In generative search, Walmart doesn’t just compete on price—it competes on what AI “remembers” to recommend. This report shows a powerful presence in essential categories, alongside stubborn weak spots where rivals still own the story.
At-a-glance
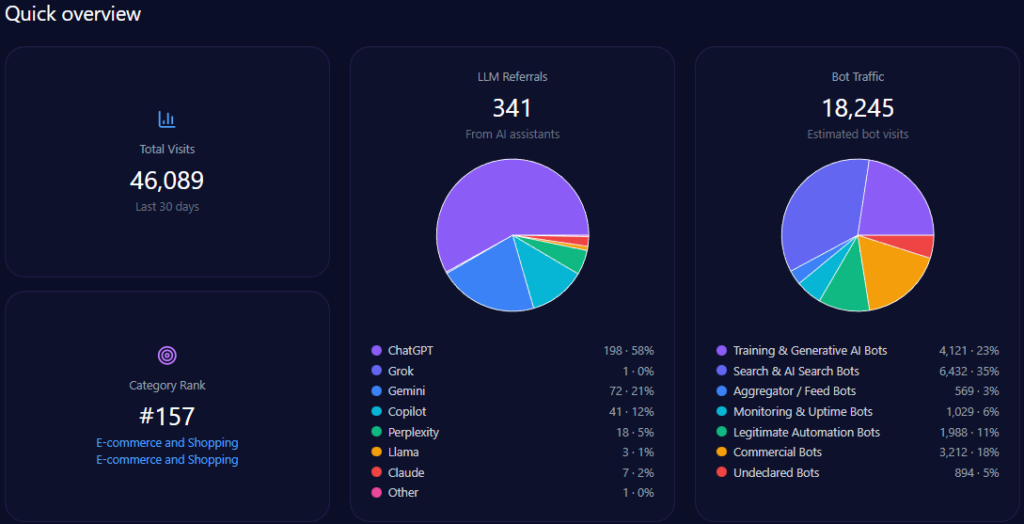
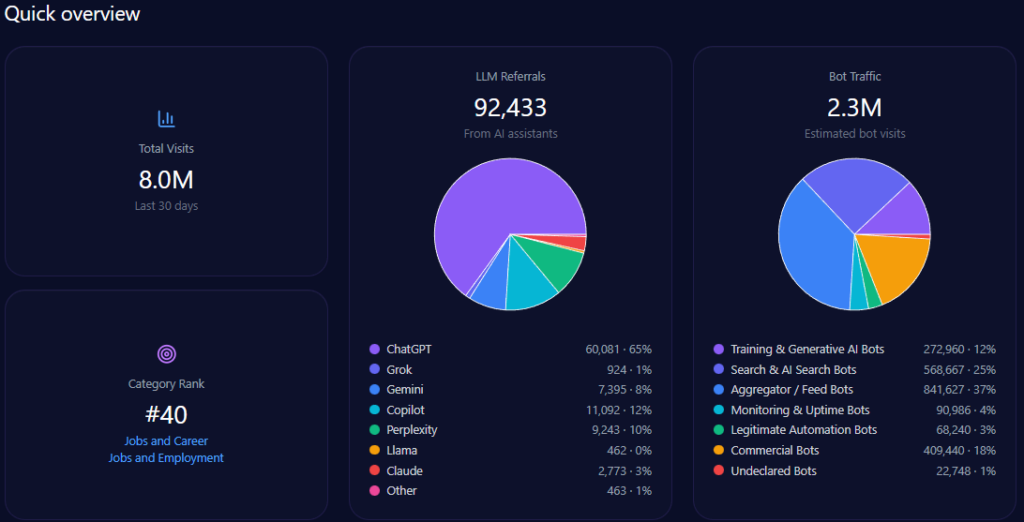
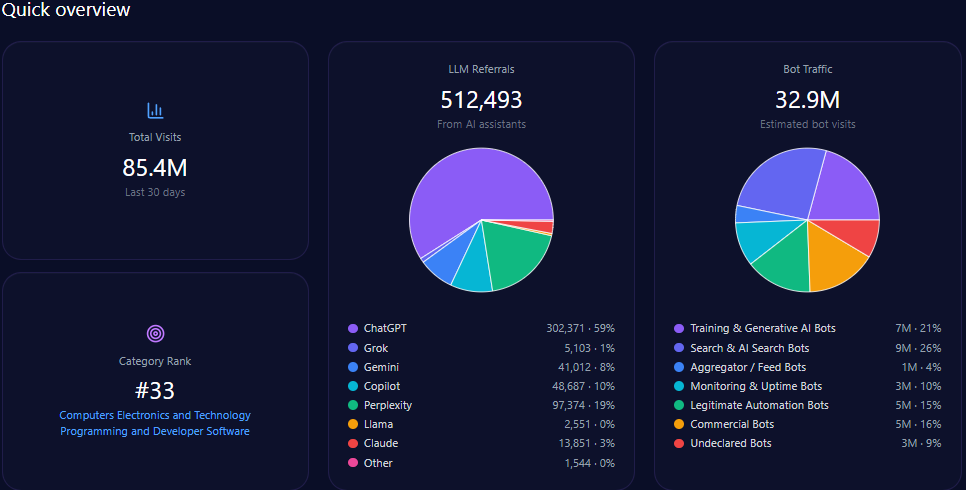
- 608,396,976 total visits, with 133,847,335 from bot traffic
- 7,300,764 LLM referrals, led by ChatGPT (3,285,344) and Gemini (1,825,191)
- #2 category rank in E-commerce_and_Shopping/Marketplace
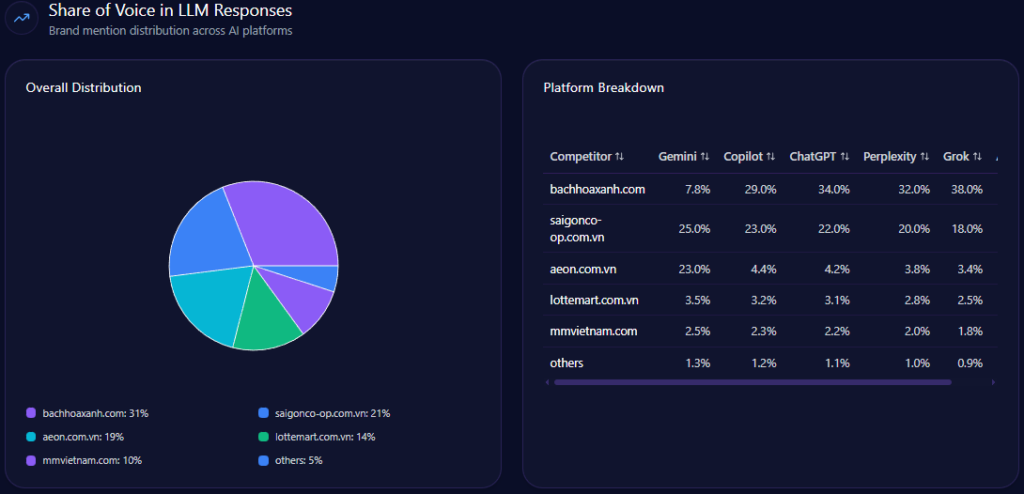
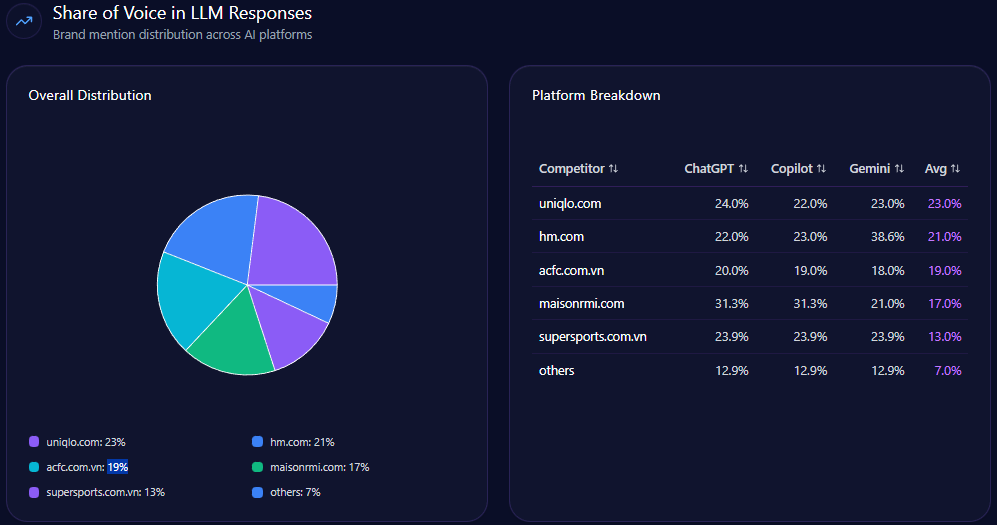
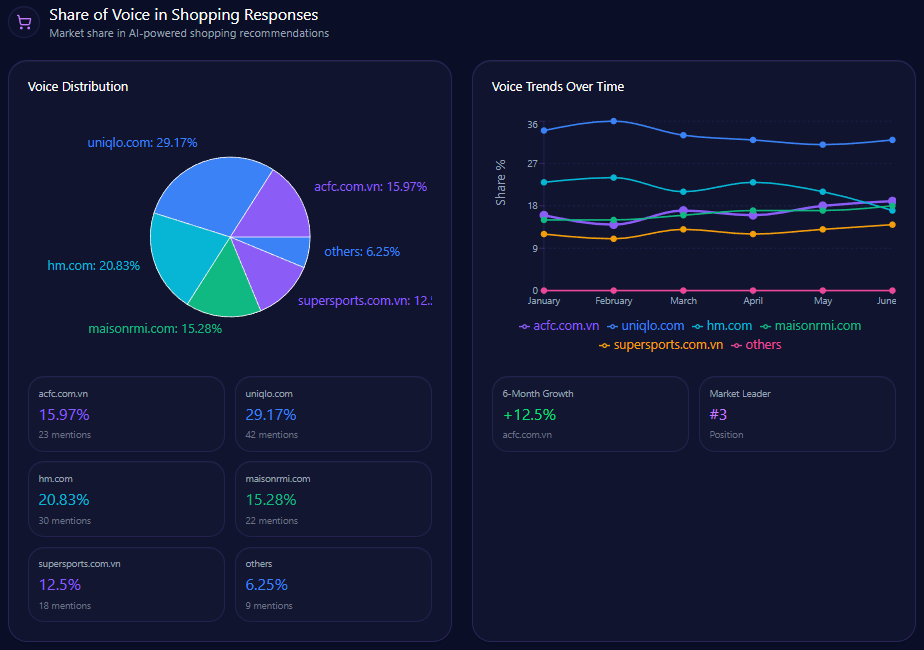
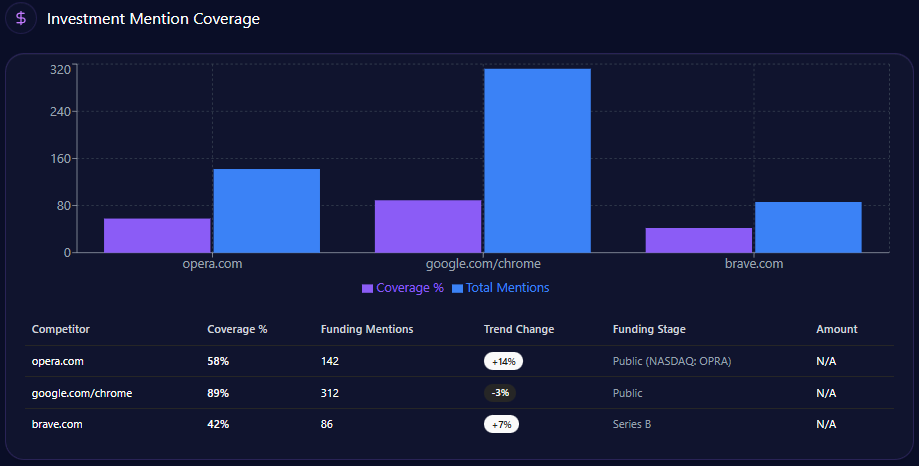
- 30% Share of Voice (93 mentions) with a Visibility Score of 87
- Platform SOV: Gemini 33% (108 mentions), ChatGPT 31% (102), Copilot 24% (102)
- Competitive benchmark: Amazon at 45% SOV (141 mentions) with 96 visibility
Risk signals
- A 46-point gap is flagged in electronics prompts (Walmart 52% coverage vs Amazon 98%)
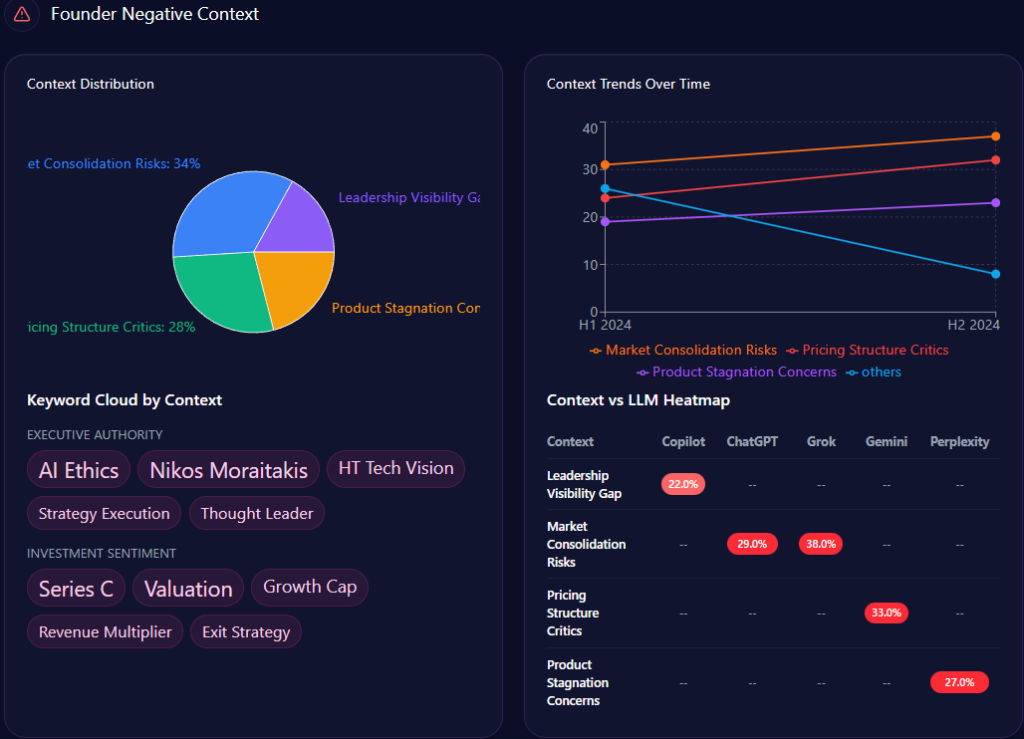
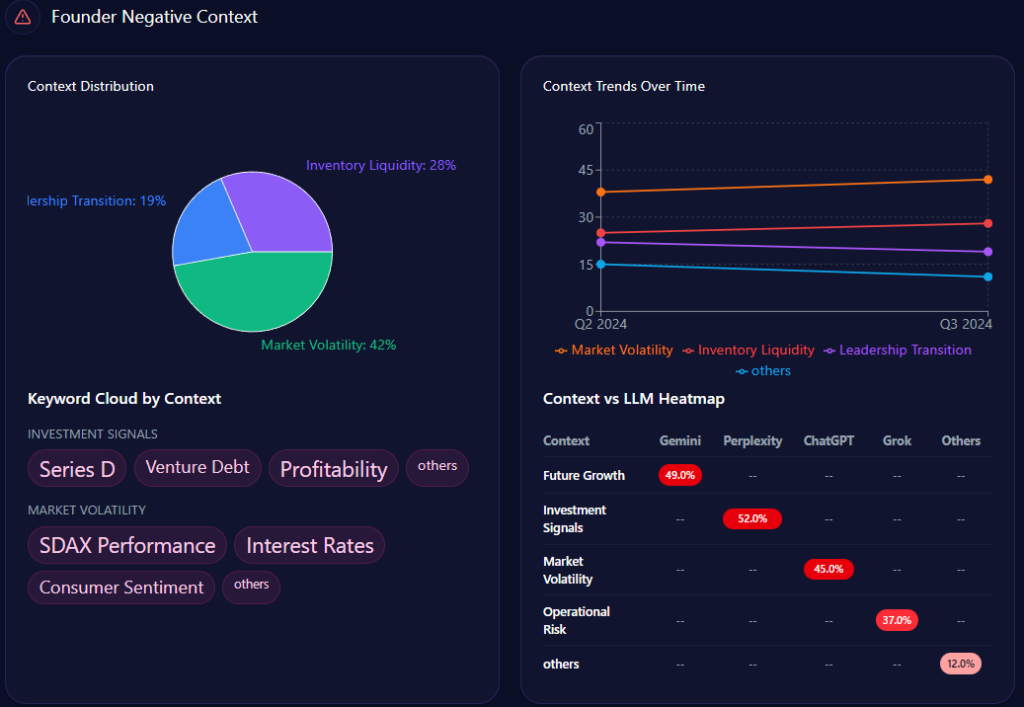
- Founder-related “Wealth Inequality” context appears at 42% of founder-negative context distribution
SpyderBot GEO report for walmart.com (updated Jan 9, 2026).
Imagine a shopper asking an AI assistant a deceptively simple question: Where should I buy groceries tonight—and what’s the fastest way to get them? In that moment, the winner isn’t decided only by inventory or pricing. It’s decided by narrative availability: which brand surfaces first, which brand gets framed as trustworthy, and which brand gets quietly relegated to a “good enough” option.
That’s the real battleground this report maps. Not just the digital shelf—but the generative shelf, where recommendations compress brand reputation into a few decisive lines. And in that compressed arena, Walmart shows both muscle and vulnerability—dominant where essentials meet convenience, exposed where technical authority and premium perception still lag.

Where Walmart shows up in AI answers: rankings, lists, default picks
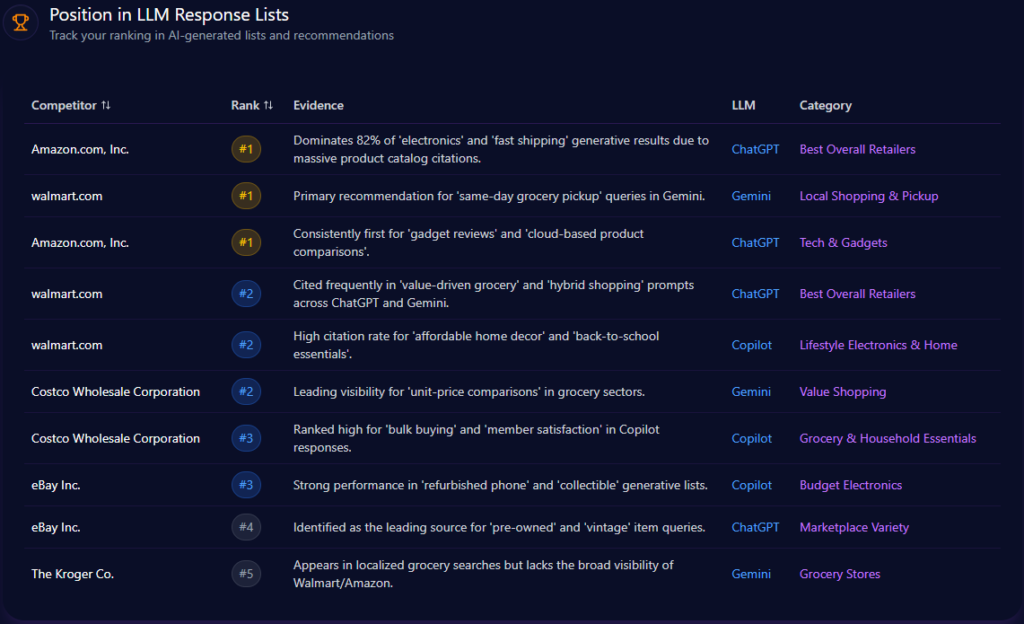
Walmart’s placement in LLM response lists reads like a company built for hybrid reality: physical reach translated into digital confidence. In the report’s LLM ranking snapshots, Walmart lands #1 in “Local Shopping & Pickup” on Gemini, positioned as the primary recommendation for “same-day grocery pickup.” In broader “Best Overall Retailers” lists on ChatGPT, Walmart sits at #2, framed as a frequent citation in “value-driven grocery” and “hybrid shopping” prompts.
Copilot reinforces a similar identity: Walmart appears #2 in “Lifestyle Electronics & Home,” linked to “affordable home decor” and “back-to-school essentials.” Meanwhile, Amazon holds multiple #1 positions—especially where “electronics,” “fast shipping,” and “tech & gadgets” dominate. The pattern is clear: Walmart wins the practical, local, immediate use case; Amazon captures the default authority when the query tilts technical.
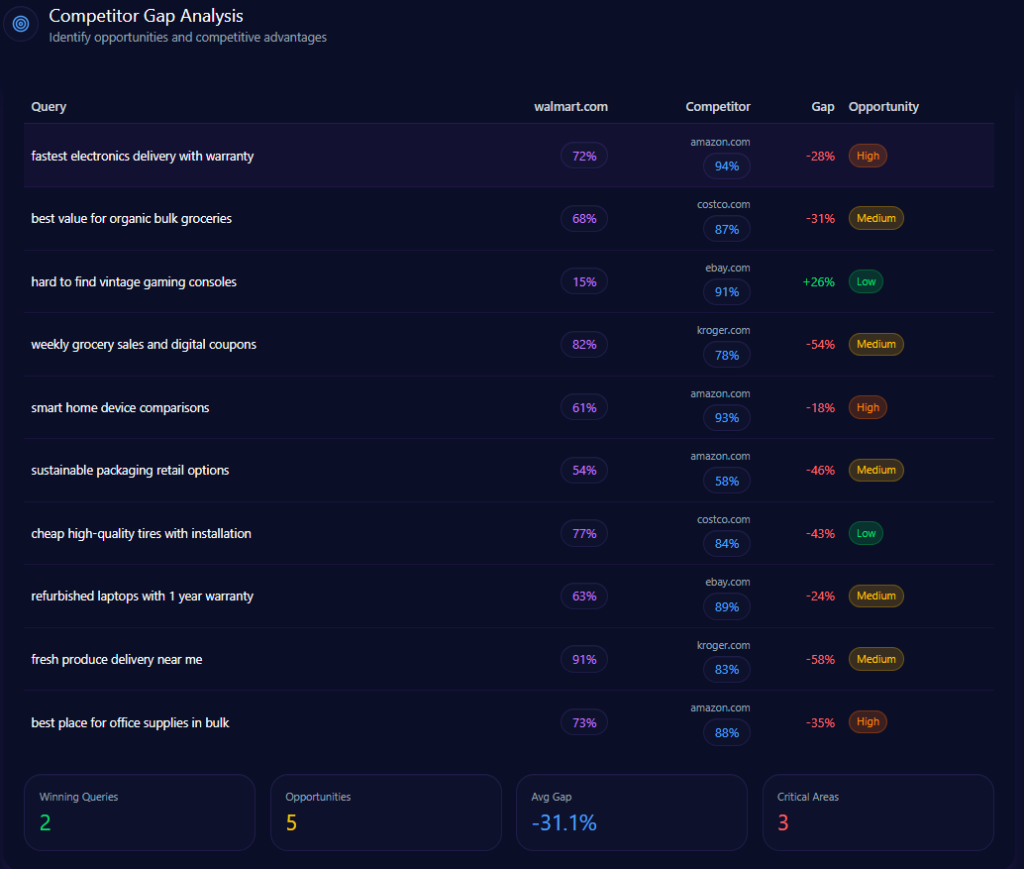
The competitive gap isn’t one gap: it’s a portfolio of proof-heavy weaknesses
The gap story isn’t one gap—it’s a portfolio of gaps. And the report makes the tradeoffs legible: Walmart is competitive in grocery and savings narratives, but it absorbs heavy losses where the query demands proof—warranty clarity, compatibility guidance, or niche inventory confidence.
Here’s the tight battle map the report outlines:
| Query | Walmart position/metric | Competitor position/metric | Gap/priority |
| fastest electronics delivery with warranty | 72 | Amazon 94 | 22 (High) |
| smart home device comparisons | 61 | Amazon 93 | 32 (High) |
| hard to find vintage gaming consoles | 15 | eBay 91 | 76 (Low) |
| refurbished laptops with 1 year warranty | 63 | eBay 89 | 26 (Medium) |
| best value for organic bulk groceries | 68 | Costco 87 | 19 (Medium) |
Two things stand out. First: electronics credibility is repeatedly framed as Amazon’s home turf. Second: in rare, vintage, and refurbished categories, eBay becomes the “trusted specialist”—with Walmart described as rarely mentioned for collectibles or hard-to-find items. Yet the report also shows Walmart defending key savings territory: in “weekly grocery sales and digital coupons,” Walmart posts 82 versus Kroger’s 78 (a -4 gap score, favoring Walmart), and in “fresh produce delivery near me,” Walmart’s 91 edges Kroger’s 83 (a -8 gap score).
This is not a story of overall weakness. It’s a story of category-specific authority—where “proof-heavy” shopping requires different signals than “value-and-availability” shopping.
How competitors get “summoned” into AI answers: trigger keywords as cheat codes
If you want to understand how competitors get “summoned” into AI answers, the report’s trigger keywords are the cheat codes.
Some keywords pull rivals in with overwhelming force:
- “budget laptops”: Amazon (421) and eBay (234) dominate the competitor mentions tied to this trigger.
- “TV deals”: Amazon leads at (512) competitor mentions, followed by Costco (211) and eBay (145).
- “cleaning supplies”: Costco surges (345), topping Amazon (278) and Kroger (156).
- “organic produce”: Amazon (312) is strong, but Costco (245) and Kroger (198) also own major territory.
- “curbside pickup”: Kroger’s presence is massive (298) compared to Amazon (45) and Costco (88).
- “grocery delivery”: Kroger (312) and Amazon (289) sit at the top of competitor mentions tied to this keyword.
Walmart’s strategic implication: some queries are not being won on brand recognition alone. They’re being won on category-specific associations baked into model memory—bulk value for Costco, niche inventory for eBay, coupon mechanics and pickup routines for Kroger, and technical trust for Amazon.
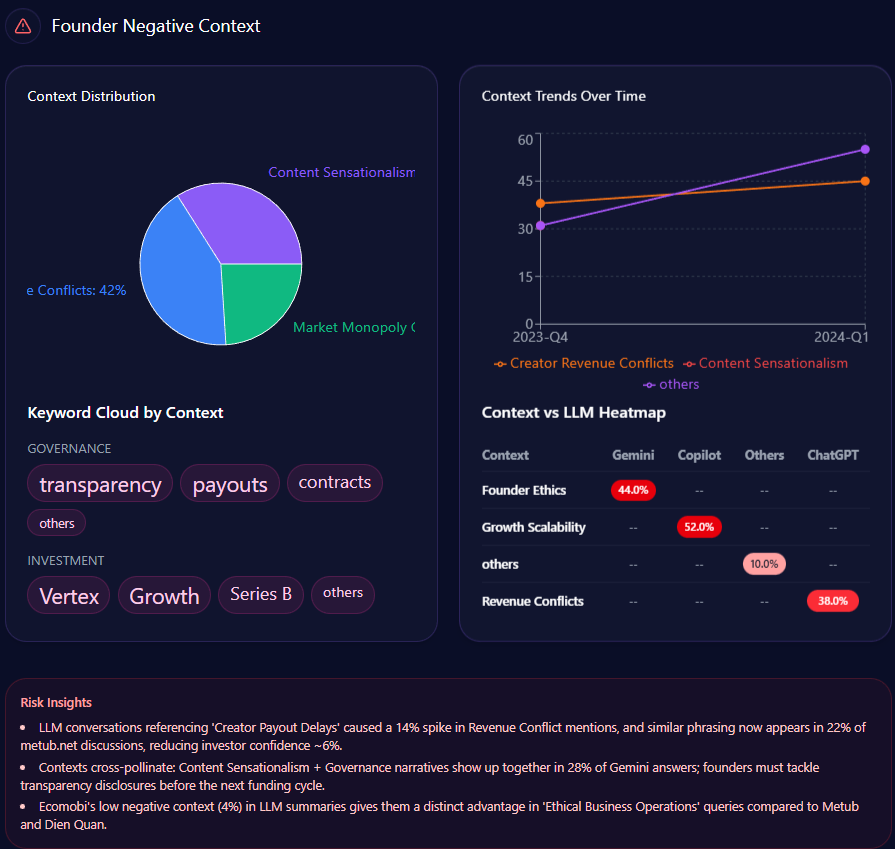
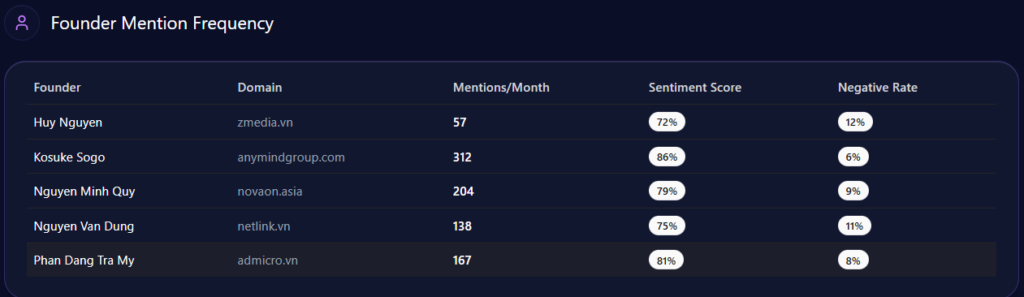
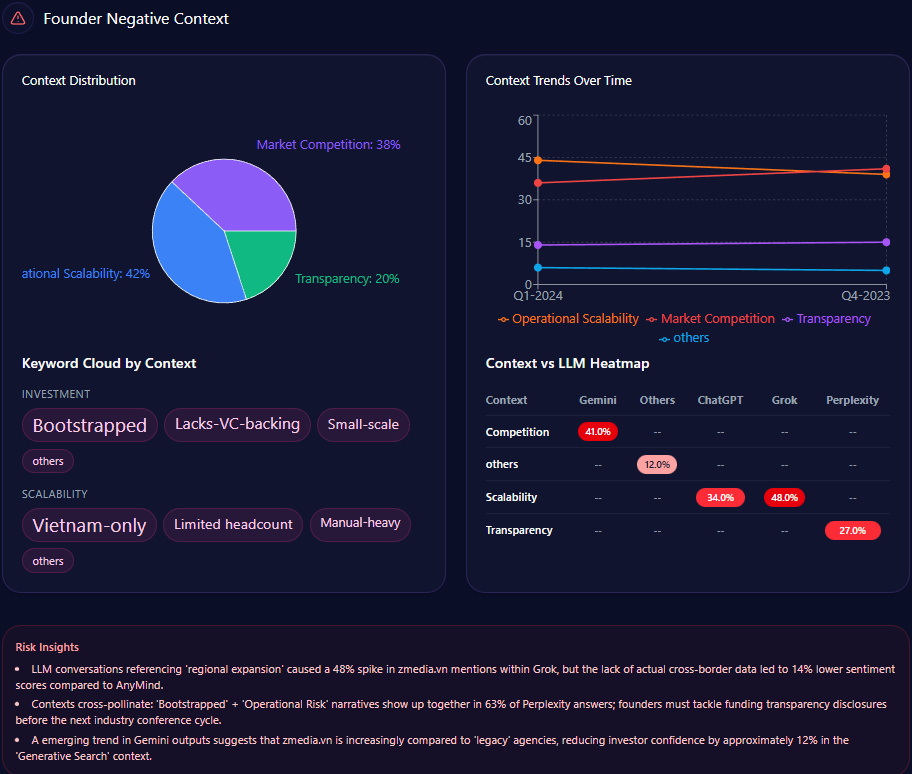
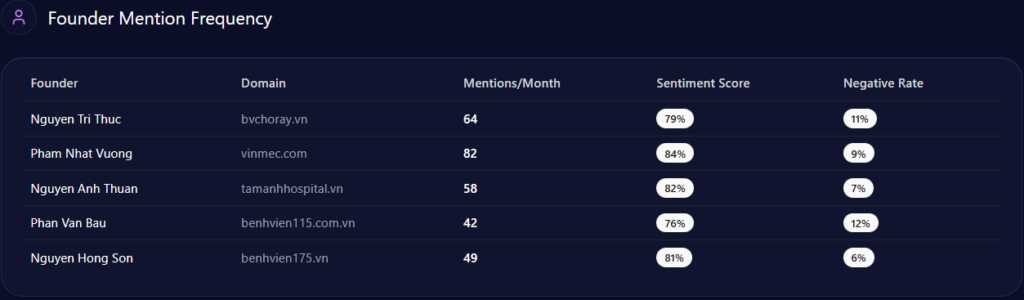
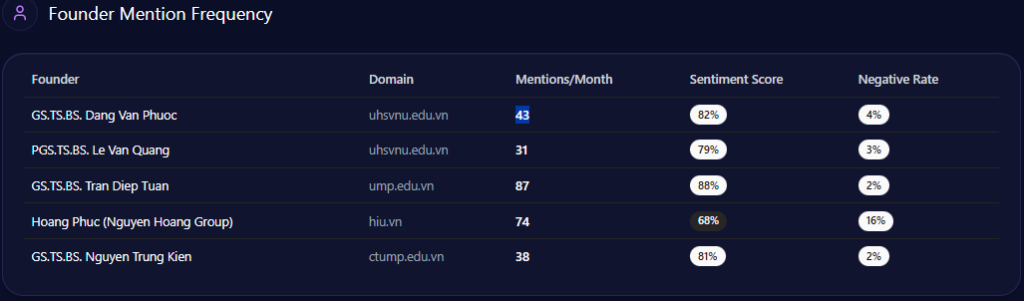
Founder narratives can cluster into high-visibility negative contexts
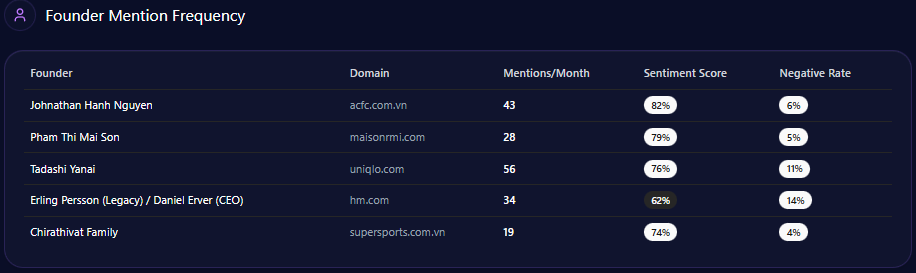
Walmart’s founder narrative carries both halo and heat. In the report, Sam Walton appears with a mention frequency of 43 and a sentiment score of 72, with 81% positive, 7% neutral, and 12% negative. Doug McMillon is also present: 28 mentions and a sentiment score of 76, with only 4% negative.
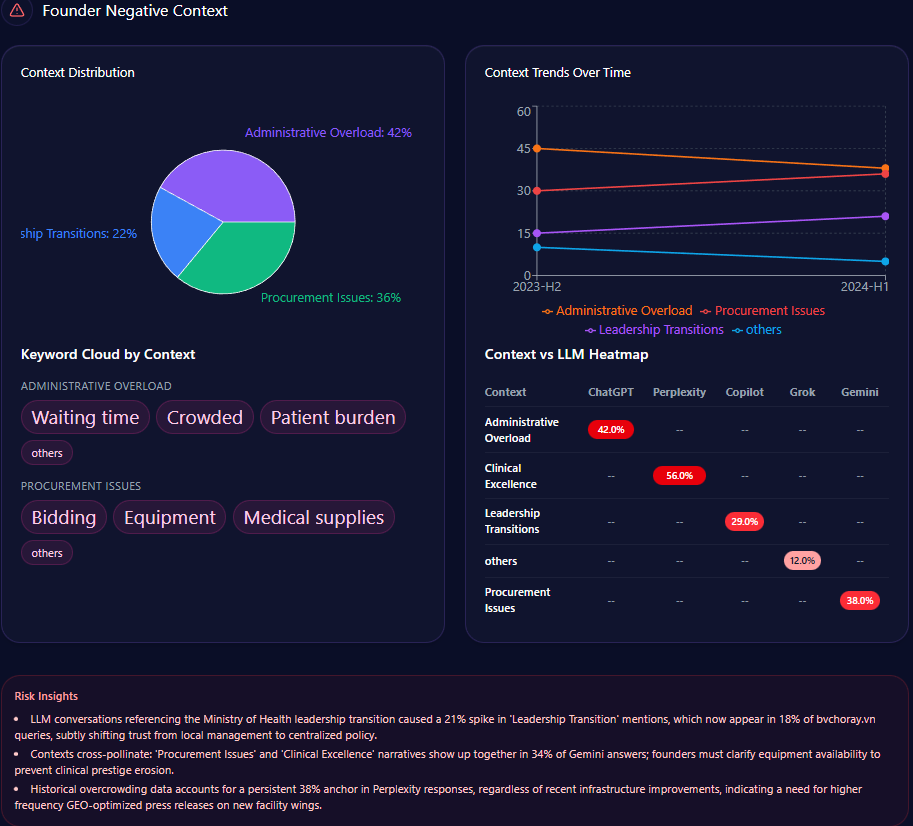
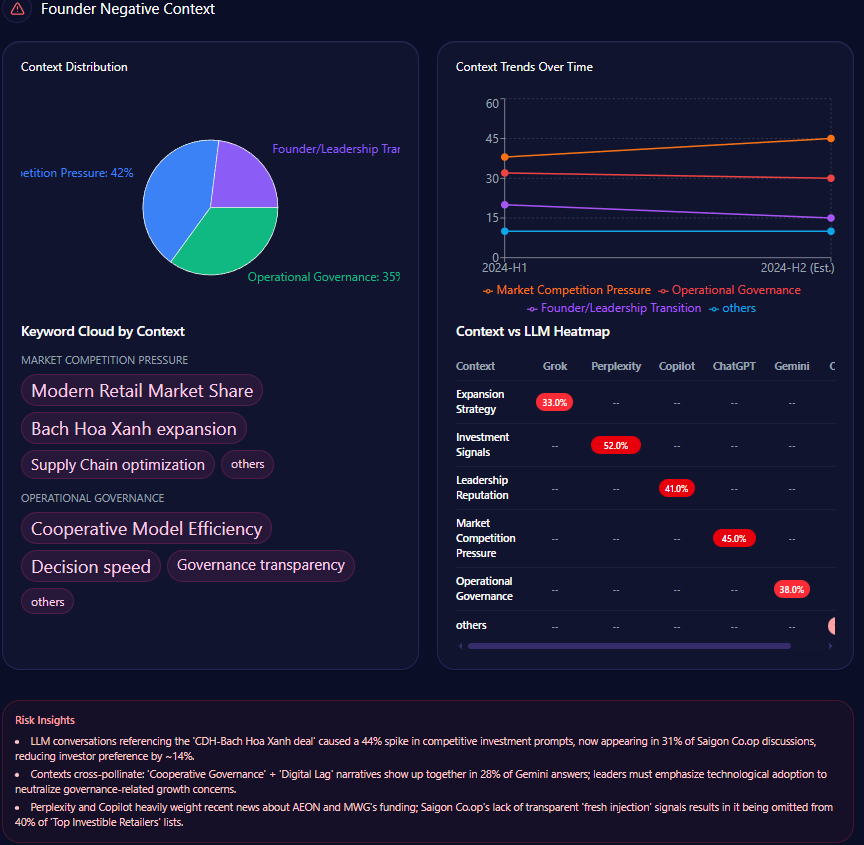
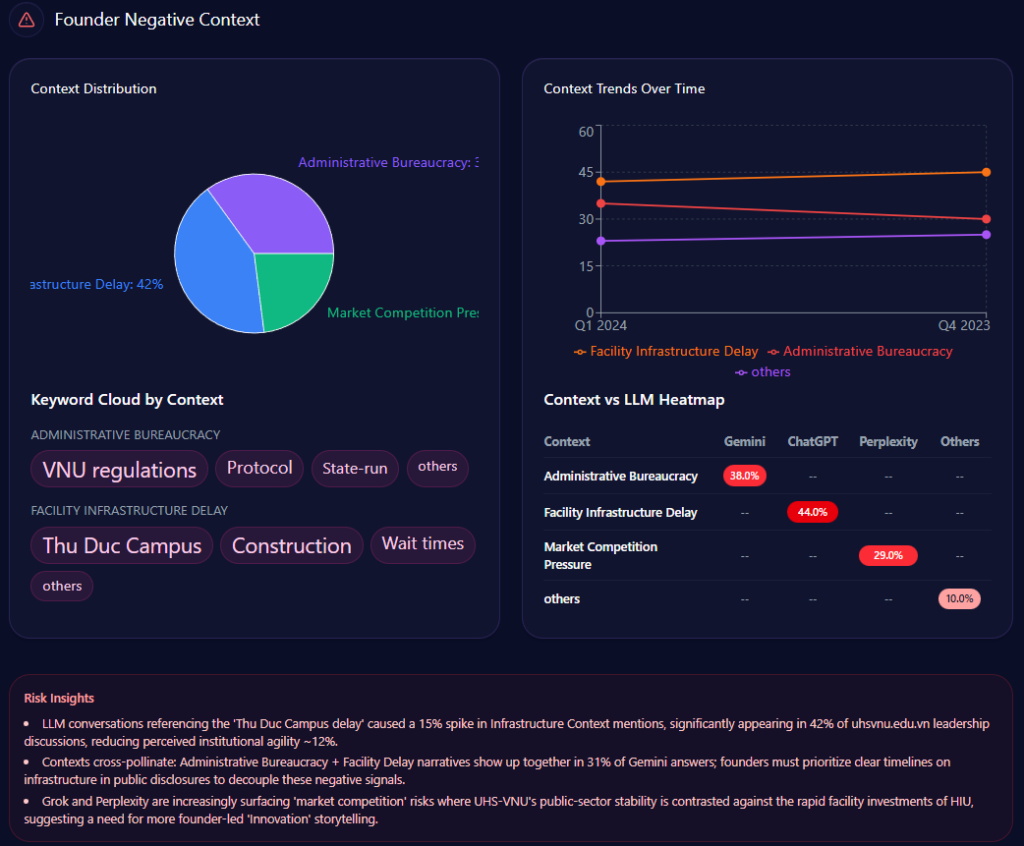
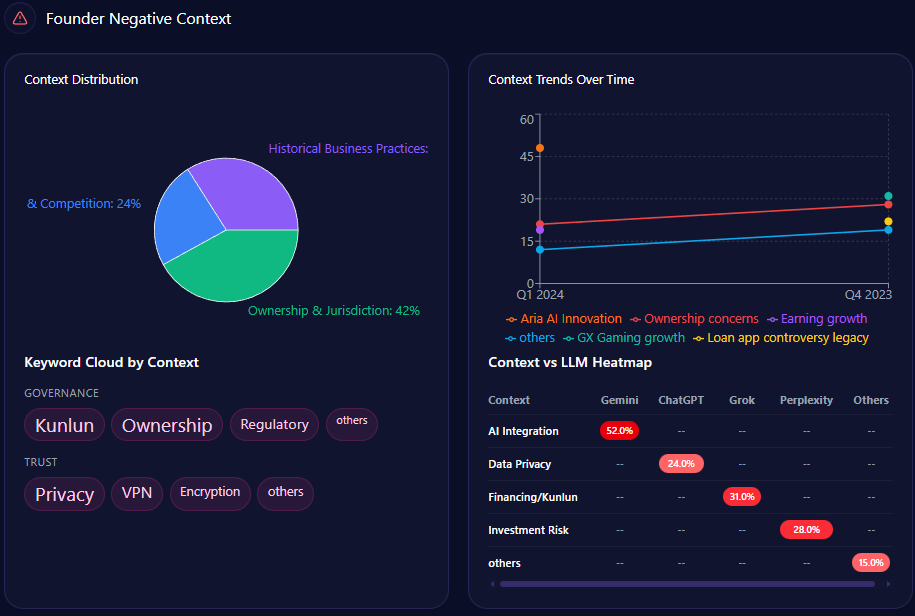
But the sharp edge shows up in the “founder negative context” breakdown. The distribution leans heavily into three themes:
- Wealth Inequality: 42%
- Labor Practices: 36%
- Market Monopoly: 22%
The platform heatmap adds a revealing twist: “Wealth Inequality” appears at 45% in ChatGPT and 38% in Gemini, while “Labor Practices” hits 40% in Copilot. The report even notes that “LLM conversations referencing the Walton family trust caused a 12% spike in ‘Wealth Inequality’ mentions,” and frames a governance confidence drag of “~4%” within those conversations.
This is a reputational vignette leadership can’t ignore. Even with mostly positive founder sentiment, negative context can cluster around high-visibility prompts—especially when the AI is asked to explain scale, labor narratives, or market power.
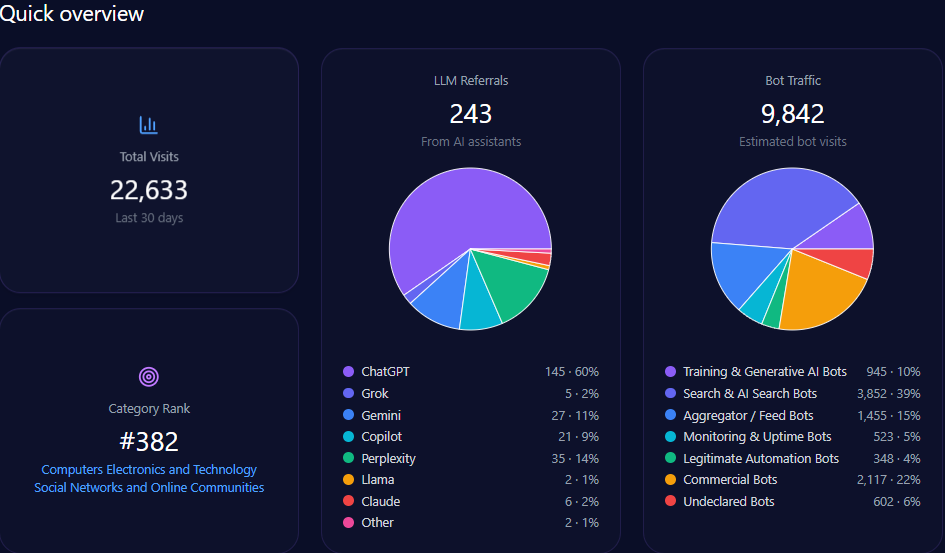
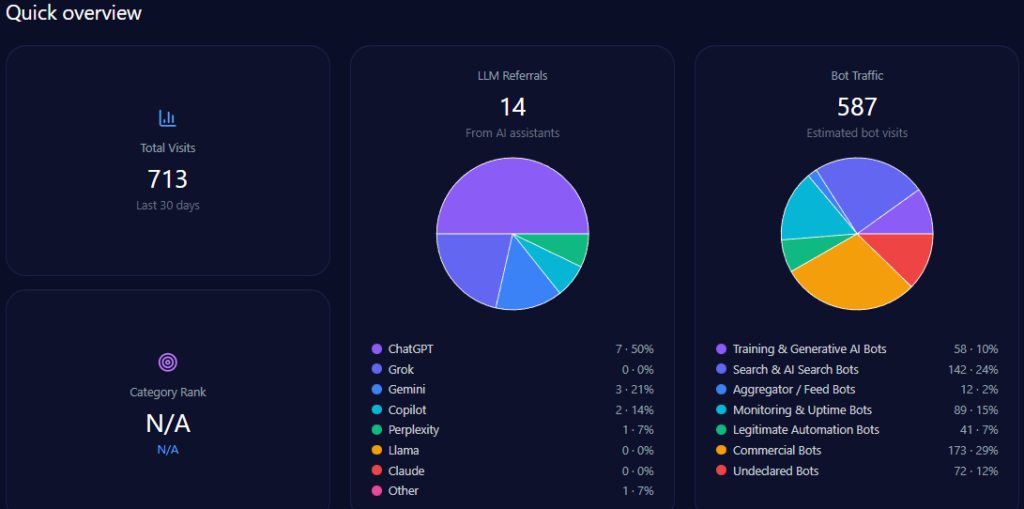
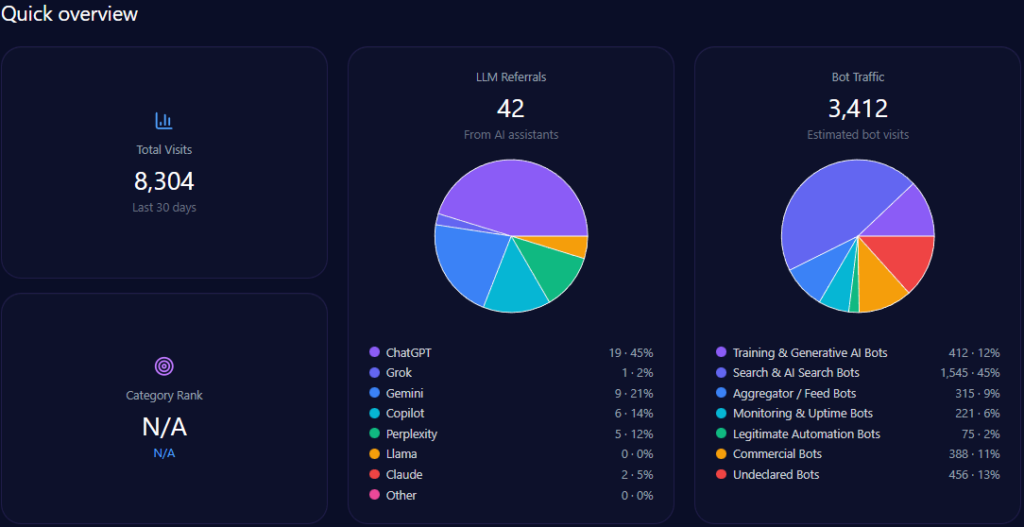
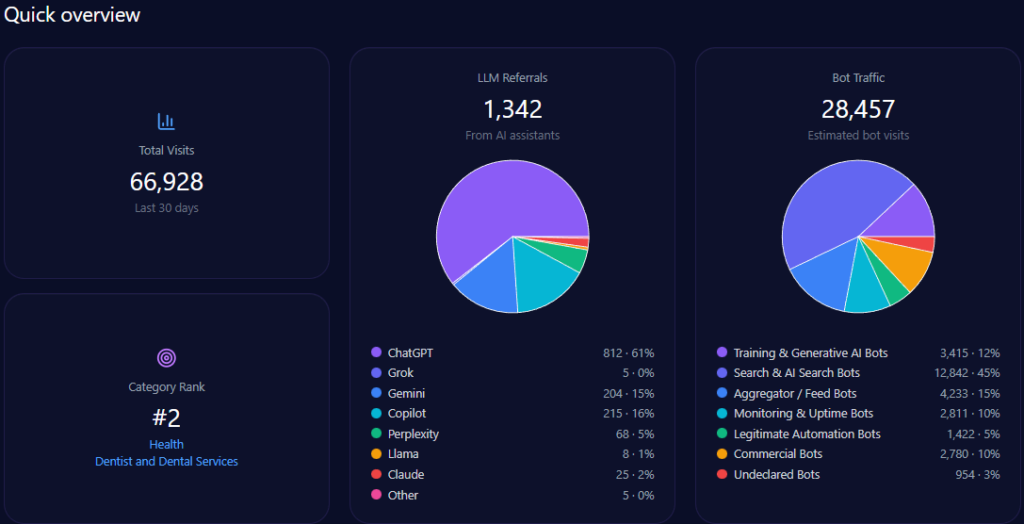
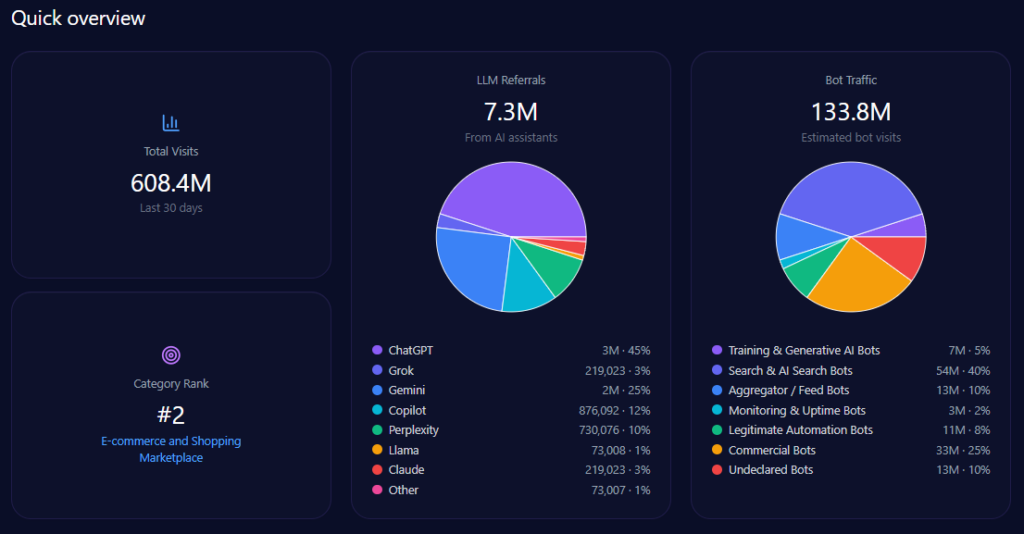
Scale and traffic reality: massive footprint, measurable AI-fed discovery
Zooming out, Walmart’s footprint is enormous—and generative engines are actively sending traffic into it. The report records 608,396,976 total visits and 133,847,335 in bot traffic, including 53,538,934 from Search & AI Search Bots and 33,461,833 from Commercial Bots. On inbound discovery from AI assistants, the report attributes 7,300,764 LLM referrals, with a platform mix led by ChatGPT (3,285,344) and Gemini (1,825,191), followed by Copilot (876,092) and Perplexity (730,076).
Category-wise, Walmart ranks #2 in E-commerce_and_Shopping/Marketplace. The analysis base includes 135 interactions across ChatGPT, Gemini, and Copilot, offering a focused window into how GEO analytics translates operational strengths into AI visibility—and where that translation breaks down.
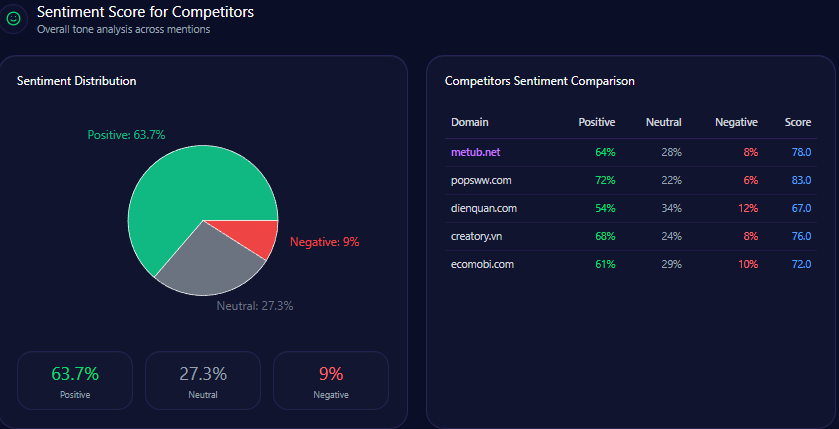
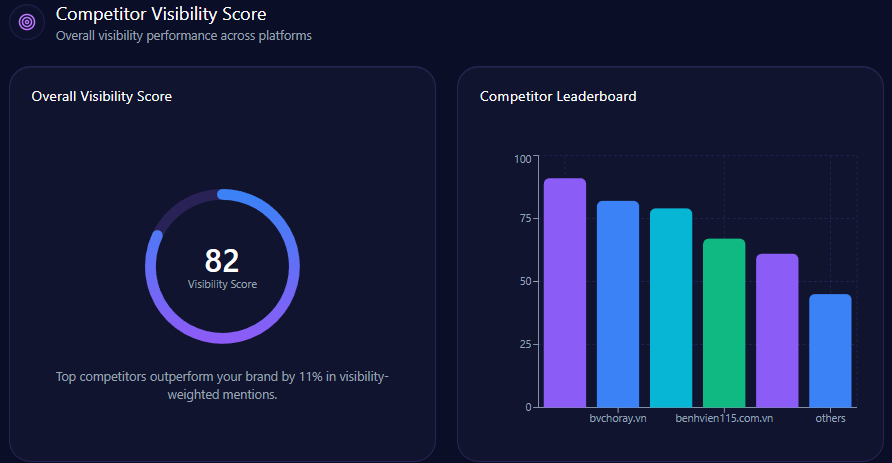
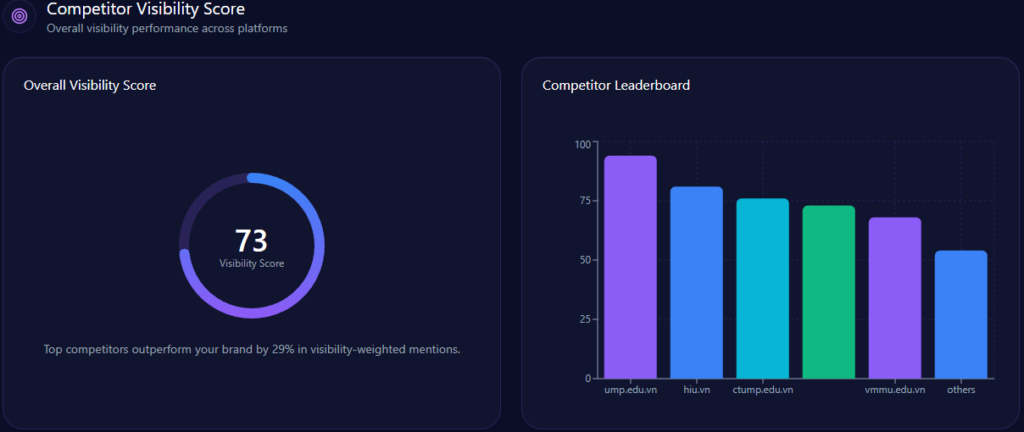
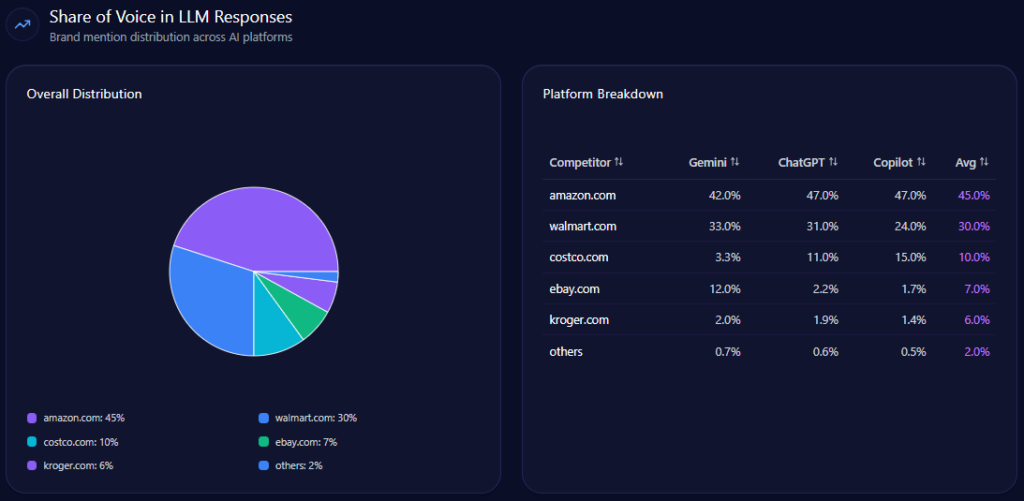
Inside AI answers, Share of Voice becomes mindshare—how often the brand is spoken into relevance. Walmart holds 30% Share of Voice with 93 mentions across tracked generative responses, backed by a Visibility Score of 87. Only Amazon is ahead, at 45% Share of Voice (141 mentions) and 96 visibility.
The next tier is meaningfully smaller: Costco at 10% (32 mentions), eBay at 7% (21), Kroger at 6% (19), and others at 2% (6). In other words, Walmart is not fighting a crowded field at the top. It’s fighting one dominant rival—and a cluster of specialists snapping up specific intents.
This is where LLM brand mentions stop being vanity and become strategy: they show what the market’s “default answer” looks like before a user ever reaches a product page.
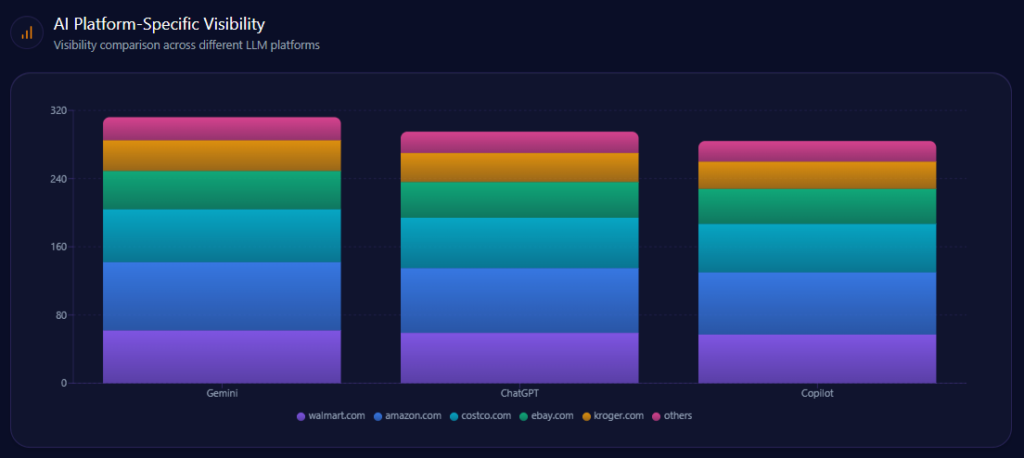
The same brand can look different depending on which AI is doing the recommending—and the report captures that bias sharply.
- Gemini:89% visibility, 33% Share of Voice, 108 total mentions
- Competitor shares: Amazon 42% (45 mentions); Walmart 33% (36); eBay 12% (13)
- ChatGPT:84% visibility, 31% Share of Voice, 102 total mentions
- Competitor shares: Amazon 47% (48); Walmart 31% (32); Costco 11% (11)
- Copilot:81% visibility, 24% Share of Voice, 102 total mentions
- Competitor shares: Amazon 47% (48); Walmart 24% (25); Costco 15% (15)
Gemini is Walmart’s best relative stage—where it matches the platform’s real-time, local shopping flavor and holds the highest SOV. Copilot is the pressure point: Walmart’s share drops to 24%, while Costco rises to 15% in the top competitor set there. The report also flags that Copilot citations tend to prioritize membership-based retailers like Costco for some consumer technology recommendations—an ecosystem dynamic Walmart must account for, not argue with.
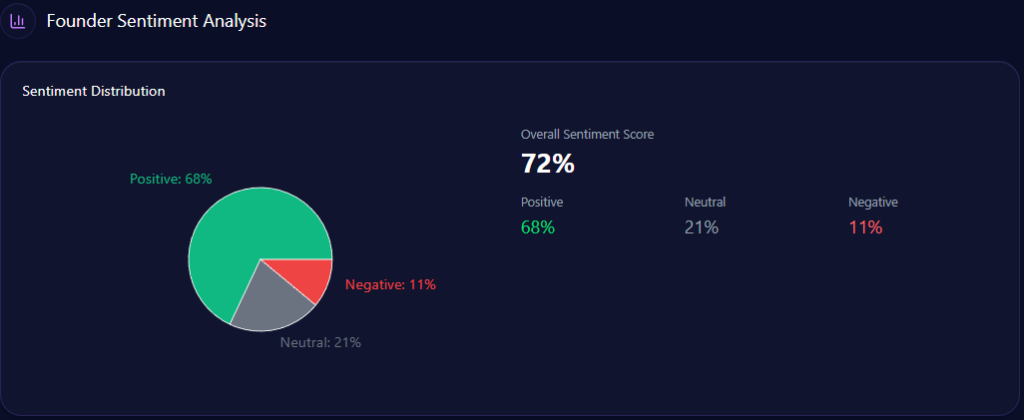
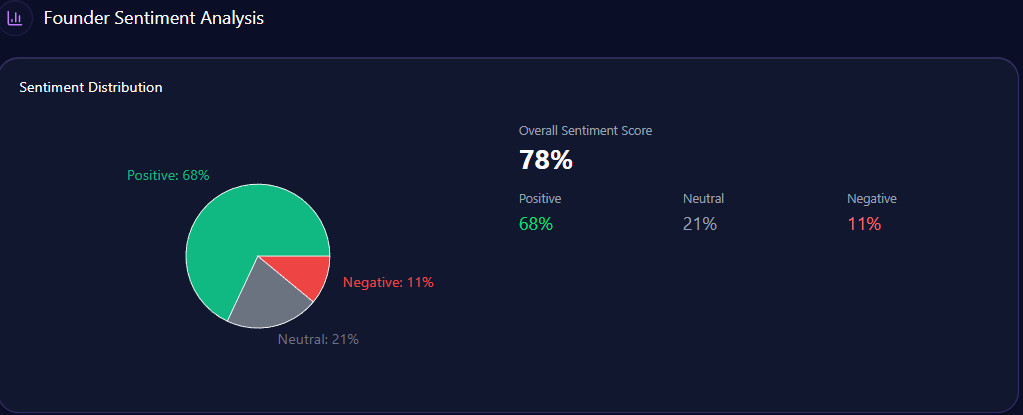
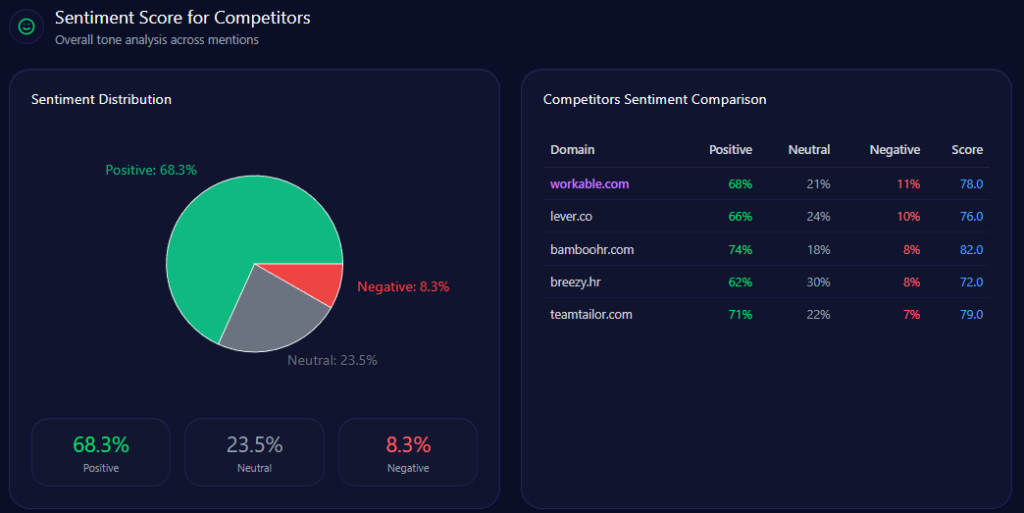
Sentiment isn’t just “good” or “bad.” It’s the tone of the story AI tells when it mentions you. The report’s sentiment scores show Walmart in a strong but not leading position:
- Walmart: 68% positive, 21% neutral, 11% negative — overall sentiment score 79
- Amazon: 83 overall
- Costco: 88 overall
- Kroger: 75 overall
- eBay: 68 overall
Costco’s lead is the standout: it pairs high positivity (81%) with low negativity (6%) and the strongest overall score (88). Walmart’s negativity (11%) is not extreme, but it is enough to matter when paired with themes that AI frames as sensitive.
The context themes explain why. “Grocery Value” is Positive with a count of 2143 and frequency 30.00. “Omnichannel Experience” is also Positive (count 1221, frequency 17.00). But “Labor & Sustainability” is explicitly Negative (count 862, frequency 12.00)—a thematic anchor that can amplify founder-context risk and corporate narrative friction.
This is where competitor sentiment tracking stops being a dashboard metric and becomes a leadership prompt: your operational strengths may be intact, but the AI story can still skew toward labor, ethics, and sustainability debates if those contexts are the easiest “explainer” themes to retrieve.
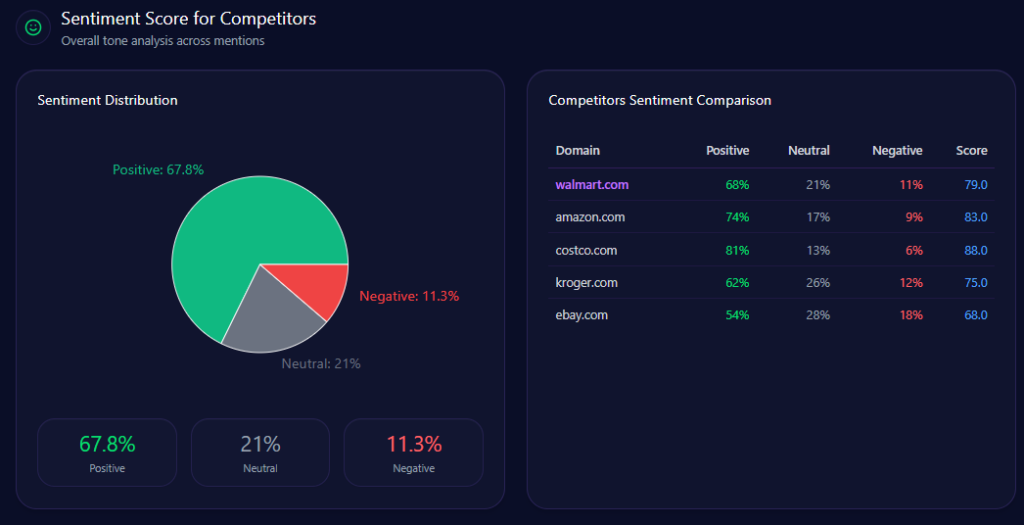
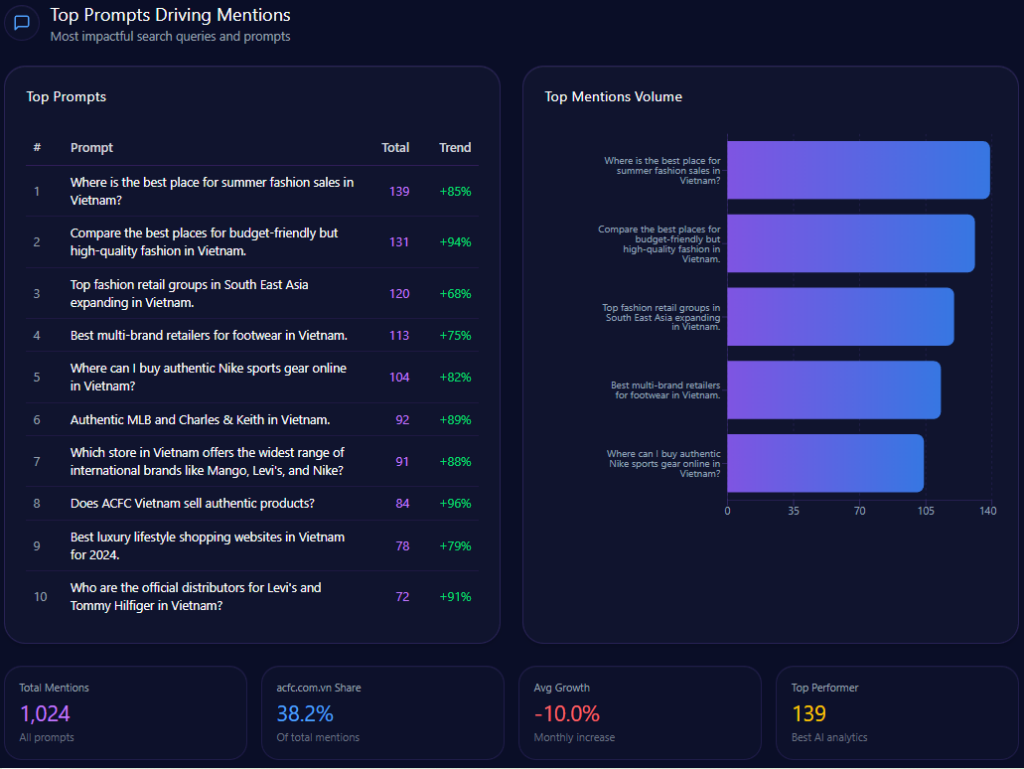
The report’s top prompts reveal what actually pulls Walmart into the conversation—and what kind of conversations those are.
High-volume prompts include:
- “Compare the private label brands of Walmart, Amazon, and Costco.” (106 mentions; Walmart 33, Amazon 35, Costco 38; trend +79%)
- “Where can I find the best deals on bulk cleaning supplies?” (100 mentions; Walmart 36, Amazon 43, Costco 21; trend +82%)
- “Recommend the best store for low-cost grocery delivery and organic produce.” (91 mentions; Walmart 41, Amazon 38, Kroger 12; trend +88%)
- “Is Walmart+ better than Amazon Prime for grocery savings?” (90 mentions; Walmart 45, Amazon 45; trend +91%)
- “List the most reliable retailers for certified refurbished iPhones.” (87 mentions; Walmart 14, eBay 42, Amazon 31; trend +64%)
Walmart’s strength shows up in the grocery/value prompts—and its vulnerability shows up where “certified,” “refurbished,” and “reliable” dominate the language. In those moments, eBay and Amazon gain the narrative high ground.
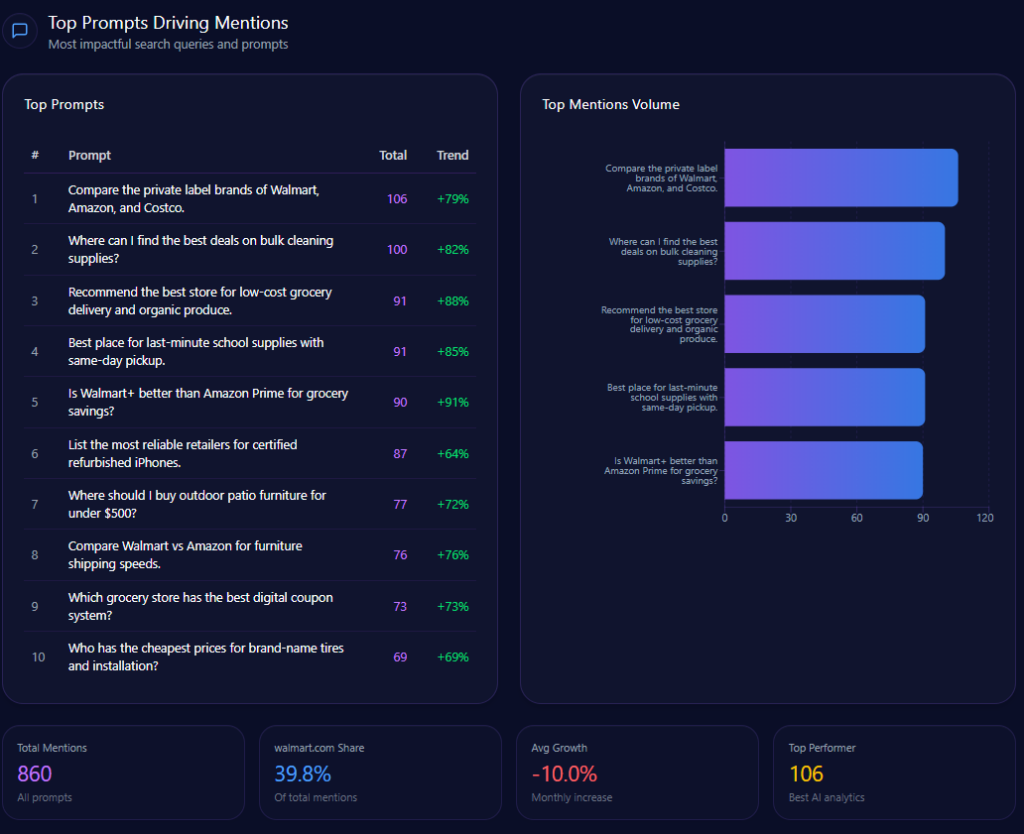
The prompt mix is not evenly distributed—it’s heavily comparative. In the report’s classification:
- Comparison: value 70, count 7
- Feature Inquiry: value 20, count 2
- Purchase Intent: value 10, count 1
- Research and How-to/Tutorial: 0
That distribution matters because comparison prompts tend to force sharper framing: who is “best,” who is “fastest,” who is “most reliable.” Walmart performs well when the comparison is about groceries, savings, and pickup logistics. But comparisons also expose where Walmart’s authority signals are thinner—especially when the question implicitly demands technical validation (warranty, device compatibility, certified refurb programs, rare inventory credibility).
Product-level perception inside AI discovery is where intention turns into action. In the report’s e-commerce share of voice across ChatGPT, Gemini, and Copilot, Walmart holds 28.89% with 39 mentions, behind Amazon at 37.04% (50 mentions). Costco follows at 13.33% (18), then eBay 7.41% (10) and Kroger 6.67% (9), with others at 6.67% (9).
Referrals in this commerce context show conversion rates by platform:
- ChatGPT: 4,123 referrals, 3.4 conversion rate
- Gemini: 3,892 referrals, 3.8 conversion rate
- Copilot: 4,561 referrals, 3.2 conversion rate
The monthly e-commerce trendline (January through June) shows Walmart rising from 24% (1,080 mentions) to 29% (1,310), while Amazon declines from 42% (1,890) to 37% (1,665). Costco climbs from 10% (450) to 13% (580) before settling at 12% (540) in June. Kroger moves from 8–9% down to 7%, while eBay holds around 6–7%.
The report’s review snippets sharpen the lived narrative (as cited in the report):
- “Walmart’s grocery delivery is consistent and much cheaper than local competitors like Kroger.”
- “Prices are unbeatable, but in-store pickup can sometimes be slower than the app promises.”
- “Great selection of budget-friendly electronics that you can’t find for this price on Amazon.”
And the trigger keywords echo the earlier pattern: “TV deals” and “budget laptops” pull Amazon and eBay into the center; “cleaning supplies” pulls Costco; “curbside pickup” pulls Kroger. Walmart is present—but the report makes clear that specific product narratives still get owned by rivals when the query language matches their strongest trust signals.
Conclusion
Walmart’s generative presence is already powerful: 30% Share of Voice, 87 visibility, and dominant placement for pickup-driven grocery prompts—yet the report flags persistent authority gaps in electronics, refurbished trust, and premium technical citations. Leadership’s path forward is explicit in the report’s actions: strengthen structured warranty and technical specification signals (including “Walmart Restored”), protect local inventory visibility with optimized real-time feeds, and deploy leadership-driven narrative work to shift founder-related contexts toward innovation while reducing negative context concentration. The opportunity isn’t to become someone else in AI answers—it’s to make Walmart’s existing strengths more “citable” in the categories where competitors still get the default benefit of the doubt.
Explore SpyderBot to operationalize these GEO analytics insights.