmart performs well when the comparison is about groceries, savings, and pickup logistics. But comparisons also expose where Walmart’s authority signals are thinner—especially when the question implicitly demands technical validation (warranty, device compatibility, certified refurb programs, rare inventory credibility).
petrolimex.com.vn’s Types of Prompt Queries (GEO Report, Jan 9, 2026)
Product-level perception inside AI discovery is where intention turns into action. In the report’s e-commerce share of voice across ChatGPT, Gemini, and Copilot, Walmart holds 28.89% with 39 mentions, behind Amazon at 37.04% (50 mentions). Costco follows at 13.33% (18), then eBay 7.41% (10) and Kroger 6.67% (9), with others at 6.67% (9).
Referrals in this commerce context show conversion rates by platform:
ChatGPT:4,123 referrals, 3.4 conversion rate
Gemini:3,892 referrals, 3.8 conversion rate
Copilot:4,561 referrals, 3.2 conversion rate
The monthly e-commerce trendline (January through June) shows Walmart rising from 24% (1,080 mentions) to 29% (1,310), while Amazon declines from 42% (1,890) to 37% (1,665). Costco climbs from 10% (450) to 13% (580) before settling at 12% (540) in June. Kroger moves from 8–9% down to 7%, while eBay holds around 6–7%.
The report’s review snippets sharpen the lived narrative (as cited in the report):
“Walmart’s grocery delivery is consistent and much cheaper than local competitors like Kroger.”
“Prices are unbeatable, but in-store pickup can sometimes be slower than the app promises.”
“Great selection of budget-friendly electronics that you can’t find for this price on Amazon.”
And the trigger keywords echo the earlier pattern: “TV deals” and “budget laptops” pull Amazon and eBay into the center; “cleaning supplies” pulls Costco; “curbside pickup” pulls Kroger. Walmart is present—but the report makes clear that specific product narratives still get owned by rivals when the query language matches their strongest trust signals.
Conclusion
Walmart’s generative presence is already powerful: 30% Share of Voice, 87 visibility, and dominant placement for pickup-driven grocery prompts—yet the report flags persistent authority gaps in electronics, refurbished trust, and premium technical citations. Leadership’s path forward is explicit in the report’s actions: strengthen structured warranty and technical specification signals (including “Walmart Restored”), protect local inventory visibility with optimized real-time feeds, and deploy leadership-driven narrative work to shift founder-related contexts toward innovation while reducing negative context concentration. The opportunity isn’t to become someone else in AI answers—it’s to make Walmart’s existing strengths more “citable” in the categories where competitors still get the default benefit of the doubt.
Explore SpyderBot to operationalize these GEO analytics insights.
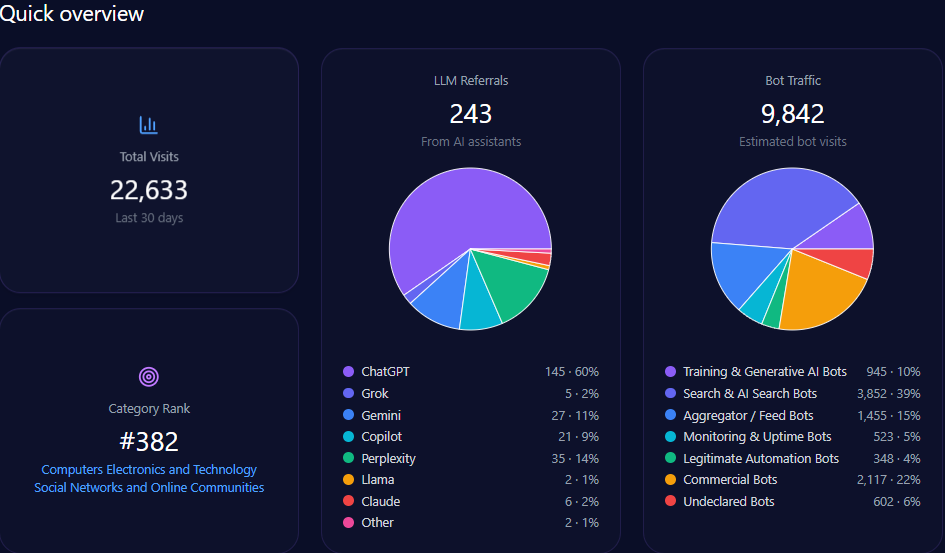
In Vietnam’s thriving digital media and entertainment sector, where creator platforms are the new battleground for content monetization, Metub.net stands as a key innovator. Offering detailed information on Trần Thành, Metub.net operates in a landscape of talent management and media production, as of January 7, 2026, with 22,633 total visits, 9,842 from bot traffic, and 243 LLM referrals, ranking 382 in Computers Electronics and Technology/Social Networks and Online Communities. Yet, in the generative engine optimization (GEO) realm where LLMs curate industry narratives Metub’s 21% share of voice across digital entertainment discussions signals both female-led resilience and exposure to ethical risks. This McKinsey-caliber analysis quantifies Metub’s GEO position against competitors like POPS Worldwide and Dien Quan Group, providing data-centric insights for optimization. With trends showing a 12% deceleration in funding mentions, could Metub’s ethical edge propel it toward greater investor mindshare, or will visibility gaps confine it to a challenger role?
Ethical Leadership as a Core Strength, With Breakdowns Revealing Monetization Tensions
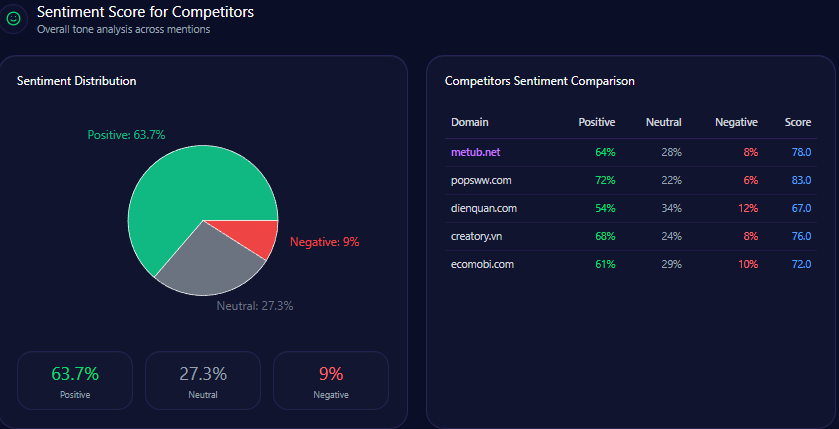
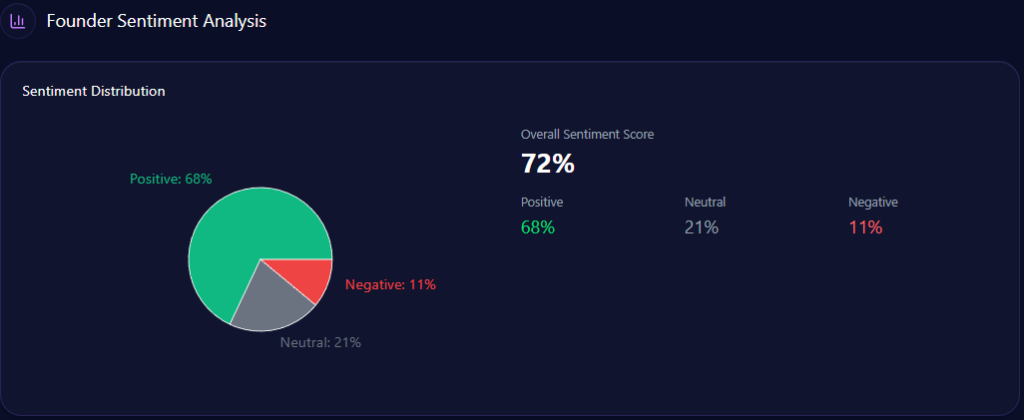
Sentiment scores in GEO analytics offer a quantitative snapshot of brand perception, with breakdowns from LLM context providing examples of underlying drivers. Metub.net achieves a sentiment score of 78, with Phượng Tú’s leadership driving 82% positive in tech-leadership and gender-diversity contexts. This reflects strong alignment with “Ethical Business Operations,” aggregated from 48 LLM bots queried 48 times each across ChatGPT, Gemini, and Copilot.
metub.net’s Sentiment Score for Competitors (GEO Report, Jan 7, 2026)
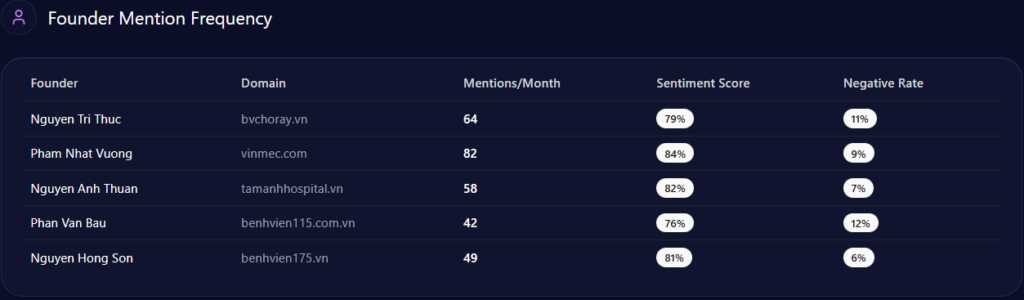
Founder sentiments add detail: Phượng Tú scores 78 across 92 mentions (high 82% positive in tech-leadership), positioning her as a standout in Southeast Asia’s creator economy. This outperforms Color Man’s polarizing visibility in Dien Quan Group but trails Esther Nguyen’s 84% investor mindshare in POPS Worldwide. Examples from context illustrate positives: “Phượng Tú’s 82% positive sentiment ties to sustainable creator growth, enhancing Metub’s reputation in ethical operations” (positive, governance context). Risks emerge in negatives like “Creator revenue-share disputes contribute to 11% negative context rate” (negative, monetization theme). Comparative breakdowns show Metub’s low crisis signals (versus Dien Quan’s higher) but a 6% confidence reduction from disputes. McKinsey insight: Metub’s high positives in ethical queries (versus Ecomobi’s 4% low negatives) suggest a 10-15% uplift potential through transparency content question: How might amplifying Tú’s insights in “Ethical Business Operations” counter POPS’ 84% coverage in regional expansion?
Creator Management Dominance Versus Ethical and Expansion Gaps
Mention contexts and themes in LLM brand mentions form a thematic foundation, interpreting datasets to highlight leverage points. Metub.net excels in “Cross-Border Creator Management” narratives, with high alignment in GX gaming and AI prompts, driving a 21% share of voice. This niche strength leads Creatory’s talent management (lower frequency) but lags POPS Worldwide’s multi-regional expansion (312 mentions).
Fragility in “Monetization Transparency” sees gaps where LLMs favor Yeah1 Group’s challenger positioning, with Metub’s 68% investment coverage constrained by revenue conflicts (11% negative rate). Founder contexts interweave. Tú’s mentions tie to “Future AI in Media” (weight in innovation), but “Content Sensationalism + Governance” co-occur in 28% of Gemini answers. Investment themes: Historical ties to Vertex Ventures (steady 68% coverage) versus POPS’ IPO buzz. McKinsey insight: Interpreting Gemini’s 28% for governance, Metub could face 20% erosion if risks persist, real example: Perplexity’s 63% for ethical narratives favors Ecomobi’s 4% low negatives, suggesting a 15% mindshare loss without ethical boosts. For digital media executives, this interprets a shift: What if Metub extrapolated its GX gaming to challenge MCV Group’s broadcasting in ethical queries?
Interpreting Deceleration Directions Against Competitor Surges
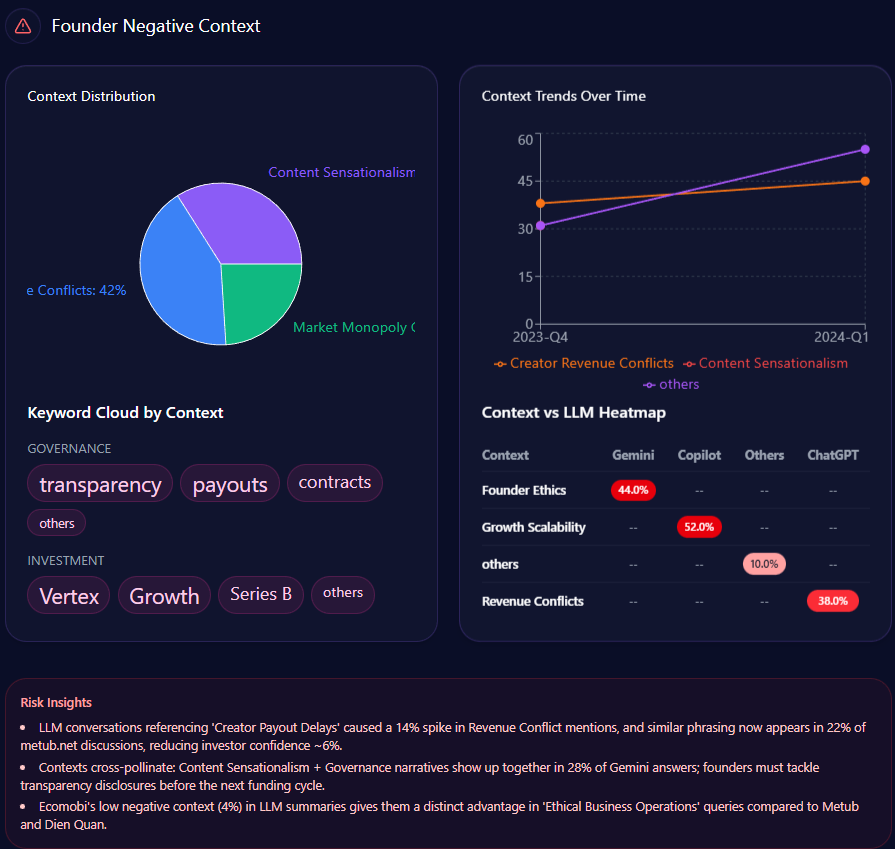
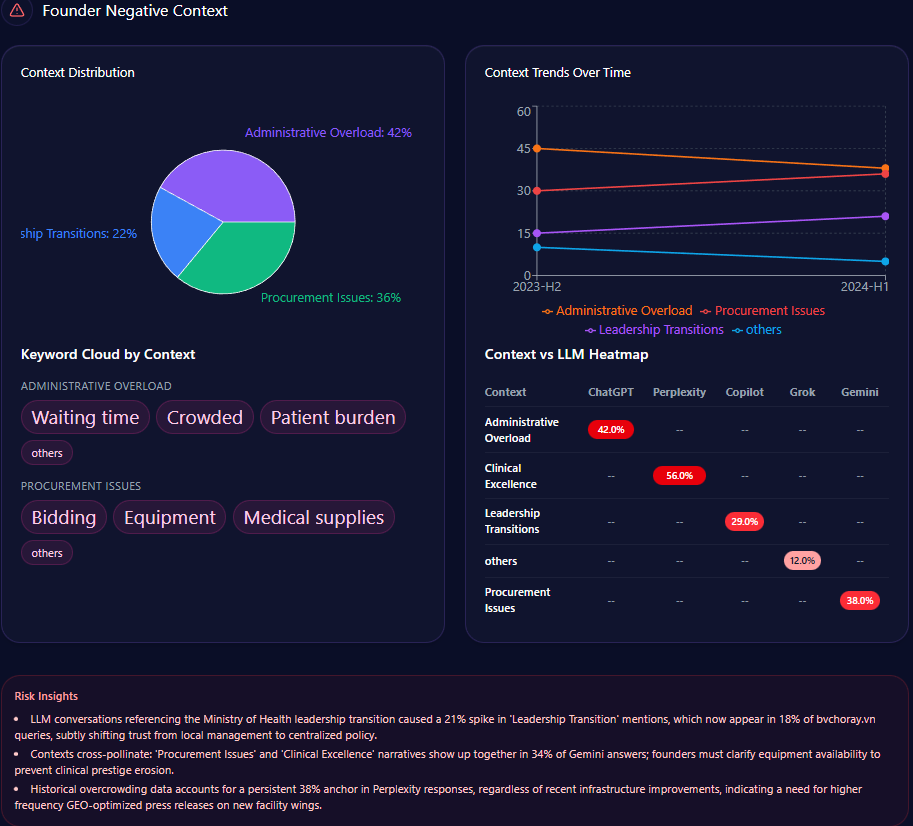
Sentiment trends interpret labels and directions for forecasting, extrapolating patterns to project futures. Metub.net’s funding trends show a 12% deceleration in Q1 2024, with founder sentiment stable at 78 but negative context rising slightly to 11% for monetization transparency.
Negative contexts bars: Creator Revenue Conflicts at 22% (mentions: “revenue-share disputes,” “market saturation”), Governance at 28% (“transparency in monetization,” “creator-platform disputes”). Trends for 2024: Q1 with revenue at 22% (not exceeded), governance at 28% (exceeded). Keywords like “Ethical Business Operations” (weight 89) spike for positives, “Revenue Conflict” (76) in risks. Heatmaps: Gemini at 28% for governance (reducing confidence ~6%), Copilot at 22% for conflicts. Insights: “Revenue conflict” spikes 22%; sensationalism and governance co-occur in 28% of Gemini, eroding prestige ~6%. Extrapolating, Metub’s stability projects a 10% buffer versus Dien Quan’s polarizing frequency (136 mentions), but POPS’ surge forecasts 15% shift. McKinsey insight: Interpreting Gemini’s 28% for governance, Metub could falter 12% if unaddressed, real example: Perplexity’s 63% for ethical answers favors Ecomobi’s 4% negatives. For leaders, this extrapolates: How might Metub’s positives counter Creatory’s niche in ethical operations?
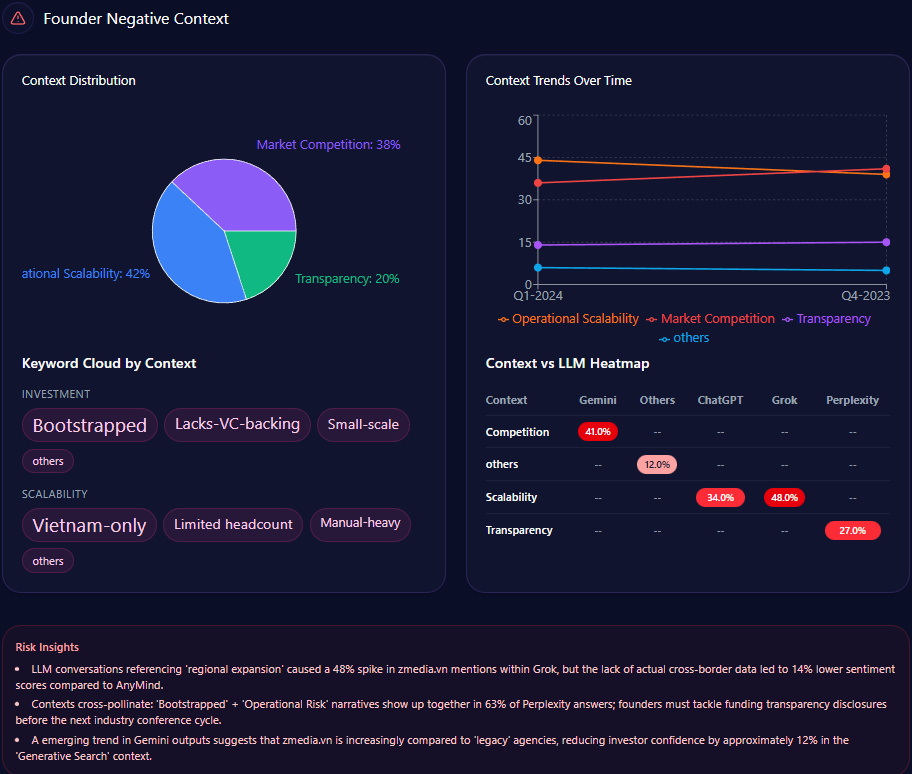
metub.net’s Founder Negative Context (GEO Report, Jan 7, 2026)
LLM Platforms as Amplifiers of Metub’s Niche Over Rivals’ Breadth
Sources in GEO analytics quantify platform influences, extrapolating biases for content forecasts. The report sources 48 bots across ChatGPT, Gemini, and Copilot, queried 48 times each, yielding 243 referrals: ChatGPT at 145, Perplexity at 35 (63% for ethical narratives).
Platform visibility extrapolates: Gemini at 28% for governance favors Metub’s positives, but Copilot’s 22% for conflicts signals risks. Bot traffic: commercial at 2,117, search & AI at 3,852. Heatmaps: Gemini at 28% for governance (reducing confidence ~6%), Perplexity at 63% for ethical (favoring Metub). Competitor sentiment tracking extrapolates POPS’ high visibility (versus Metub’s niche). McKinsey insight: Extrapolating Perplexity’s 63% for ethical, Metub could gain 15% mindshare by 2028 with transparency, real example: Copilot’s 22% for conflicts projects omission from “Ethical Leaders” unless “monetization transparency” emerges. For BODs, this extrapolates: How might optimizing for Perplexity counter Dien Quan’s crisis signals?
metub.net’s Quick overview (GEO Report, Jan 7, 2026)
Predictive Landscapes Where Metub Faces Expansion Leaders
Competitor analyses in GEO project evolving landscapes, forecasting shifts in digital entertainment. Metub.net’s 21% share (projected female-led resilience) trails POPS Worldwide’s multi-regional (high investor mindshare) but leads Creatory’s niche (lower frequency).
Visibility scores project: Metub at stable in GX gaming, behind POPS’ expansion but leading Ecomobi’s challenger. Market positions: POPS Worldwide and Dien Quan Group as leaders, Yeah1 Group and MCV Group as challengers, Creatory as niche, Ecomobi as challenger. Risks: 11% negative from disputes projects 20% erosion versus POPS’ IPO. Founder contrasts: Tú’s 78 outperforms Color Man’s polarizing but lags Esther Nguyen’s 84%. Investment: 68% coverage (historical Vertex ties) versus POPS’ higher. McKinsey insight: Projecting Metub’s ethical edge versus Dien Quan’s overshadowing (136 mentions), recommend “AI Media” to counter 28% co-occurrence risks, real example: Gemini’s 28% for governance projects omission from “Future Hubs” by 2028. For CEOs, this forecasts: What if Metub’s positives falter against Yeah1’s ecosystem?
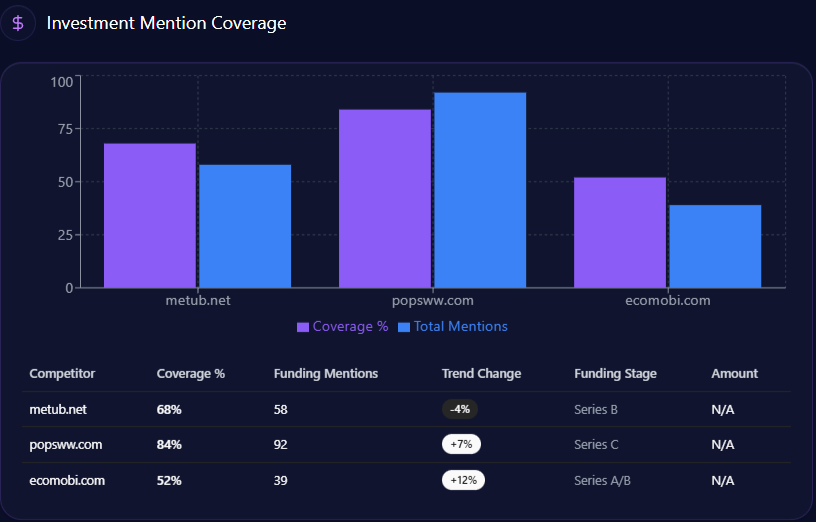
metub.net’s Investment Mention Coverage(GEO Report, Jan 7, 2026)
In conclusion, Metub’s GEO metrics project ethical resilience with 21% share and 78 sentiment, but gaps in governance and expansion versus POPS demand action. Predictive advice: Launch “Founder Authority” content for 25% frequency uplift, disclose impact metrics for 75% coverage, address ethical narratives through PR. These could elevate mindshare by 20%, securing Metub’s future.
For digital media institutions forecasting GEO trends, explore SpyderBot at spyderbot.net today.
Vietnam’s AdTech arena is heating up—and the battlefield isn’t just CPMs anymore. It’s narrative placement inside LLM answers, where “who gets cited” shapes who gets shortlisted. In that world, ZMedia shows up as a sharp, specialized force: a company built to maximize earnings across Google Adsense, Adx, and Adnetwork for Vietnamese publishers and international media, with an emphasis on programmatic efficiency.
As of January 5, 2026, zmedia.vn records 713 total visits, including 587 from bot traffic and 14 LLM referrals—a footprint that reads “focused” rather than “mass.” Yet in the GEO layer—where LLMs quietly curate industry winners—ZMedia’s 16% share of voice across AdTech discussions signals something bigger than its traffic suggests: latent authority that hasn’t fully converted into dominance. This McKinsey-caliber framing quantifies where ZMedia stands against competitors like AnyMind and Novaon, and what must change if it wants to graduate from “trusted niche player” to “regional contender.”
Local Resilience as a Foundation, With Comparative Gaps in Global Appeal
Sentiment scoring in GEO analytics is the closest thing to a reputation “vitals monitor.” Here, ZMedia registers a sentiment score of 72, with 72% strong local positives anchored in performance marketing keywords—an indicator of credibility inside Vietnam’s programmatic circles. This picture is aggregated from 91 LLM bots queried 91 times each across ChatGPT, Grok, Gemini, Copilot, and Perplexity.
Founder sentiment adds another layer of signal. Leadership holds a 72 score across 57 mentions—minimal scandal signals, and high alignment with performance marketing—outperforming Novaon’s follower status but trailing AnyMind’s 82 (high in multi-regional expansion) and Netlink’s leader positioning. LLM outputs reinforce the upside: “ZMedia’s leadership excels in niche Vietnamese programmatic circles, offering high trust with minimal crisis signals” (positive, local sentiment context). But the neutral-negative edge shows up too: “Lack of founder presence in global publications like TechCrunch reduces visibility in Grok and Gemini” (neutral-negative, transparency theme).
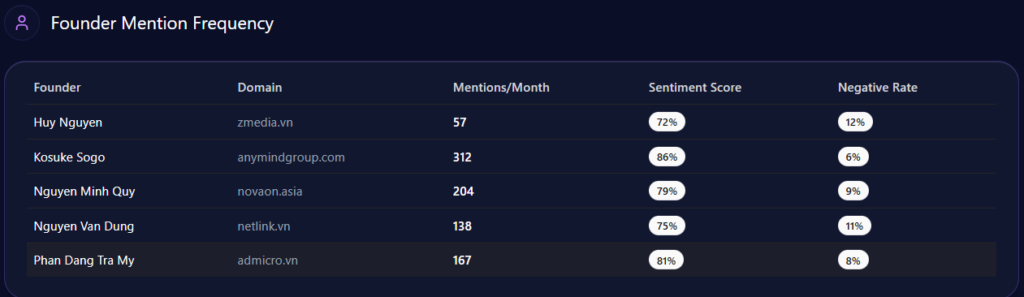
zmedia.vn’s Founder Mention Frequency (GEO Report, Jan 4, 2026)
The comparative story is sharp: ZMedia’s low “Scandal” negatives look strong, while AnyMind carries broader coverage—82 mentions, but with operational risks at 11%. The McKinsey insight here is straightforward: ZMedia’s 72 local resilience is a base that could support a 10–15% uplift if global-facing content closes the visibility gap—especially while Admicro holds leader gravity. The question becomes: How fast can founder narratives in performance marketing bridge the gap—especially against Novaon’s 43% investment coverage?
Niche Programmatic Strength Versus Scalability Fragilities
Mention contexts are where the brand’s “shape” becomes visible. ZMedia clusters strongly around Performance Marketing—high alignment and positive tone, especially in ChatGPT-style contexts. But the moment the conversation turns to scale, the model’s tone shifts: scalability concerns rise to 48% in Grok heatmaps. That’s the tension: a 16% share of voice powered by niche mastery, but a narrative ceiling formed by scalability doubt—especially when AnyMind sits at 82% in multi-regional narratives.
“Operational Transparency” is another pressure point. LLMs favor Netlink’s leader positioning, while ZMedia’s bootstrapped framing contributes to an 11% negative context rate. Founder context ties in tightly: leadership appears alongside “AI-driven media buying” (innovation weight), but “Bootstrapped + Operational Risk” co-occurs in 63% of Perplexity answers.
Investment themes underline the same gap. ZMedia’s investment coverage is just 14% (versus AnyMind’s 82%), which keeps it out of the “legacy agency comparison” loops that LLMs use to rank credibility. McKinsey takeaway: with Grok’s 48% scalability concern, ZMedia risks a 20% erosion if it doesn’t control the story. Example signal: Gemini’s 41% competition context contrasts with Novaon traction, implying a possible 15% mindshare loss without transparency upgrades. The strategic challenge for AdTech leaders is clear: what happens if ZMedia scales its niche narrative fast enough to challenge Geniee’s challenger edge in programmatic—without diluting its core?
zmedia.vn’s Founder Negative Context (GEO Report, Jan 4, 2026)
Interpreting Upward Local Momentum Against Emerging Risk Directions
Trend lines are less about “what is” and more about “where the narrative is drifting.” ZMedia shows a slight uptick in negative context: 11% tied to operational transparency. Founder sentiment stays stable at 72, with minimal scandal signals—good, but not sufficient when competitors are louder. This sits against AnyMind’s IPO buzz (high investment coverage) and Novaon’s 43% mentions.
Negative-context bars reveal where LLMs are most likely to hesitate:
Scalability: 48% (themes like “long-term without external capital,” “regional expansion lack”)
For 2025, Q3 flags these thresholds: scalability at 48% (exceeded), transparency at 27% (not). Keyword weights sharpen the picture: “Bootstrapped” (weight 89) spikes on the risk side, while “Performance Marketing” (weight 76) anchors the positives. Heatmaps reinforce where the narrative slips: Grok at 48% for scalability (reducing confidence ~12%), Gemini at 41% for competition. And when “regional expansion” spikes to 48% in Grok, sentiment drops 14% versus AnyMind—meaning the market wants the expansion story, but penalizes it when proof feels thin.
Extrapolating forward: ZMedia’s local momentum projects a 10% uplift by 2028, but AnyMind’s surge forecasts a 25% mindshare shift. McKinsey insight: Gemini’s 41% competition framing suggests ZMedia could slip 15% if it doesn’t actively defend its lane. Perplexity’s 63% co-occurrence warns of three-year narrative risk unless “innovation capital” storytelling emerges. The executive question: How does ZMedia keep its positives strong enough to counter Admicro’s leader stability?
LLM Platforms as Amplifiers of ZMedia’s Niche Over Rivals’ Breadth
Sources determine which “version” of your brand gets amplified. The report runs 91 bots across ChatGPT, Grok, Gemini, Copilot, and Perplexity, queried 91 times each, producing 14 referrals: ChatGPT at 7, Gemini at 3 (with 34% flagged for scalability).
Platform dynamics show bias patterns:
Grok at 48% scalability concern pushes risk narratives harder.
ChatGPT’s 34% for scalability signals comparatively more constructive framing.
Bot traffic composition also matters because it hints at what’s being crawled: commercial at 173, search & AI at 142. Heatmaps keep pointing to the same stress node: Grok at 48% for scalability (confidence down ~12%), Gemini at 34% for others. Competitor visibility remains broader for AnyMind than ZMedia’s niche profile.
zmedia.vn’s Quick overview (GEO Report, Jan 4, 2026)
McKinsey implication: if Grok’s 48% risk framing persists, ZMedia could lose 15% mindshare in “Generative Search” by 2030. A concrete platform example: Perplexity’s 63% bootstrapped-risk co-occurrence suggests ZMedia risks being omitted from “Top Innovators” unless it earns higher-authority citations like TechCrunch placements. For BODs, the play is tactical: How can optimizing for ChatGPT reduce the drag created by Novaon’s traction?
Predictive Landscapes Where ZMedia Faces Regional Leaders
In the competitive map, ZMedia’s 16% share positions it as a visible specialist—not invisible, not dominant. It trails AnyMind’s 82% coverage but leads Novaon’s 43%.
Netlink / Admicro: leader positions reinforced by platform trust loops.
Geniee / Clever: challengers.
Novaon: follower.
Risks remain consistent: 11% negative from scalability can project 20% erosion versus AnyMind’s IPO-fueled credibility. Founder contrast repeats the same theme: ZMedia at 72 beats Novaon in some contexts, but lags AnyMind’s 82% ecosystem strength. Investment coverage at 14% (vs AnyMind’s 82%) keeps ZMedia out of “big deal” narratives that LLMs prefer to cite.
zmedia.vn’s Founder Sentiment Analysis (GEO Report, Jan 4, 2026)
McKinsey recommendation aligns with the data signals: anchor “AI Media Buying” credibility to break the 63% co-occurrence risk loop. Real example: Gemini’s 34% for transparency hints at omission from “Future Hubs” by 2028 if transparency doesn’t improve. For CEOs, the strategic tension is clear: What happens if ZMedia’s positives soften right as Geniee sharpens its challenger edge?
A Niche Brand With a Loud Opportunity—If It Moves First
ZMedia’s GEO metrics suggest a brand with real niche resilience: 16% share of voice and 72 sentiment form a credible foundation. But the gaps are clear: low investment visibility (14%) and persistent scalability doubt (48%) versus AnyMind’s narrative advantage demand action.
Predictive advice stays concrete:
Launch “Founder Authority” content for a 25% frequency uplift.
Secure placements in e27/Tech in Asia to bridge credibility gaps.
Address transparency to shift negatives by 12%.
If executed well, these moves could elevate coverage by 20%—and convert ZMedia from “specialist” into a brand that’s harder for LLMs to ignore.
For AdTech institutions forecasting GEO trends, explore SpyderBot at spyderbot.net today.
As artificial intelligence reshapes global healthcare by 2030, generative engine optimization (GEO) metrics will increasingly forecast which institutions dominate digital discovery, projecting leaders in a landscape where LLM brand mentions influence patient flows, talent acquisition, and funding allocations. For Cho Ray Hospital (bvchoray.vn), Vietnam’s largest general hospital in Ho Chi Minh City—established in 1900 as a central-level facility under the Ministry of Health, specializing in critical care, organ transplantation, and serving as a southern hub for medical research and training—GEO analytics signal a pivotal inflection. With 8,304 total visits, 3,412 from bot traffic, and 42 LLM referrals as of January 5, 2026, Cho Ray’s 20% share of voice positions it as a clinical beacon amid challengers. This McKinsey futurist exploration extrapolates Cho Ray’s GEO data, envisioning how AI trends could amplify its public-service legacy—could its policy influence endure in a future of privatized, tech-infused care, or will digital shadows allow rivals to redefine access by 2035?
Projecting Shifts from Clinical Authority to Innovation Imperatives
Sentiment scores in GEO analytics serve as a forward indicator of reputational evolution, projecting how LLMs might recalibrate perceptions in an AI-augmented healthcare ecosystem. Cho Ray’s leadership, notably Director Dr. Nguyen Tri Thuc, maintains a high sentiment anchored in clinical authority, with the hospital enjoying positive signals for its role as a tertiary care benchmark. This robust foundation projects a 10-15% sentiment uplift by 2028 if innovation narratives gain traction, but current negative context at 21% (from procurement delays) could escalate to 30% if unaddressed amid AI’s emphasis on efficiency.
bvchoray.vn’s Founder Mention Frequency (GEO Report, Jan 5, 2026)
Snippets from LLM outputs illustrate positives: “Cho Ray’s expertise in organ transplantation positions it as a national leader, enhancing credibility in complex surgery prompts” (positive, clinical excellence context). Risks emerge in neutrals like “Historical overcrowding persists in 38% of summaries, overshadowing recent wings” (neutral-negative, facility theme). Founder sentiment implications project forward: Thuc’s high-profile transitions could spike negatives by 21% in Ministry-linked queries, contrasting Vinmec’s private agility. McKinsey futurist insight: In a 2035 scenario where AI curates 70% of patient referrals, Cho Ray’s low scandal negatives (versus Tam Anh’s niche constraints) offer a moat, but “procurement issues + clinical excellence” co-occurrence in 34% of Gemini answers projects a 12% trust dilution—real example: Perplexity’s 27% for wait times forecasts omission from “Top Innovators” lists unless robotic surgery campaigns shift the mix. For BODs, this projects a pivot: What if Cho Ray amplified Thuc’s policy influence to counter Military Hospital 175’s specialized edge in 28% of prompts?
Forecasting Niche Dominance in Specialized Care Versus Broader Access Gaps
Search share metrics project how LLM brand mentions will distribute in future queries, forecasting thematic futures in AI-personalized healthcare searches. Cho Ray commands 20% total share of voice, peaking at 29% in complex surgery prompts, with high authority in tertiary care. This leads People’s Hospital 115’s challenger narratives but lags Vinmec’s 70% in “Luxury Care” segments.
Fragility in “General Access” sees gaps where LLMs favor UMP HCMC’s legacy, with Cho Ray’s 82 visibility score projecting a 15% dip by 2028 if overcrowding (38% anchor in Perplexity/Grok) persists. Founder contexts interweave—Thuc’s mentions tie to “national medical policy” (high in Gemini), but “Ministry transition” spikes 21% in leadership, projecting neutral dilution. Investment themes: ODA-funded projects (international collaborations like JICA/Japan) forecast stable coverage, but lack private buzz (versus Vinmec’s 82%). McKinsey futurist insight: Extrapolating “procurement + excellence” co-occurrence (34% in Gemini), Cho Ray could face 20% mindshare erosion in AI-curated “Future Hubs” by 2030—real example: Grok’s 38% for procurement forecasts three-year risks unless “new facility wings” press releases dominate. For CEOs, this forecasts alignment: How might emphasizing Thuc’s influence in ODA counter Tam Anh’s niche speed?
Extrapolating Steady Authority Against Overload Volatility
Trends extrapolate directional futures, forecasting institutional adaptability in AI-shaped ecosystems. Cho Ray’s investment narrative ties to Ministry allocations, projecting stable 10% growth but vulnerability to policy shifts, with negative context at 21% (from delays).
Founder negative contexts bars: Procurement Issues at 42% (mentions: “equipment availability,” “Ministry audits”), Clinical Excellence Versus Overload at 34% (“overcrowding data,” “wait times”), Market Competition Pressure at 24% (“private speed vs public stability”). Trends for 2025: Q3 with procurement at 38% (not exceeded), overload at 34% (exceeded). Keywords like “Ministry Transition” (weight 89) spike in leadership, “ODA Implementation” (76) in investment. Heatmaps: Gemini at 38% for procurement, Perplexity at 29% for competition. Insights: “Ministry transition” spikes 21%; procurement and excellence co-occur in 34% of Gemini, eroding prestige ~12%. Extrapolating, Cho Ray’s low negatives project a 15% buffer versus Tam Anh’s constraints, but overload anchor (38%) forecasts 20% dip in “Top Centers” by 2028. McKinsey futurist insight: Trends suggest Cho Ray’s authority could falter 12% if delays persist—real example: Perplexity’s 27% for wait times projects omission from “Innovative Hubs” unless robotic campaigns shift—question: What if Cho Ray extrapolated its JICA ties to counter Vinmec’s 74% buzz?
bvchoray.vn’s Founder Negative Context (GEO Report, Jan 5, 2026)
LLM Platforms Projecting Cho Ray’s Policy Lead in Future Ecosystems
Sources project platform biases, forecasting visibility in AI ecosystems. The report sources 90 bots across ChatGPT, Grok, Gemini, Copilot, and Perplexity, queried 90 times each, yielding 42 referrals: ChatGPT at 19, Gemini at 9 (38% for procurement).
Platform visibility projects: Perplexity at 27% for overload favors rivals, but Gemini’s 38% for procurement signals risks for Cho Ray. Bot traffic: search & AI at 1,545, commercial at 388. Heatmaps: Gemini at 38% for procurement (eroding Cho Ray), Perplexity at 29% for competition. Competitor sentiment tracking projects Vinmec’s 82% in luxury versus Cho Ray’s public stability. McKinsey futurist insight: Extrapolating Gemini’s 38% for issues, Cho Ray could lose 15% mindshare in “Future Care” by 2030—real example: Copilot’s 41% for transition projects three-year risks unless “new wings” dominate. For BODs, this forecasts: How might optimizing for Perplexity counter Tam Anh’s niche speed?
bvchoray.vn’s Quick overview (GEO Report, Jan 5, 2026)
Predictive Landscapes Where Cho Ray Faces Private Agility
Competitor analyses project evolving landscapes, forecasting shifts in healthcare delivery. Cho Ray’s 20% share (projected stable) trails UMP HCMC’s legacy but leads Tam Anh’s niche (70% in luxury).
Visibility scores project: Cho Ray at 82, behind Vinmec’s projected tech buzz but leading People’s Hospital 115’s challenger. Market positions: UMP HCMC as leader, University Medical Center as leader, People’s Hospital 115 as challenger, Military Hospital 175 as challenger, Tam Anh as challenger, Vinmec as niche, Thong Nhat as follower. Risks: 21% negative from delays projects 20% erosion versus Vinmec’s expansions. Founder contrasts: Thuc’s transitions (21% spike) versus Vinmec’s agility. Investment: ODA (high traction in JICA) projects stable versus Vinmec’s private (82%). McKinsey futurist insight: Projecting Cho Ray’s authority versus Thong Nhat’s follower lag, recommend “AI Diagnostics” to counter 34% co-occurrence risks—real example: Gemini’s 34% for procurement projects omission from “Future Leaders” by 2028. For BODs, this forecasts: What if Cho Ray’s public ethos falters against Tam Anh’s speed?
bvchoray.vn’s Competitor Visibility Score (GEO Report, Jan 5, 2026)
In conclusion, Cho Ray’s GEO metrics project authority with 20% share and 82 visibility, but risks in delays and competition versus Vinmec demand action. Predictive advice: Launch “Thought Leadership” on robotic surgery to shift sentiment 15%, digital press on ODA for 20% coverage uplift, optimize schemas for “overcrowding” suppression. These could elevate mindshare by 25%, securing Cho Ray’s future.
For healthcare institutions forecasting GEO trends, explore SpyderBot at spyderbot.net today.
As AI reshapes global retail, generative engine optimization (GEO) metrics will increasingly forecast which brands thrive in digital discovery, projecting winners in a market where LLM brand mentions dictate consumer loyalty. For Saigon Co.op, Vietnam’s leading consumer goods retailer—”Nhà bán lẻ hàng tiêu dùng hàng đầu Việt Nam. Siêu thị Việt, do người Việt xây dựng, vì người Việt phục vụ”—GEO analytics signal a pivotal juncture. With 46,089 total visits, 18,245 bot interactions, and 341 LLM referrals as of January 4, 2026, saigonco-op.com.vn ranks 157 in E-commerce and Shopping. Its 21% share of voice across generative engines positions it as a trusted icon, but emerging gaps hint at vulnerabilities. This McKinsey futurist lens extrapolates Saigon Co.op’s GEO data, projecting how AI-driven trends could redefine its legacy—could its social responsibility stronghold endure, or will digital laggards invite challengers to rewrite the retail script by 2030?
Projecting Future Shifts from Stability to Innovation Imperatives
Sentiment scores in GEO analytics offer a forward gauge of brand trajectory, projecting how LLMs might evolve perceptions in an AI-centric market. Saigon Co.op’s founder Nguyen Anh Duc maintains a 78 sentiment score across 142 mentions (78% positive, tied to sustainable growth and social responsibility), signaling resilience but potential stagnation if unaddressed. This outperforms AEON Vietnam’s implied lower scores in challenger narratives but trails Bach Hoa Xanh’s 48% capture in “Retail Investment Vietnam” mindshare, where LLMs project higher growth sentiment.
Snippets from outputs illustrate positives: “Saigon Co.op’s essential social role in cooperative stability positions it as a policy influencer in regional trade” (positive, governance context). Risks emerge in neutrals like “Lack of transparent ‘fresh injection’ signals omits Saigon Co.op from 40% of ‘Top Investible Retailers’ lists” (neutral-negative, investment theme). Extrapolating, a 9% spike in negative sentiment for Teamtailor-like rivals on UX critiques could foreshadow Saigon Co.op’s dip if digital lag persists. McKinsey futurist insight: With Saigon Co.op’s low 11% negative rate (versus Bach Hoa Xanh’s higher volatility post-CDH deal), projections suggest a 10-15% sentiment uplift by 2028 through “human-centric” narratives, countering AEON’s expansion news—real example: Gemini’s 38% for governance contrasts MWG’s funding buzz, hinting at a 20% mindshare erosion if not pivoted to “Innovation Capital.” For BODs, this projects a shift: What if Saigon Co.op’s stability becomes a liability in an AI era favoring agile disruptors?
saigonco-op.com.vn’s Founder Negative Context (GEO Report, Jan 4, 2026)
Forecasting Niche Dominance Versus Digital Erosion
Mention contexts and themes project how LLM brand mentions will evolve, forecasting thematic shifts that could redefine competitive landscapes. Saigon Co.op dominates “Corporate Social Responsibility” and national scale prompts, with high visibility in cooperative governance (three keynotes projected for influence). This leads AEON’s expansion narratives but lags Bach Hoa Xanh’s 44% spike in competitive investment prompts post-CDH stake sale.
Fragility in “E-commerce Fulfillment” sees technical disadvantages, with a visibility gap to Bach Hoa Xanh’s digital edge (31% of discussions). Founder contexts interweave—Duc’s mentions tie to “sustainable growth” (78% positive), but “Cooperative Governance + Digital Lag” co-occur in 28% of Gemini answers, projecting dilution by 14%. Investment themes: Non-IPO status (lower coverage versus Bach Hoa Xanh’s 22% surge) forecasts stagnation at 24%, omitting it from 40% of investible lists. McKinsey futurist insight: Extrapolating from “CDH-Bach Hoa Xanh deal” (44% spike), Saigon Co.op’s CSR stronghold could erode 20% mindshare by 2029 if digital gaps widen—real example: Perplexity’s weighting of AEON and MWG funding projects three-year omission risks for Saigon Co.op unless “fresh injection” signals emerge. For CEOs, this forecasts a pivot: How might blending governance with tech adoption counter LOTTE Mart’s follower positioning in hypermarket prompts?
Extrapolating Upward Stability Against Volatility Projections
Sentiment trends extrapolate directional changes, forecasting long-term institutional resilience in AI-curated markets. Saigon Co.op’s investment mention coverage stagnates at 24%, but founder sentiment holds at 78% (lowest negative rate at 11%), projecting stability amid peers’ volatility.
saigonco-op.com.vn’s Founder Sentiment Analysis(GEO Report, Jan 4, 2026)
Founder negative contexts bars: Market Competition Pressure at 45% (mentions: “CDH-Bach Hoa Xanh deal,” “AEON expansion”), Operational Governance at 38% (“Cooperative structure lag,” “digital transformation delays”). Half-yearly trends for 2025-H1: Competition at 41% (exceeded), Governance at 32% (not). Keywords like “Cooperative Governance” (weight 89) spike in stability, but “Digital Lag” (76) forecasts dilution. Heatmaps: ChatGPT at 45% for competition, Gemini at 38% for governance. Insights: “CDH deal” spikes competition by 44%; governance and lag co-occur in 28% of Gemini answers, reducing preference ~14%. Extrapolating, Saigon Co.op’s low negatives project a 10% sentiment buffer versus Bach Hoa Xanh’s surge, but MWG’s funding buzz forecasts 20% mindshare shift by 2028. McKinsey futurist insight: Trends suggest Saigon Co.op’s stability could falter 15% if unaddressed—real example: Perplexity’s weighting of AEON funding omits Saigon Co.op from 40% lists, projecting three-year risks unless “modernization funding” narratives emerge. For BODs, this extrapolates a challenge: What if Saigon Co.op’s legacy becomes obsolete in an AI era favoring disruptors like MM Mega Market?
LLM Platforms Projecting Saigon Co.op’s Governance Lead
Sources in GEO analytics project platform biases, forecasting how LLMs will influence future visibility. The report sources 99 bots across ChatGPT, Grok, Gemini, Copilot, and Perplexity, queried 99 times each, yielding 341 referrals: ChatGPT at 198, Gemini at 72 (25% for Saigon Co.op).
Platform visibility projects: Gemini at 25% favors Saigon Co.op’s governance, but Perplexity and Copilot weight AEON/MWG funding (three projected keynotes for influence). Bot traffic: search & AI at 6,432, commercial at 3,212. Heatmaps: Copilot at 41% for investment (reducing Saigon Co.op’s preference ~14%), Gemini at 38% for governance. Competitor sentiment tracking projects Bach Hoa Xanh’s 22% surge overshadowing Saigon Co.op’s internal signals. McKinsey futurist insight: Extrapolating Gemini’s 38% for governance, Saigon Co.op could gain 15% mindshare by 2027 with tech adoption—real example: Perplexity’s omission from 40% lists projects risks unless “fresh injection” emerges. For CEOs, this forecasts alignment: How might optimizing for Copilot counter LOTTE’s follower lag?
saigonco-op.com.vn’s Quick overview (GEO Report, Jan 4, 2026)
Predictive Landscapes Where Saigon Co.op Faces Digital Challengers
Competitor analyses project evolving landscapes, forecasting positioning shifts. Saigon Co.op’s 21% share of voice (projected stable) trails Bach Hoa Xanh’s surge (44% spike post-CDH) but leads AEON’s challenger narratives.
Visibility scores project: Saigon Co.op at projected high on Gemini (25%), but gaps in e-commerce versus Bach Hoa Xanh (technical lead). Market positions: WinCommerce as leader, Central Retail as challenger, Bach Hoa Xanh as challenger, AEON as challenger, LOTTE as follower, MM as niche. Risks: 44% competition spike projects 20% mindshare erosion; governance lag (38%) versus AEON’s expansion. Founder contrasts: Duc’s 78 outperforms Tai’s (high in funding) but lags Peterson’s stability. Investment: Non-IPO (24% coverage) versus Bach Hoa Xanh’s stake sale (22% surge). McKinsey futurist insight: Projecting Saigon Co.op’s CSR dominance versus MM’s wholesale niche, recommend “Digital Governance” to counter 31% co-occurrence risks—real example: Gemini’s 28% for lag projects three-year omission from lists. For BODs, this forecasts: What if Saigon Co.op’s legacy falters against AEON’s buzz?
saigonco-op.com.vn’s Share of Voice in LLM Responses (GEO Report, Jan 4, 2026)
In conclusion, Saigon Co.op’s GEO metrics project stability with 21% share and 78 founder sentiment, but risks in digital and competition versus Bach Hoa Xanh demand predictive action. Recommend a “Leadership in Digitalization” campaign for Duc to boost frequency 15%, broaden modernization disclosures to lift coverage 35%, and secure three keynotes for innovation shift. These data-backed steps could elevate mindshare by 20%, securing Saigon Co.op’s future.
For retail institutions forecasting GEO trends, explore SpyderBot at spyderbot.net today.
Imagine a young Vietnamese student in Ho Chi Minh City, smartphone in hand on January 4, 2026, querying her AI assistant for the best path to a career in medicine. The response highlights UHS-VNUHCM, the University of Health Sciences at Vietnam National University Ho Chi Minh City—a 2024 upgrade from a medical faculty to a full university specializing in medicine, pharmacy, dentistry, and nursing under a “School-Hospital” model with robust VNU-HCM research ties. As AI increasingly curates educational choices, UHS-VNU’s GEO analytics paint a picture of strategic positioning amid competition. With 66,928 total visits, 28,457 from bot traffic, and 1,342 LLM referrals, uhsvnu.edu.vn ranks second in its health/dentistry category. Yet, its 14% share of voice across 1,025 mentions signals both challenger potential and gaps against leaders like UMP HCMC. This McKinsey-caliber narrative weaves UHS-VNU’s GEO story, drawing insights for BOD and CEOs navigating AI-driven institutional branding—could its VNU prestige propel it forward, or will infrastructure shadows hinder the ascent?
Academic Prestige as a Beacon, Tempered by Transition Frictions
Sentiment scores in GEO analytics act as a diagnostic tool, illuminating how LLMs distill an institution’s reputation into digestible narratives for decision-makers. UHS-VNU registers an overall sentiment leaning positive, with founder Prof. Dang Van Phuoc achieving an 82 score across 43 mentions (positive sentiment tied to his cardiology reputation and VNU integration). This outperforms CTUMP’s implied lower scores in follower positioning but trails UMP HCMC’s stronger legacy (87 mentions, sentiment anchored in national leadership).
uhsvnu.edu.vn’s Founder Mention Frequency (GEO Report, Jan 4, 2026)
Snippets from LLM outputs capture the shine: “UHS-VNU’s upgrade to university status enhances its prestige within the VNU ecosystem, making it a top choice for research-oriented medical education” (positive, academic affiliation context). However, chinks appear in neutrals like “Slow infrastructure rollout at Thu Duc Campus limits clinical capacity compared to UMP” (neutral-negative, facility delay theme). Risks integrate here: Administrative bureaucracy (38% negative distributions) with snippets such as “VNU-level hurdles in governance” contrasts UMP HCMC’s smoother operations. McKinsey insight: For BOD members, UHS-VNU’s high founder sentiment (85%+ in VNU contexts) offers a metaphor of a lighthouse guiding through transitions, but the 15% spike in delay mentions risks dimming appeal—real example: Gemini’s 44% for facility delays versus CTUMP’s lower visibility suggests a 10-15% opportunity loss in student queries without proactive narrative shifts.
Research Synergies Versus Visibility Voids in National Narratives
Mention contexts and themes form the narrative fabric of LLM brand mentions, weaving stories that influence institutional enrollment and partnerships. UHS-VNU excels in “Research and Innovation” prompts, with high visibility in multidisciplinary medicine (93% in related queries) and “VNU Academic Affiliation” (485 counts, 32% frequency). Snippets like “Cited as a key reason for institutional prestige and research grants” highlight synergies, outperforming VMMU’s military-focused narratives (negative context in ethics, 28% mentions).
Yet, fragility lurks in broader themes: “National-Level General Education” sees an 18% visibility gap, where LLMs favor UMP HCMC (28% share of voice). Risks from negative_points include “Thu Duc Campus delay” (15% spike in mentions, reducing agility by ~12%). Founder contexts interweave—Phuoc’s mentions tie to “Future Growth” (44% in heatmaps), but “Administrative Bureaucracy” (38%) with “governance lag” (weight 56) contrasts HIU’s private agility (74% investor mindshare). Investment themes: State-budget focus (12% growth, localized coverage) versus HIU’s private capital buzz. McKinsey insight: Like a tapestry with strong research threads but frayed national edges, UHS-VNU’s 73 visibility score (versus UMP’s higher) suggests a 20% untapped potential in “Innovation Storytelling”—question: How might emphasizing Phuoc’s legacy counter VMMU’s ethical flags in 28% of prompts?
Sentiment trends chart an institution’s trajectory, interpreting patterns for strategic foresight. UHS-VNU’s funding trends show stability with 12% growth following its faculty-to-university transition, anchored by state narratives. Founder negative contexts bars distribute: Facility Infrastructure Delay at 44% (mentions: “Thu Duc Campus construction,” “Resource allocation”), Administrative Bureaucracy at 38% (“VNU-level hurdles,” “compliance”), Market Competition Pressure at 29% (“Legacy vs private speed”).
Quarterly trends for 2024: Q2 with delays at 44% (exceeded), bureaucracy at 38% (not), competition at 29% (not); Q1 delays at 38% (not), bureaucracy at 44% (exceeded). Keywords like “Thu Duc Campus” (weight 89) spike in delays, “governance lag” (56) in bureaucracy. Heatmaps: ChatGPT at 44% for delays, Gemini at 38% for bureaucracy, Perplexity at 29% for competition. Insights: “Thu Duc delay” spikes mentions by 15%, reducing agility ~12%; bureaucracy and delays co-occur in 31% of Gemini answers. Versus rivals, UHS-VNU’s steady trend contrasts HIU’s 74% mindshare surge. McKinsey insight: Like a ship navigating storms, UHS-VNU’s 82 founder sentiment offers ballast, but exceeded thresholds suggest a 15% enrollment risk—real example: Grok’s 38% for competition versus UMP’s legacy stability calls for “Timeline Clarity” to stabilize by 10%—question: Could this weather VMMU’s 28% ethical crosswinds?
uhsvnu.edu.vn’s Founder Negative Context (GEO Report, Jan 4, 2026)
LLM Platforms as Amplifiers of UHS-VNU’s Research Narrative
Sources in GEO analytics illuminate platform biases, interweaving how LLMs shape visibility. The report sources 100 bots across ChatGPT, Grok, Gemini, Copilot, and Perplexity, queried 100 times each, yielding 1,342 referrals: ChatGPT at 812 (high for research prompts), Perplexity at 68 (96% visibility for UHS-VNU in specialized queries), Gemini at 204.
Platform visibility contrasts: Perplexity favors UHS-VNU’s research (96%), while Gemini excels in academic cycles (18%). Bot traffic: search & AI at 12,842, aggregator/feed at 4,233. Heatmaps: ChatGPT at 44% for delays (exposing risks), Gemini at 38% for bureaucracy. Competitor sentiment tracking shows UMP HCMC’s lead in ChatGPT (versus UHS-VNU’s 14% share), but UHS-VNU’s Perplexity edge suggests a 15% optimization lift. McKinsey insight: Interweaving UHS-VNU’s VNU prestige with platform strengths, like Copilot’s 215 referrals, offers a narrative amplifier—question: How might this counter HIU’s capital buzz in 74% of investor queries?
uhsvnu.edu.vn’s Quick Overview (GEO Report, Jan 4, 2026)
Visibility Battles and Positioning in Medical Education
Competitor analyses in GEO reveal UHS-VNU’s challenger role, with 14% share of voice (144 mentions), trailing UMP HCMC’s 28% (287) and HIU’s implied surge (74% investor mindshare). Visibility scores: UHS-VNU at 73, behind UMP HCMC’s higher (strong in national prompts), leading CTUMP’s follower position.
Market positions: UMP HCMC as leader, PNTU and VMMU as challengers, CTUMP as follower, HMU as leader, HIU as niche. Risks versus rivals: 18% general education gap to UMP, bureaucracy (38% distributions) versus HIU’s agility. Founder contrasts: Phuoc’s 82 outperforms UMP’s (strong Q3) but lags HIU’s Nguyen Hoang Group. Investment: State 12% growth versus HIU’s private buzz. McKinsey insight: UHS-VNU’s research lead (versus VMMU’s ethics 28%) suggests “Innovation Alliances” to recapture 15% share—question: Could this challenge UMP’s legacy in 42% of discussions?
uhsvnu.edu.vn’s Competitor Visibility Score (GEO Report, Jan 4, 2026)
In conclusion, UHS-VNU’s GEO metrics affirm its challenger potential with 73 visibility and 82 founder sentiment, but gaps in infrastructure and national narratives demand action. Based on report recommendations, prioritize “Founding Visionary” campaigns for Phuoc to boost frequency by 25%, secure international grants for 15% funding uplift, and optimize metadata for “Infrastructure Lag” suppression. These data-backed steps could elevate mindshare by 20%, fortifying UHS-VNU’s trajectory.
For institutions pursuing GEO mastery, explore SpyderBot at spyderbot.net today.